这是我参与11月更文挑战的第14天
原文链接
简介
a deep knowledge-aware network (DKN)将知识图谱表示方法结合到新闻推荐中,它是一个基于内容的深度推荐框架,用于预测点击率。DKN的关键部件是一个多通道、单词实体对齐(word-entity-aligned)的知识感知卷积神经网络(KCNN),它融合了新闻的语义级和知识级表示。KCNN将单词和实体视为多个通道,并在卷积过程中明确保持它们的对齐关系。此外,为了解决用户的多样化兴趣,DKN中还设计了一个注意力模块(attention module),可以根据当前候选新闻动态聚合用户的历史。
相关概念
知识图谱嵌入
见知识图谱学习
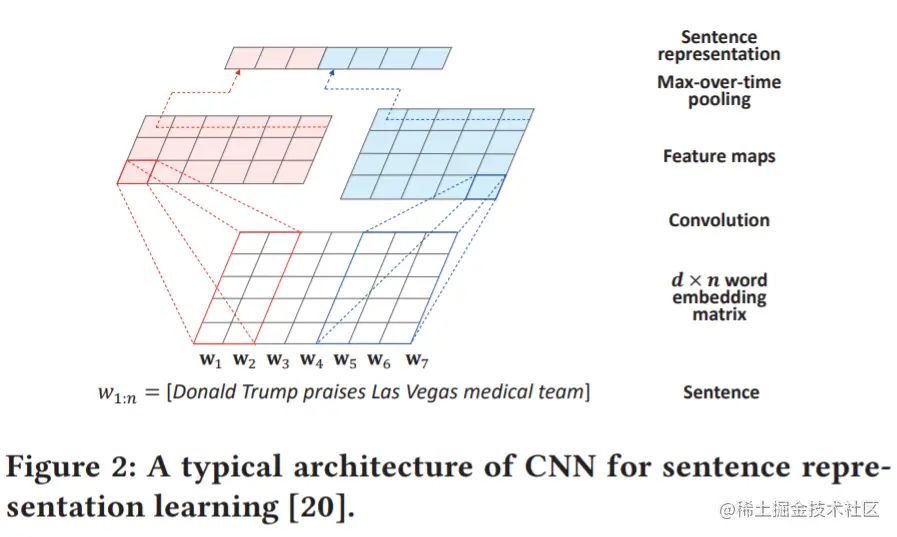
CNN用于句子表示学习
传统的方法通常采用 bag-of-words (BOW) 来表示句子,即使用单词计数统计作为一个句子的特征,但这种方法忽略了句子中的词序特征且容易出现稀疏问题,导致泛化性能较差。
更好的建模句子方法是将给定语料库中的每个句子表示为一个分布式的低维向量。卷积神经网络(CNN)已经大规模地用于计算机视觉研究中,基于CNN模型的句子表示学习是最近的热点。
图2展示了一个有代表性的CNN句子表示学习架构,w1:n表示输入的原始句子,句子长度为n,w1:n=[w1,w2,...wn]∈Rd×n为输入句子的词嵌入矩阵,wi∈Rd×1为句子中第i个单词的嵌入,d表示词嵌入的维度。
问题形式化
在在线新闻平台,对于给定用户i,其点击历史为{t1i,...,tNi},tji(j=1,...,Ni)为用户i点击的第j个新闻的标题,Ni表示用户i点击新闻的总数。每个标题t由一串单词t=[w1,...]组成,而在知识图谱中每个单词w可能和一个实体e相关联。例如:标题Trump praises Las Vegas medical team中Trump和实体Donald Trump链接, Las和Vegas同实体Las Vegas链接。
给定用户的点击历史,以及新闻标题中的单词和知识图谱中的实体间的连接,本文的目的是预测一个用户i是否会点击一个他从来没看过的候选新闻tj。
DEEP KNOWLEDGE-AWARE NETWORK, DKN
