
论文地址:arxiv.org/abs/2007.10…
论文代码:github.com/gabeur/mmt
1. 创新点
在传统的文字-视频检索领域丢弃了多模态信息,或者仅仅使用门控机制来处理某些维度信号。
因此提出了一种多模态Transformer,能够对视频中的不同模态进行联合编码,从而允许他们各自关注其他的模态。
2. 结论
作者介绍了一种多模态Transformer,它能够处理不同时刻提取的多个特征,以及从视频中的不同模态提取的多个特征。此外,作者还将视频编码器和字幕编码器馈入多模态融合框架进行视频-字幕匹配。
3. 解决问题
首要问题是解决如何学习文本和视频的精确表示,以建立相似性估计。
因为视频在外观上有所不同,而且在运动、音频、叠加文本。语音等方面也有所不同。利用好跨模态关系是构建有效视频表示的关键。
第二个问题是视频的时间性,因为难以处理视频的可变持续时间。
4. 实现方法
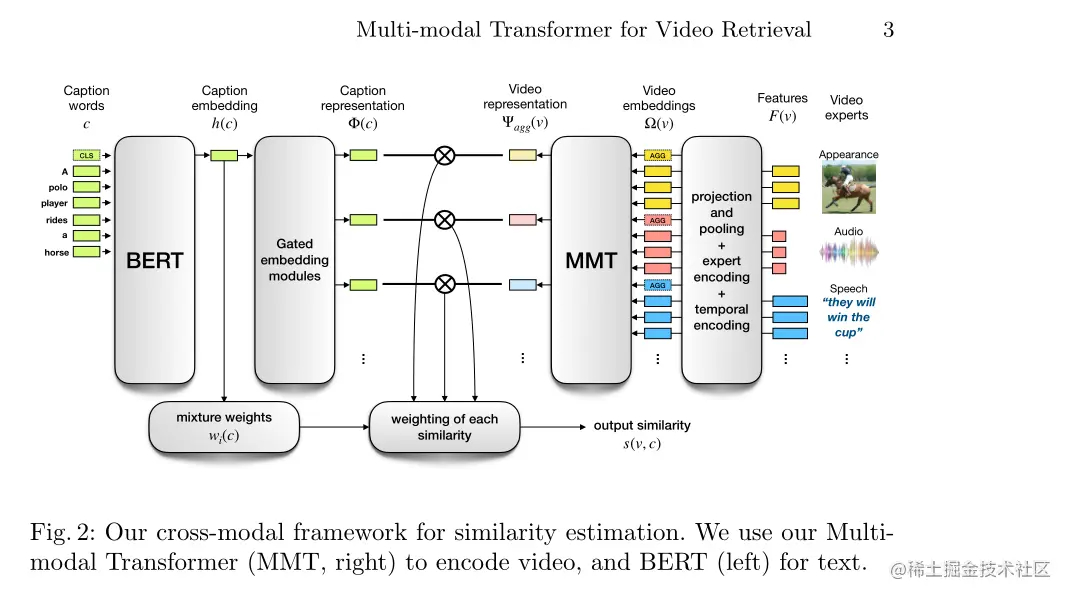 本文的总体方法可归纳为先用学习函数s计算视频和文本之间的相似度,然后根据文本到视频(或视频到文本)检索与查询文本(或视频)的相似性,对数据集中的所有视频(或文本)进行排序。
即对于给定的n个视频文本对{(v1,c1),(v2,c2),...,(vn,cn)},目标是学习视频和文本之间的相似性函数s(vi,cj).若i=j,则返回一个高的相似度值,反之返回相似度低的值。
本文的总体方法可归纳为先用学习函数s计算视频和文本之间的相似度,然后根据文本到视频(或视频到文本)检索与查询文本(或视频)的相似性,对数据集中的所有视频(或文本)进行排序。
即对于给定的n个视频文本对{(v1,c1),(v2,c2),...,(vn,cn)},目标是学习视频和文本之间的相似性函数s(vi,cj).若i=j,则返回一个高的相似度值,反之返回相似度低的值。
4.1 Video representation
视频级表示由本文提出的多模态Transformer(MMT)来计算。其为堆叠的自注意力层和全连接层组成。所有嵌入都具有相同的维度dmodel,每个特征都同时嵌入了特征的语义。模态和时间信息。
可以表示为:
Ω(v)=F(v)+E(v)+T(v)
Feature F
为了从视频总获得不同模态的信息,作者准备了n个预训练的“专家”{Fn}n=1N。(其实就是n个预训练好的特征提取网络),每个专家都是为特定任务训练的模型,然后用于从视频中提取特征。对于一个视频v,每个专家提取K个特征的序列Fn(v)=[F1n,F2n,...,FKn],每个“专家”Fn输出的维度为Rdn,为了统一作者通过N个FC层将Rdn投影到一个公共的维度dmodel中。
对于一个“专家”网络,会从视频中提取多个“embedding”,为了获得唯一的"embedding"并将视频上下文化,作者使用了最大池化聚合(max-pooling aggregation),得到Faggn=maxpool({Fkn}k=1K).然后,视频编码器的输入特征序列采用以下形式:
F(v)=[Fagg1,F11,...FK1,...FaggN,F1N,..,FKN]
Expert embedding E
为了处理跨模态信息,作者使用了n个dmodel的嵌入{E1,E2,...,En}用来区分不同专家的嵌入。表示为以下形式:
E(v)=[E1,E1,...,E1,...,En,En,...,En]
简而言之,E就是用来标定哪些F是属于同一个模态的。
Temporal embeddings T
考虑最大持续时间tmax秒的视频,作者学习了D=∣tmax∣个维度为dmodel的嵌入特征{T1,T2,,...,TD}.
