1 要解决的问题:
MySQL处理多表关联的方式或者说性能不尽人意。
2 建议解决方案:
2.1 将join拆分,避免join可能带来的性能问题,同时也增加了程序和DB的网络交互。
2.2 join优化。【阿里mysql开发手册】
2.2.1 最好在三张表之内,最多不要超过5个,理论可以61个。
2.2.2 on关联字段类型要相同。
2.2.3 尽量利用小表驱动大表,可以减少循环嵌套次数。
3 join优化的原则:小表驱动大表
3.1 在Mysql中,使用Nested-Loop Join的算法思想去优化join,Nested-Loop Join翻译成中文则是“嵌套循环连接”。
3.2 在Mysql的实现中,Nested-Loop Join有3种实现的算法:
Simple Nested-Loop Join:SNLJ,简单嵌套循环连接
Index Nested-Loop Join:INLJ,索引嵌套循环连接
Block Nested-Loop Join:BNLJ,缓存块嵌套循环连接
3.2.1 Simple Nested-Loop
简单嵌套循环连接实际上就是简单粗暴的嵌套循环,如果table1有1万条数据,table2有1万条数据,那么数据比较的次数=1万 * 1万 =1亿次,这种查询效率会非常慢。
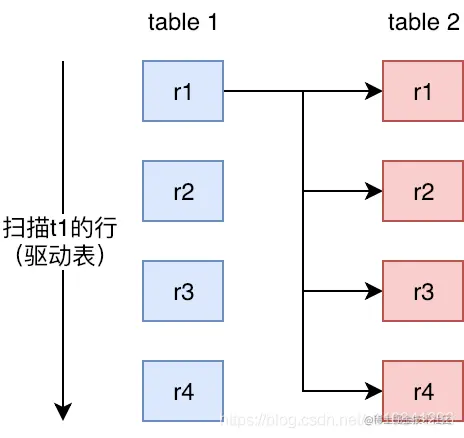
所以Mysql继续优化,然后衍生出Index Nested-LoopJoin、Block Nested-Loop Join两种NLJ算法。在执行join查询时mysql会根据情况选择两种之一进行join查询。
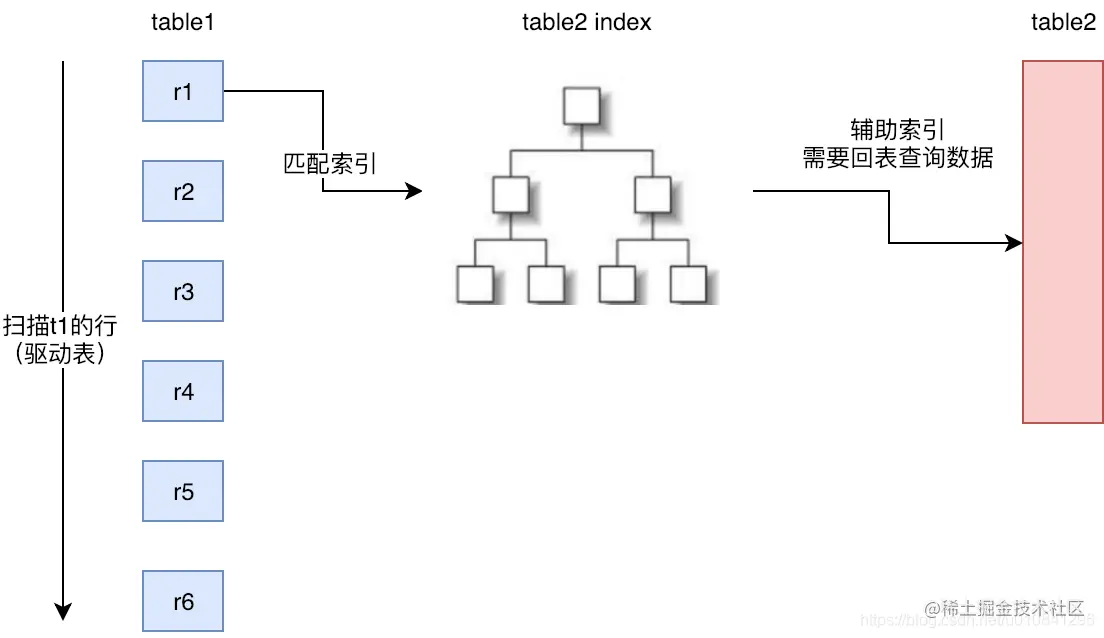
3.2.2 Index Nested-LoopJoin(减少内层表数据的匹配次数)
索引嵌套循环连接是基于索引进行连接的算法,索引是基于内层表的,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录进行比较, 从而利用索引的查询减少了对内层表的匹配次数,优势极大的提升了 join的性能:
原来的匹配次数 = 外层表行数 * 内层表行数
优化后的匹配次数= 外层表的行数 * 内层表索引的高度
使用场景:只有内层表join的列有索引时,才能用到Index Nested-LoopJoin进行连接。
由于用到索引,如果索引是辅助索引而且返回的数据还包括内层表的其他数据,则会回内层表查询数据,多了一些IO操作。
3.2.3Block Nested-Loop Join(减少内层表数据的循环次数)
缓存块嵌套循环连接通过一次性缓存多条数据,把参与查询的列缓存到Join Buffer 里,然后拿join buffer里的数据批量与内层表的数据进行匹配,从而减少了内层循环的次数(遍历一次内层表就可以批量匹配一次Join Buffer里面的外层表数据)。
当不使用Index Nested-Loop Join的时候,默认使用Block Nested-Loop Join。
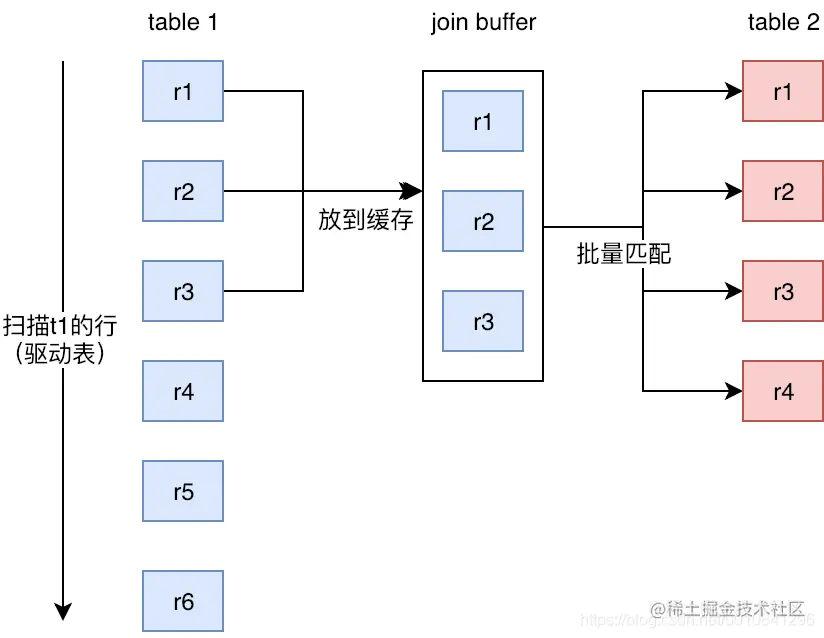
什么是Join Buffer?
(1)Join Buffer会缓存所有参与查询的列而不是只有Join的列。
(2)可以通过调整join_buffer_size缓存大小
(3)join_buffer_size的默认值是256K,join_buffer_size的最大值在MySQL 5.1.22版本前是4G-1,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。
(4)使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认为开启。
五.如何优化Join速度
用小结果集驱动大结果集,减少外层循环的数据量,从而减少内层循环次数:
如果小结果集和大结果集连接的列都是索引列,mysql在内连接时也会选择用小结果集驱动大结果集,因为索引查询的成本是比较固定的,这时候外层的循环越少,join的速度便越快。
为匹配的条件增加索引:争取使用INLJ,减少内层表的循环次数
增大join buffer size的大小:当使用BNLJ时,一次缓存的数据越多,那么内层表循环的次数就越少
减少不必要的字段查询:
(1)当用到BNLJ时,字段越少,join buffer 所缓存的数据就越多,内层表的循环次数就越少;
(2)当用到INLJ时,如果可以不回表查询,即利用到覆盖索引,则可能可以提示速度。(未经验证,只是一个推论)
参考:
blog.csdn.net/u010841296/….


