简介
假新闻可以利用多媒体内容对读者进行误导和传播,产生负面影响,甚至操纵公众事件,在社交媒体上如何识别新出现事件是否为假新闻是一个新的独特挑战。论文中提出了一个端到端的框架称为事件对抗神经网络(Event Adversarial Neural Network,EANN)基于多模态特征检测假新闻。受对抗网络的启发,EANN在训练阶段结合事件鉴别器来预测事件辅助标签,而相应的损失可以用来估计不同事件之间特征表示的不相似性。
EANN包括三个主要部分:多模态特征提取器、假新闻检测器和事件鉴别器。多模态特征提取器配合假新闻检测器完成假新闻识别的主要任务,同时多模态特征提取器试图欺骗事件识别器来学习事件不变量表示。使用卷积神经网络(CNN)从文章的文本和视觉内容中自动提取特征。
研究内容
模型总览
模型的目标是学习用于虚假新闻检测的可转移和可区分的特征表示,为了实现这一点,EANN模型集成了三个主要组件:多模态特征提取器、假新闻检测器和事件鉴别器,如图1所示:
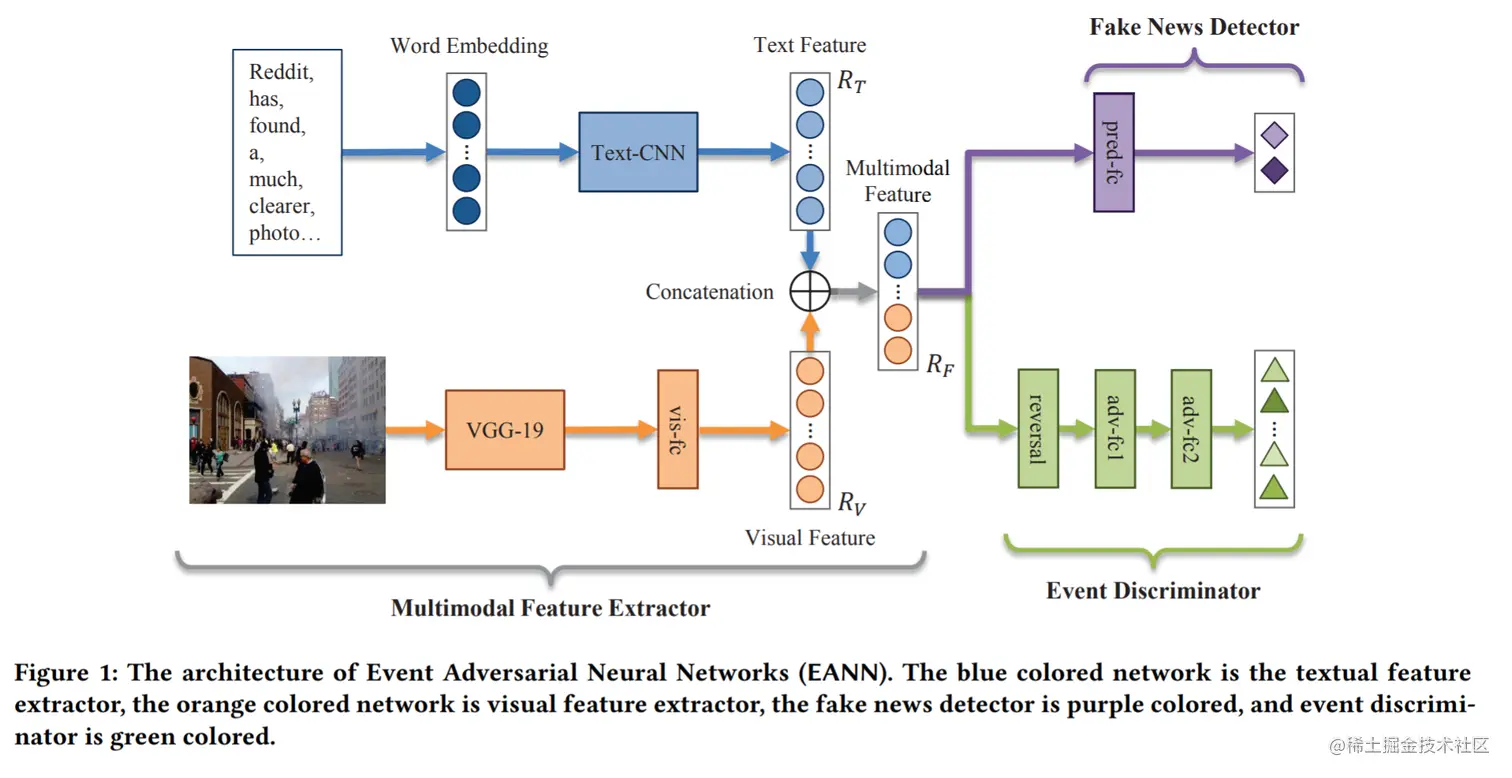
- 由于社交媒体上的帖子通常包含不同形式的信息(比如文本帖子和附加图片),使用多模态特征提取器(包括文本和视觉特征提取器)处理不同类型的输入。
- 在学习文本和视觉潜在特征表征之后,它们被连接在一起,形成最终的多模态特征表示,假新闻检测器和事件识别器都是建立在多模态特征提取器之上的。
- 假新闻检测器将学习到的特征表示作为输入,预测帖子的真伪。事件识别器根据这个潜在的表示来标识每个帖子的事件标签。
多模态特征提取器
文本特征提取
文本特征提取器的输入为文章中词的顺序列表,采用卷积神经网络(convolutional neural networks, CNN)作为文本特征提取器的核心模块。
如图1所示,一个修改的CNN模型称之为Text-CNN,其架构如图2所示,它利用不同窗口大小的多个过滤器捕捉不同粒度的特征来识别假新闻。
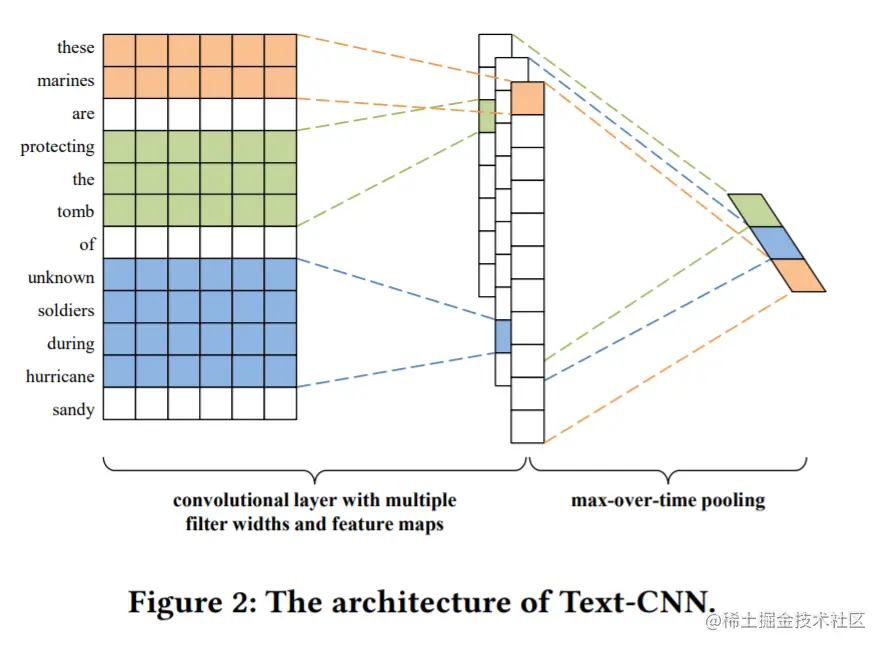
文本特征提取器的具体步骤是将文本中的每个词表示为一个词嵌入向量。句子中的第i个词对应的k维词嵌入向量可以表示为:Yi∈Rk,因此一个包含n个词的句子可以表示为:
T1:n=T1⊕T2⊕...⊕Tn
⊕表示向量的串联操作。窗口大小为h的卷积滤波器将句子中连续的h个单词序列作为输入,输出一个特征,以从第i个单词开始的连续h个单词序列为例,过滤操作可以表示为:
ti=σ(Wc⋅Ti:i+h−1)