在时间范围[t,t+1)内提取的每个专家特征将嵌入T_{t+1}。此外作者还学习了另外两个时间嵌入Tagg和Tunk,用来编码聚合特征和未知时态信息特征。视频编码器的时间嵌入序列采用以下形式:
T(v)=[Tagg,T1,...,TD,...Tagg,T1,...,TD]
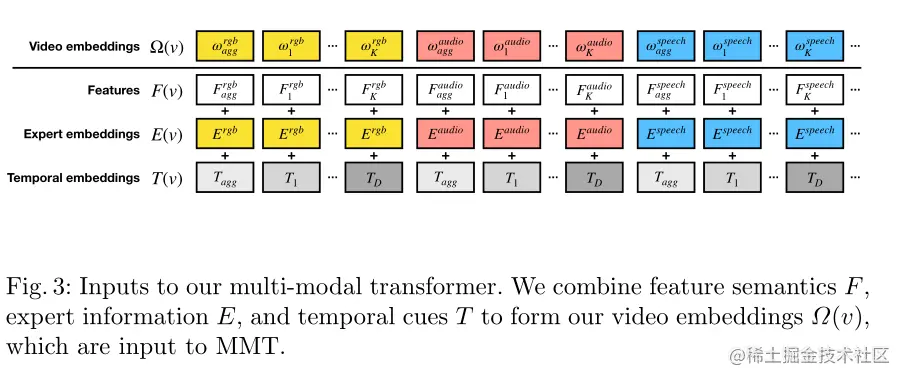 如上图所示,视频嵌入Ω(v)为feature、E和T嵌入的和,这个也是MMT的输入特征,即:
如上图所示,视频嵌入Ω(v)为feature、E和T嵌入的和,这个也是MMT的输入特征,即:
 与聚合门限机制相比,此方法有两个优势:
与聚合门限机制相比,此方法有两个优势:
- 输入嵌入不是简单地在一个步骤中进行调整,而是通过多个注意力头的几个层次进行迭代优化
- 作者提供了所有时刻的提取特征,以及一个描述从视频中提取特征时刻的时间编码。由于其自注意力模块,本文的多模态Transformer的每一层都能够处理所有输入嵌入,从而提取视频中发生的事件在多个模态上的语义
4.2 Caption representation
作者分为两个阶段用来计算文本表示Φ(c):
- 获得文本嵌入h(c)
- 然后将其投影到不同的空间。即Φ=g∘h,对于嵌入函数h,作者使用了预训练的BERT模型.
具体地说,作者从BERT的[CLS]输出中提取文本嵌入h(c),为了使文本表示的大小与视频的大小相匹配,学习的函数g可以作为多个门控嵌入模块,以匹配不同的视频专家。因此,文本嵌入可以表示为Φ(c)={ϕi}i=1N
最终的视频文本相似性s为每个专家视频文本相似性⟨ϕi,ψaggi⟩的加权和,如下所示:
s(v,c)=i=1∑Nwi(c)⟨ϕi,ψaggi⟩
其中wi(c)表示第i个专家的权重。这个权重由在文本表示h(c)上施加线性层,并用softmax实现:
wi(c)=∑j=1Neh(c)Tαjeh(c)Tαi
其中(a1,a2,...,aN)表示线性层权重。使用加权和的原因是,文本可能无法统一描述视频中的所有模态。例如,在一段视频中,一个穿着红色衣服的人正在唱歌剧,文本“一个穿着红色衣服的人”没有提供与音频相关的信息。相反,“有人在唱歌”的文本应该侧重于计算与音频模态的相似度。
4.3 Training