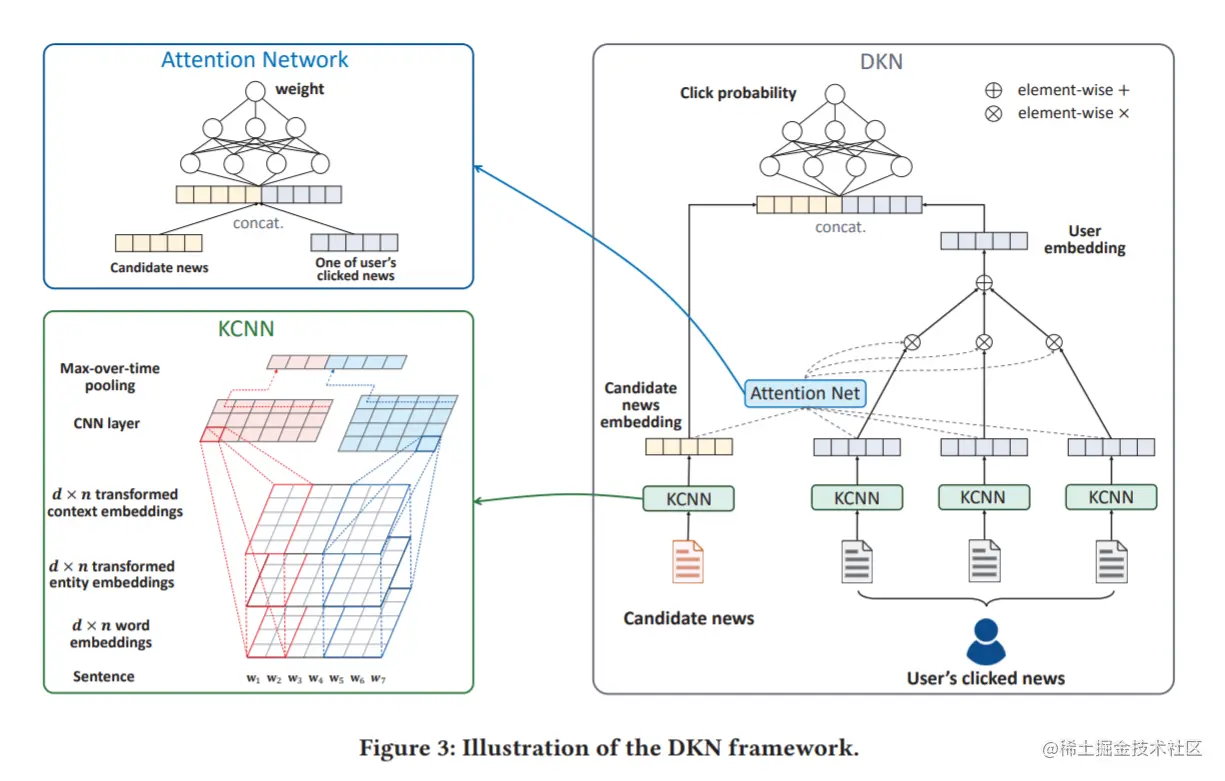
DKN架构
DKN架构如下图3所示,其输入是候选新闻和用户点击新闻历史。对于每条新闻,都使用一个专门设计的知识感知卷积神经网络(KCNN)来处理其标题并生成嵌入向量,KCNN是传统CNN的扩展,它可以灵活地将知识图谱中的符号知识整合到句子表示学习中。通过KCNN,得到一组用户点击历史的嵌入向量,为了得到用户对当前候选新闻的最终嵌入,使用一种基于注意力的方法,自动地匹配候选新闻与用户的每条点击新闻进,并将用户的历史兴趣按不同权重进行聚合。最后,将候选新闻嵌入和用户嵌入连接起来并输入深度神经网络(DNN),计算用户点击候选新闻的预测概率。
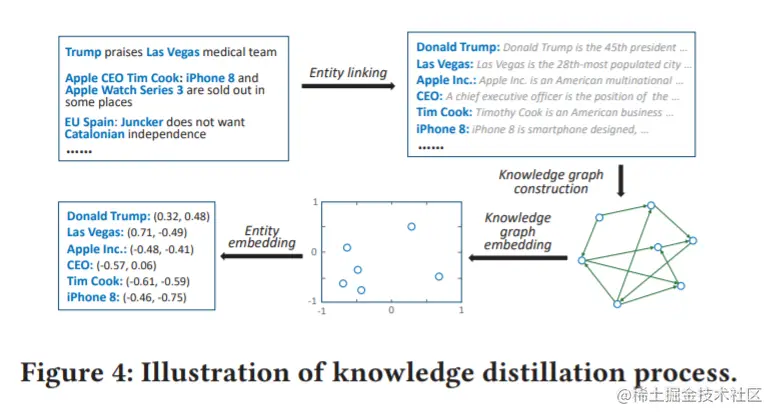
知识蒸馏
知识蒸馏的过程如图4所示,由四个步骤组成:
- 为了区分新闻内容中的知识实体,使用实体链接技术,通过将它们与知识图谱中预定义的实体关联来消除文本中提到的歧义。
- 在此基础上,构造一个子图,并从原知识图谱中提取出它们之间的所有关系链接。
- 对于提取出来的知识图,有很多知识图谱嵌入方法可以用来做实体表示学习如TransE、TransH等。
- 学习得到的实体嵌入将作为DKN框架中KCNN的输入。
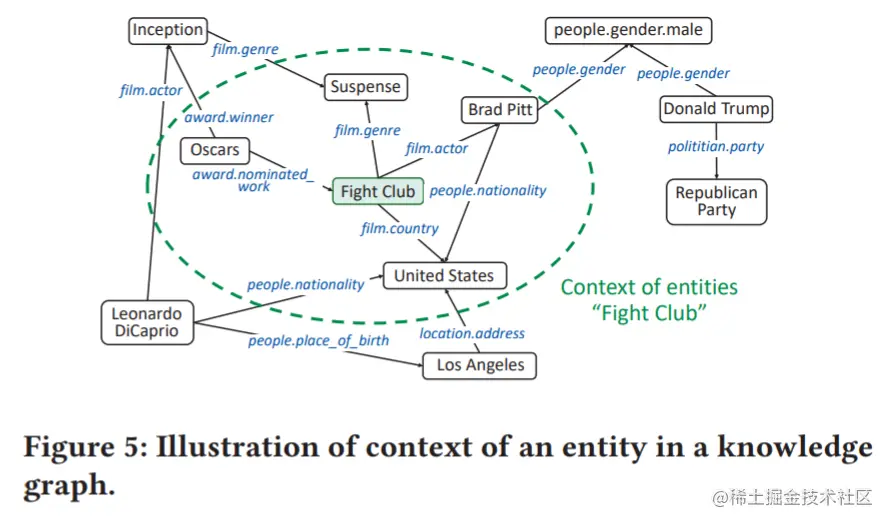
为保留原图谱中的结构信息,帮助识别实体在知识图谱中的位置,文中建议为每个实体提取额外的上下文信息。对于实体e,其上下文定义为:
context(e)={ei∣(e,r,ei)∈G or (ei,r,e)∈G}
此处r指代一个关系,G为知识图谱。一个实体及其上下文的例子如图5所示:
对于给定上下文的实体e,其上下文嵌入为上下文实体的均值:
eˉ=∣context(e)∣∑ei∈context(e)ei
ei为通过知识图谱嵌入学到的ei的实体嵌入。
知识感知CNN
组合单词和相关实体的一种直接方法是将这些实体视为“伪单词”,并将它们连接到单词序列:
W=[w1w2...wnet1et2...]
此处的{etj}是与新闻标题相关联的实体嵌入,W将会被输入CNN中做进一步处理。
然而上面的连接方式是有局限性的,因此在DKN中使用了一个多通道和词实体对齐的KCNN,用于结合词语义和知识信息。KCNN的结构如图3所示,对于每个新闻标题t=[w1,w2,...wn],使用其词嵌入ww1:n=[ww1,...wwn],引入变换后的实体嵌入:
g(e1:n)=[g(e1)g(e2)...g(en)]
及变换后的上下文嵌入:
g(eˉ1:n)=[g(eˉ1)g(eˉ2)...g(eˉn)]
作为输入源,g为变换函数,在KCNN中g可以是线性的:
g(ee)=MeMe
或是非线性的:
g(ee)=tanh(Me+bMe+b)
此处MM∈Rd×k为可训练的变换矩阵,bb∈Rd×1为可训练的偏置。
综上可得到多通道输入WW:
WW=[[ww1g(ee1)g(eeˉ1)][[ww2g(ee2)g(eeˉ2)]...[[wwng(een)g(eeˉn)]]
应用多个过滤器hh∈Rd×l×3使用不同的窗口大小l在新闻标题中提取特定的局部模式。关于hh的局部激活值子矩阵WWi:i+l−1可以写作:
cih=f(h∗Wh∗Wi:i+l−1+b)
s使用max-over-time pooling在输出特征映射上来选择最大特征:
c~h=max{c1h,...,cn−l+1h}
所有特征c~h被连接在一起并作为输入新闻标题t的最终表示ee(t),即:
ee(t)=[c~h1...c~hm]
m为过滤器的数量。
基于注意的用户兴趣提取
对于用户i的点击历史{t1i,...tNii},他点击新闻的嵌入可以写作ee(t1i),...eeNii。
对于候选新闻tj要考虑用户i是否会点击它,为了表征用户的多样化兴趣,使用注意网络来模拟用户点击历史对候选新闻的不同影响。
具体来说,对于用户i点击过的新闻tki和候选新闻tj,首先连接它们的嵌入然后使用一个DNN H作为注意网络,用softmax函数来计算归一化影响权重:
stki,tj=softmax(H(ee(tki),ee(tj)))=∑k=1Niexp(H(ee(tki),ee(tj)))exp(H(ee(tki),ee(tj))
注意网络H接收两个新闻标题的嵌入作为输入并输出影响权重。用户i关于候选新闻tj的嵌入可以被计算为他点击历史新闻标题嵌入的权重和:
ee(i)=k=1∑Nistki,tjee(tki)
最后,给定用户i的嵌入ee(i)和候选新闻的嵌入ee(tj),用户i点击新闻tj的概率可以由另一个DNN G计算:
pi,tj=G(ee(i),ee(tj)) 