其中,σ()为ReLU激活函数,Wc表示过滤器的权重。将操作应用到句子的所有词中,得到这个句子的特征向量:
t=[t1,...,tn−h+1]
对于t使用最大池化操作获得最大值,从而提取出最重要的信息。
为了提取不同粒度的文本特征,应用了不同的窗口大小。对于一个特定的窗口大小,有nh个不同的过滤器。假设有c种可能的窗口大小,总共有c×nh个过滤器。在最大池化操作后得到的文本特征可以表示为RTc∈Rc×nh,最终使用一个全连接层用来获得文本特征的最终表示(用RT∈Rp表示),并且通过下面的操作令文本特征与视觉特征表示拥有相同的维度(记为p):
RT=σ(Wtf⋅RTc)
Wtf是全连接层的权重矩阵。
视觉特征提取
视觉特征提取器的输入图片样本记为V,使用了预处理后的VGG19来提取视觉特征,在VGG19网络的最后一层之上,增加了一个全连接层,将最终的视觉特征表示的维度调整为p。定义p维视觉特征表示为RV∈Rp,视觉特征提取器中最后一层的操作可以表示为:
RV=σ(Wvf⋅RVvgg)
RVvgg为从预训练VGG19中获得的视觉特征表示,Wvf为视觉特征提取器中的全连接层权重。
文本特征RT和视觉特征RV将会被连接成为多模态特征表示,写作:
RF=RT⊕RV∈R2p
定义多模态特征提取器为Gf(M:θf),M为一组文本和视觉的帖子样本,是多模态特征提取器的输入,而θf表示学习参数。
假新闻检测器
假新闻检测器使用softmax部署一个全连接层来预测一个帖子内容的真假,其输入是多模态特征提取器的输出RF。定义假新闻检测器为:Gd(⋅;θd),θd表示所有参数。将假新闻检测器对第i个贴子的预测结果定义为mi,则该贴子为假新闻的概率为:
Pθ(mi)=Gd(Gf(mi;θf);θd)
使用Yd表示样本标签的集合,使用交叉熵计算预测损失:
Ld(θf,θd)=−E(m,y) (M,Yd)[ylog(Pθ(m))+(1−y)log(1−Pθ(m))]
通过寻找最优参数θf^,θd^来最小化损失函数。
假新闻检测的一个主要挑战来自于训练数据集没有涵盖的事件,这要求学习器能够学习新出现事件的可转移特征表示。然而直接最小化检测损失只能帮助检测训练数据集中包含的事件的假新闻,这样学习器只能获得事件特定的知识(例如,关键字)或模式,而我们需要使模型能够学习更多可以捕获所有事件中的公共特性的通用特性表示,这种表示应该拥有事件不变性,并且不包含任何特定于事件的特性。
为实现上述的目标,需要删除每个事件的唯一性,即:测量不同事件之间特征表示的不相似性,并删除它们,以捕获事件不变特征表示。
