

这节,我们来学学用keras高层API搭建神经网络,本质上keras也是一个深度学习框架,被tensorflow包容了而已。
一、数据集
在此过程中不需要
- 对输入数据进行塑形:网络的输入层再塑形
- 数据类型转换:model.fit(),需要传入的训练集和训练的标签是numpy数组或者是numpy数组列表
- 划分验证集:model.fit(),可以一键配置验证集比例
import tensorflow as tf
tf.__version__
'2.6.0'
mnist = tf.keras.datasets.mnist
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()
train_images.shape,train_labels.shape,test_images.shape
((60000, 28, 28), (60000,), (10000, 28, 28))
'''
注意数据类型全都是numpy数组,因为model.fit()需要的数据集类型就是numpy数组
'''
# 归一化
train_x = train_images / 255.0
test_x = test_images / 255.0
# 独热编码
train_y = tf.one_hot(train_labels,depth=10).numpy()
test_y = tf.one_hot(test_labels,depth=10).numpy()
test_x.shape,test_y.shape
((10000, 28, 28), (10000, 10))
二、建模
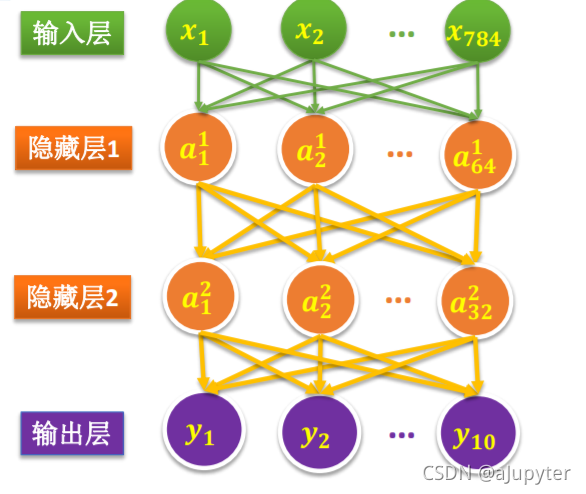
2.1建立一个序列模型
# 建立Sequential线性堆叠模型
model = tf.keras.models.Sequential()
2.2添加输入层(平坦层,Flatten)
model.add(tf.keras.layers.Flatten(input_shape=(28,28))) #这里也就是为什么前面不需要数据塑形的原因,会在定义网络的时候约束
2.3添加隐藏层(密集层,Dense)
# 添加全连接层1
model.add(tf.keras.layers.Dense(units=64,kernel_initializer='normal',activation='relu'))
# 神经元个数 units=64,
# 权重初始化方式 kernel_initializer='normal', 等价于 kernel_initializer=initializers.random_normal(stddev=0.01)
# 激活函数 activation='relu' 等价于 activation=tf.nn.relu
# 添加全连接层2
model.add(tf.keras.layers.Dense(units=32,kernel_initializer='normal',activation='relu'))
2.4添加输出层(密集层)
model.add(tf.keras.layers.Dense(units=10,activation='softmax'))
2.5输出模型摘要(非必要)
model.summary()
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_4 (Flatten) (None, 784) 0
_________________________________________________________________
dense_13 (Dense) (None, 64) 50240
_________________________________________________________________
dense_14 (Dense) (None, 32) 2080
_________________________________________________________________
dense_15 (Dense) (None, 10) 330
=================================================================
Total params: 52,650
Trainable params: 52,650
Non-trainable params: 0
_________________________________________________________________
标明该模型有52650个参数,全部都可以训练
2.6一次性建模(等价于上面的方式)
model2 = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(64,activation=tf.nn.relu),
tf.keras.layers.Dense(32,activation=tf.nn.relu),
tf.keras.layers.Dense(10,activation=tf.nn.softmax),
])
model2.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_5 (Flatten) (None, 784) 0
_________________________________________________________________
dense_16 (Dense) (None, 64) 50240
_________________________________________________________________
dense_17 (Dense) (None, 32) 2080
_________________________________________________________________
dense_18 (Dense) (None, 10) 330
=================================================================
Total params: 52,650
Trainable params: 52,650
Non-trainable params: 0
_________________________________________________________________
三、训练
# 定义训练模式
model.compile(optimizer='adam', # 优化器 可以从tf.keras.optimizers中选择
loss=tf.losses.categorical_crossentropy, # 损失函数 可以从tf.keras.losses中选择
metrics=['accuracy']) # 评估模型的方式,有一个默认的loss # 可以从tf.keras.metrics中选择
# 设置训练参数
train_epochs = 10 # 训练轮数
batch_size = 30 # 单次训练样本数(批次大小)
- x:输入数据。如果模型只有一个输入,那么x的类型是numpy
array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array - y:标签,numpy array
- batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
- epochs:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置initial_epoch时,它就是训练的总轮数,否则训练的总轮数为epochs - inital_epoch
- verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
- callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
- validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
- validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖 validation_spilt。
- shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
- class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
- sample_weight:权值的numpy
- array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=’temporal’。
- initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
- fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
# 训练模型
train_history = model.fit(train_x,#训练集
train_y,#训练集的标签
validation_split=0.2,#验证集的比例
epochs=train_epochs,#训练的次数
batch_size=batch_size,#小批量大小
verbose=2) # 训练过程的日志信息显示,一个epoch输出一行记录
Epoch 1/10
1600/1600 - 3s - loss: 0.3493 - accuracy: 0.9028 - val_loss: 0.1889 - val_accuracy: 0.9452
Epoch 2/10
1600/1600 - 3s - loss: 0.1549 - accuracy: 0.9547 - val_loss: 0.1423 - val_accuracy: 0.9590
Epoch 3/10
1600/1600 - 3s - loss: 0.1111 - accuracy: 0.9673 - val_loss: 0.1180 - val_accuracy: 0.9652
Epoch 4/10
1600/1600 - 3s - loss: 0.0866 - accuracy: 0.9738 - val_loss: 0.1040 - val_accuracy: 0.9688
Epoch 5/10
1600/1600 - 3s - loss: 0.0688 - accuracy: 0.9785 - val_loss: 0.1076 - val_accuracy: 0.9684
Epoch 6/10
1600/1600 - 3s - loss: 0.0567 - accuracy: 0.9828 - val_loss: 0.1037 - val_accuracy: 0.9725
Epoch 7/10
1600/1600 - 3s - loss: 0.0473 - accuracy: 0.9854 - val_loss: 0.1082 - val_accuracy: 0.9706
Epoch 8/10
1600/1600 - 3s - loss: 0.0401 - accuracy: 0.9871 - val_loss: 0.1012 - val_accuracy: 0.9734
Epoch 9/10
1600/1600 - 3s - loss: 0.0351 - accuracy: 0.9888 - val_loss: 0.1045 - val_accuracy: 0.9736
Epoch 10/10
1600/1600 - 3s - loss: 0.0302 - accuracy: 0.9904 - val_loss: 0.1038 - val_accuracy: 0.9723
# 训练过程指标数据
'''
history是一个字典类型数据,包含了4个Key:
loss、accuracy、val_loss和val_accuracy,分
别表示训练集上的损失、准确率和验证集上的损
失和准确率。
它们的值都是一个列表,记录了每个周期该指标
的具体数值。
'''
train_history.history
{'accuracy': [0.9028333425521851,
0.9546874761581421,
0.9673333168029785,
0.9738333225250244,
0.9785208106040955,
0.9828125238418579,
0.9854375123977661,
0.9870833158493042,
0.9888125061988831,
0.9903958439826965],
'loss': [0.34926730394363403,
0.1549162119626999,
0.11109178513288498,
0.0865616723895073,
0.06875421851873398,
0.05673694983124733,
0.04726575314998627,
0.040073737502098083,
0.03509596362709999,
0.030249839648604393],
'val_accuracy': [0.9451666474342346,
0.9589999914169312,
0.9651666879653931,
0.96875,
0.968416690826416,
0.9725000262260437,
0.9705833196640015,
0.9734166860580444,
0.9735833406448364,
0.9723333120346069],
'val_loss': [0.18894648551940918,
0.14231790602207184,
0.1179749146103859,
0.10402572900056839,
0.1075635701417923,
0.10374754667282104,
0.108195960521698,
0.10124330967664719,
0.10445128381252289,
0.10383494198322296]}
# 训练过程可视化
import matplotlib.pyplot as plt
def show(train_history,train_metric,valid_metric):
'''
train_history:训练的历史数据
train_metric:训练集的度量
valid_metric:验证集的度量
'''
plt.plot(train_history[train_metric],'r')
plt.plot(train_history[valid_metric],'b')
plt.title('Train History')
plt.legend(['train','valid'])
plt.show()
# 可视化损失
show(train_history.history,'loss','val_loss')
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BsDeL928-1632965688474)(output_29_0.png)]](https://img-blog.csdnimg.cn/110a531ca9254790b22b2501fffcd124.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAYUp1cHl0ZXI=,size_12,color_FFFFFF,t_70,g_se,x_16)
# 可视化准确率
show(train_history.history,'accuracy','val_accuracy')
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V3phUk54-1632965688477)(output_30_0.png)]](https://img-blog.csdnimg.cn/12b7285aa3624409a6f3db15acf46104.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAYUp1cHl0ZXI=,size_12,color_FFFFFF,t_70,g_se,x_16)
# 评估模型
test_loss,test_acc = model.evaluate(test_x,test_y,verbose=2)
313/313 - 1s - loss: 0.0856 - accuracy: 0.9742
test_loss,test_acc
(0.08561954647302628, 0.9742000102996826)
- 如果没有指定其余模型度量指标(metrics)参数,那么模型评估evaluate()返回的是一个损失值标量;如果指定了其他度量指标,那么返回的是一个列表
model.metrics_names # 验证度量方式有一个默认的loss
['loss', 'accuracy']
四、预测
pre = model.predict(test_x)
pre_real = tf.argmax(pre,axis=1).numpy()
tf.argmax(test_y[0]).numpy(),pre_real[0]
(7, 7)