事件辨别器
事件鉴别器是由两个全连接层和相应的激活函数组成的神经网络,其目的是根据多模态特征表示将帖子正确分类为K种事件中的一个,将事件辨别器定义为Ge(RF;θe),θe表示其参数。用交叉熵定义事件判别器的损失:
Le(θf,θe)=−E(m,y) (M,Ye)[k=1∑k1[k=y]log(Ge(Gf(m;θf));θe)]
事件辨别器的目标是寻找参数θe^来最小化损失函数。
Le(θf,θe)用于估计不同事件分布的差异,较大的损失意味着不同事件表示的分布是相似的,学习到的特征是事件不变的。为了消除每个事件的唯一性,需要寻找参数θf^来最大化Le(θf,θe^)。
这就体现了网络的对抗性,一方面,多模态特征提取器试图愚弄事件辨别器,使辨别损失最大化,另一方面,事件辨别器的目的是发现特征表示中包含的事件特定信息,从而识别事件。
模型集成
在训练阶段中:
- 多模态特征提取器:Gf(⋅;θf),它需要结合新闻检测器Gd(⋅;θd)来最小化检测损失Ld(θf,θd)
- 多模态特征提取器:Gf(⋅;θf),尝试愚弄事件辨别器Ge(⋅;θe^)通过最大化事件辨别损失Le(θf,θe)来愚弄事件辨别器Ge(⋅;θe^)
- 事件辨别器Ge(RF;θe)基于多模态特征表示,在最小化事件识别损失的前提下,对每个事件进行识别。
综上所述,定义这场对抗的最终损失为:
Lfinal(θf,θd,θe)=Ld(θf,θd)−λLe(θf,θe)
λ控制假新闻检测目标函数与事件辨别目标函数之间的权衡(文中λ=1)。
对于优化参数,EANN尝试寻找最终目标函数的一个鞍点,即可能对于一个最优点:
(θf^,θd^)=argθf,θdminLfinal(θf,θd,θe^) θe^=argθemaxLfinal(θf^,θe)
通过随机梯度下降法来解决上面的问题。
这里采用了引入的梯度反转层(gradient reversal layer,GRL),梯度反转层在前向阶段起到恒等函数的作用,将梯度乘以−λ,然后将结果在反向传播阶段传递给上一层。在多模态特征提取器和事件辨别器之间可以方便地添加GRL,如图1所示的reversal layer。
θf←θf−η(∂θf∂Ld−λ∂θf∂Le)
为了稳定训练过程,用下述方式衰减学习速率η:
η′=fracη(1+α⋅p)β,α=10,β=0.75
p是一个对应训练进度从0到1的线性变化量。
事件对抗神经网络(EANN)的详细步骤总结在算法1中:



