

数据类型
基本类型和引用类型的核心区别
- 基本数据类型有 7 种:Number、String、Boolean、Undefined(未定义,应该有值)、Null(空值)、Symbol(ES6)、BigInt(ES11)。基本类型的特点是
值不可变,存储在栈内存,赋值是值拷贝- null和Undefined两者相等但不全等,在if中都会被转为false
- symbol(ES6 新增):表示唯一值,解决对象属性名冲突问题;Symbol ('a') !== Symbol ('a'),且不能被 for...in 遍历
- BigInt(ES11 新增):表示超大整数,解决 Number 最大安全值(2^53-1)的限制;写法是数字后加 n(比如 123n),不能和 Number 直接运算。
let a=1; let b=a; b=2; a 还是 1
- 引用数据类型核心是 Object,包括普通对象、数组、函数,还有 Date、RegExp 等子类。引用类型存储在
堆内存,栈里存地址,赋值是地址拷贝,所以修改拷贝后的变量会影响原变量。
let arr1=[1];
let arr2=arr1;
arr2.push (2); arr1 也会变成 [1,2]
检测数据类型方式
typeof
适合判断除了null基本类型、是因为js 在底层存储变量时,会在变量的机器码的低位1-3位存储其类型信息
- 000:对象、、、
- null:所有机器码均为0、由于
null的所有机器码均为0,因此直接被当做了对象来看待typeof null === 'object'为true、这是js初版遗留的bug
判断函数类型:typeof function(){} // function typeof检测null ,Array、Object时返回是Object ,返回字符串
因此要想判断数据具体是哪一种object时,可以利用instanceof,
instanceof
主要用来判断引用类型属于哪个构造函数,原理是检查构造函数的 prototype 是否出现在实例的原型链上
[] instanceof Array实际上是判断Array.prototype是否在[]的原型链上
a instanceof B 即a是B的实例,a的原型连是否在B的构造函数
原理: instanceof 主要的实现原理就是只要右边变量的 prototype 在左边变量的原型链上即可。因此,instanceof 在查找的过程中会遍历左边变量的原型链,直到找到右边变量的 prototype,如果查找失败,则会返回 false,告诉我们左边变量并非是右边变量的实例
console.log([] instanceof Array); // true
console.log({} instanceof Object); // true
console.log(1 instanceof Number); // false (基本类型不行)
返回布尔值、判断引用类型,不能判断基本类型 、左边对象的隐式原型等于右边构造函数的显示原型
instanceof检测是不准确的、且所有对象类型 instanceof Object 都是 true:[] instanceof Array; // true、[] instanceof Object; // true
所以要想比较准确的判断对象实例的类型时,可以采取 Object.prototype.toString.call 方法
Object.prototype.toString.call()
可以判断所有类型
“原理:所有的数据类型都继承了 Object.prototype,但大多数类型(如Array、Function)都重写了自身的 toString 方法。而 Object.prototype 上的原始 toString 方法,它的设计目的就是为了返回当前对象的内部类型标识。
当用 call 强行把任意数据当作 this 传入这个方法时,JS引擎内部会执行以下操作:
- 如果是
null或undefined,直接返回对应的[object Null]或[object Undefined]。 - 对于其他对象,它会获取该对象的
Symbol.toStringTag属性或者内部属性[[Class]]。 - 最后拼接成标准的
[object 类型]字符串返回。
所以,无论是什么数据类型,甚至是 document.all 这样的特殊宿主对象,这个方法都能给出准确的类型标签,因为它读取的是最底层的内部属性。”
- Object.prototype.toString.call(true) [object Boolean]
- Object.prototype.toString.call(123) [object Number]
- Object.prototype.toString.call(Function(){}) [object Function]
对Object.prototype.toString() 进行解释的:
-
传进来的值为
undefined的话,直接返回一个[object Undefined]。 -
传进来的值为
null的话,直接返回一个[object Null]。 -
既不是
undefined又不是null的话,JS将调用ToObject方法,将O作为ToObject(this)的执行结果.call(obj)的作用是将.call之前的函数中的this指向 obj,但也可以说是把.call之前的函数方法借给 obj 去使用,call确保了类型判断是被原型在调用,从而能输出正确的值。
"基于刚才说的 Object.prototype.toString 方法,我们可以自己封装一个通用的 getType 函数,这样在写一些工具函数(比如深拷贝)时会非常有用。"
function getType(value) {
// 如果是基本类型且不是 null/undefined,直接用 typeof 更简洁
if (value === null) return 'null';
if (value === undefined) return 'undefined';
// 对于引用类型,使用 toString 方法
return Object.prototype.toString.call(value).slice(8, -1).toLowerCase();
// 解释一下:'[object Array]' 截取从索引8到倒数第一个,得到 'Array',再转小写
}
// 测试一下
console.log(getType(1)); // 'number'
console.log(getType('abc')); // 'string'
console.log(getType(true)); // 'boolean'
console.log(getType(null)); // 'null'
console.log(getType(undefined)); // 'undefined'
console.log(getType([])); // 'array'
console.log(getType({})); // 'object'
console.log(getType(function(){})); // 'function'
console.log(getType(new Date())); // 'date'
construcor
construtor 其实也是用了原型链的知识、、constructor 属性返回对创建此对象的数组函数的引用。
var a = 123;
console.log( a.constructor == Number); // true
var c = [];
console.log( c.constructor == Array); // true
var f = null;
console.log( f.constructor == Null); // TypeError: Cannot read property 'constructor' of null
var g;
console.log( g.constructor == Undefined); // Uncaught TypeError: Cannot read property 'constructor' of undefined
- 无论是通过字面量或者构造函数创建的基本类型,都可以检测出。并且也可以检测出
Array、Object、Function引用类型,但是不能检测出Null和Undefined
原型和原型链
比如我要创建一批用户对象,每个用户都有名字,都需要能打招呼。如果这么写:
function createUser(name) {
let obj = {}
obj.name = name
obj.sayHi = function() { console.log('hi') }
return obj
}
每创建一个用户,都会生成一个新的sayHi函数,太浪费内存了。
原型就是来解决这个问题的。 把公共方法放到一个公共区域,让所有实例共用。这个公共区域,这就是prototype、每个函数都有一个prototype属性,往上面挂东西,用这个函数new出来的对象,就能通过__proto__访问到这些东西
function User(name) {
this.name = name
}
User.prototype.sayHi = function() { console.log('hi') }
let u1 = new User('张三')
let u2 = new User('李四')
u1.sayHi() // 'hi'
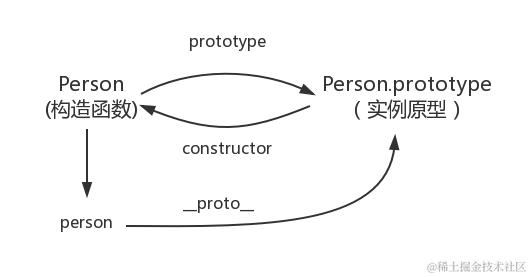
User.prototype这个对象,它里面默认有一个constructor属性,指向User函数本身。即User.prototype.constructor === User // true
constructor的作用是什么呢?其实就是告诉别人,这个原型对象是谁的
u1和u2本身没有sayHi方法,但它们能调用,就是因为u1.__proto__指向了User.prototype
u1.__proto__ === User.prototype // true
u1.__proto__.sayHi === User.prototype.sayHi // true
只有对象才有__proto__ ,但null和undefined没有:
而JS引擎找方法的流程是这样的:先看u1或u2本身有没有sayhi(),没有就看u1.__proto__(即User.prototype)有没有,没有就继续看User.prototype.__proto__(也就是Object.prototype),一直找到null为止,这条查找的链条,就叫原型链。
原型链在实际开发中的应用:平时写代码,经常用数组的map、forEach,数组本身并没有这些方法,它们就在Array.prototype上
prototype
prototype是给构造函数准备的,为了实现继承,让实例共享方法- 只有函数才有
prototype,因为只有函数才可能被new - 箭头函数除外,因为它不能用
new,所以没有 - 普通对象没有
prototype,因为没人需要"继承"它的东西,它的原型体现在__proto__上
当用new来调用一个函数时,JS引擎会创建新对象,然后把新对象的__proto__指向这个函数的prototype。这样新对象就能访问到prototype上的方法
普通对象没有prototype是因为它只代表它自己,不需要被new,也没人需要共享它的东西,let obj = { name: '张三' } // obj.prototype 是 undefined
this指向
它不是写时绑定,而是运行时绑定。它的指向完全取决于函数的调用方式、用优先级来判断,从上往下依次是:new绑定 → 显式绑定 → 隐式绑定 → 默认绑定。另外,箭头函数是一个特例,不参与这套规则。"
new绑定(最高优先级)
当用new调用函数时,this永远指向新创建的那个对象
为什么new的优先级最高,因为 new 创建了一个全新的执行环境,即使这个函数之前被 bind 硬绑定过,new 也能覆盖——毕竟构造函数必须初始化一个新对象,不可能去操作别处的 this。"
function Person(name) {
this.name = name
console.log(this) // this指向新创建的那个实例,所以输出 User {name: '张三'}
}
let u1 = new Person('张三')
const obj = {};
const BoundPerson = Person.bind(obj);
BoundPerson('Alice'); // obj.name = 'Alice',this指向obj
const p = new BoundPerson('Bob'); // this指向新对象p,而不是obj
new的原理
- 创建一个新的空对象
- 将这个对象的原型指向构造函数的
prototype - 让构造函数的this指向新对象
- 返回这个对象,让this指向它(若构造函数内部通过return返回一个引用类型,则new操作最终返回这个引用类型值,否则返回刚创建的新对象)
//第一种方式
function myNew(func, ...args) {
let obj = {}
obj.__proto__ = func.prototype
let res = func.apply(obj, args)
return res instanceof Object ? res : obj
}
//第二种方式
function createNew() {
let newObject = null
let constructor = Array.prototype.shift.call(arguments)
let result = null
if (typeof constructor !== 'function') return //判断参数是不是函数
newObject = Object.create(constructor.prototype)
result = constructor.apply(newObject, arguments)
let flag = result && (typeof result === 'object' || typeof result === 'function')
return flag ? result : newObject
}
createNew('构造函数,初始化函数')
显式绑定(call、apply、bind)
call和apply是立即执行并指定thisbind是返回一个新函数,这个新函数的this被永久绑定,无法再被call或apply改变(除非用new)
为什么它比隐式绑定优先级高? 因为它相当于强制干预了函数的调用过程——不管这个函数本来属于哪个对象,可以手动指定它运行时的 this。不再受调用时的上下文摆布。"
function sayHi() {
console.log(this.name)
}
const user1 = { name: '张三' }
const user2 = { name: '李四' }
sayHi.call(user1) // 张三,this指向user1、显式指定
sayHi.apply(user2) // 李四,this指向user2
const fn = sayHi.bind(user1)
fn() // 张三,bind绑死了,改不了
fn.call(user2); // 还是张三,bind的绑定优先级高于后续的call
call、apply、bind
提供一种灵活的方式来设置函数执行时的上下文,且可在运行时动态的确定参数数量
call
- 传参用逗号隔开,且会立即执行函数
- function.call(context,arg1,arg2) call原理思路:
- 根据call的规则设置上下文对象,也就是
this的指向。 - 通过设置
context的属性,将函数的this指向[隐式绑定]到context上 - 通过隐式绑定执行函数并传递参数。
- 删除临时属性,返回函数执行结果
Function.prototype.myCall = function (context, ...args) {
//myCall方法将被添加到Function原型对象上,目标函数调用时,myCall内部得到this将指向目标函数
if (typeof context !== 'function') {
throw new TypeError('not function')
}
context = context || window//如果不传参数,默认指向window
context.fn = this//将目标函数作为context对象的方法来执行,由此目标函数内的this将指向context
const result = context.fn(...args)//扩展运算符...处理传入目标函数的参数
delete context.fn//context中删除目标函数,因为不能改写了对象
return result
}
apply
- 传参是数组,且会立即执行函数,this指向由第一个参数决定,第2个参数是数组或argument对象
- function.apply(context,[arguments])
// apply原理和call类似、思路:将要改变this指向的方法挂到目标this上执行并返回
//tips:它的调用者必须是函数Function,并且只接受两个参数,第一个参数的规则和call一致
//第二个参数必须是数组或类数组,他们会被转换成类数组,传入Function中,且会被影射到Function对应的参数上、这也是call和apply之间很重要的一个区别
Function.prototype.myApply = function (context, args) {
if (typeof context !== 'function') {
throw new TypeError('not function')
}
context = context || window
context.fn = this
const result = context.fn(...args)
delete context.fn
return result
}
注意:当apply传入的第一个参数为null时,函数体内的this会指向window
- 用途 1.找出最大值和最小值
let max = Math.max.apply(null, array);//获取数组中最大项
let min = Math.min.apply(null, array);//获取数组中最小项
2. 实现两个数组合并
let arr1 = ['a','b'];
let arr2 = [4, 5, 6];
Array.prototype.push.apply(arr1, arr2);
console.log(arr1); //["a", "b", 0, 1, 2]
bind
原理分析:
- bind方法会返回一个新的函数
- 新函数执行时,它的this指向bind函数的第一个参数
- 新函数执行时,会将bind函数除第一参数之外的其余参数,与调用新函数时传入的参数合并,供调用的时候使用
- 传参用逗号隔开,不会立即执行函数,它返回一个新函数,该函数内部的this指向bind()的第一个参数,之后执行新函数相当于执行了目标函数
- function.bind(thisArg,arg1,arg2)
- 思路,类似call,但返回的是函数
//第一种方法
Function.prototype.myBind = function (context) {
if (typeof this !== 'function') {
throw new TypeError('not function')
}
let _this = this//有外部thiss,因函数里有返回的函数,执行中易造成this丢失
let arg = [...arguments].slice(1)//取外部入参,将context后面的参数取出来
return function F() {
if (this instanceof F) {//处理函数使用new的情况
return new _this(...args, ...arguments)
} else {
return _this.apply(context, arg.concat(...arguments))//改变this指向,合并函数入参数
}
}
}
//第二种方法
Function.prototype.myBind = function (context, ...initArgs) {
if (context === undefined || (context === null)) context = window
const _this = this
return function (...args) {
context.fn = _this
const result = context.fn(...initArgs, ...args)//处理传入目标函数的初始参数,后续参数
delete context.fn;
return result
}
}
隐式绑定(谁调用this就指向谁)
当函数作为对象的方法被调用时,比如 obj.fn(),this 就指向这个对象 obj
但隐式绑定有一个很大的陷阱:容易丢失。 因为'谁调用'这个关系是脆弱的——如果把方法赋值给一个变量再调用,或者作为回调函数传递,前面的'点'就丢了,this 会回退到默认绑定。这本质上是因为传递的是函数本身,而不是函数和对象的绑定关系。"
例1、function sayHi() {
console.log(this.name)
}
let user = {
name: '张三',
sayHi: sayHi
}
user.sayHi() // 张三,this指向user
例2、
const obj = {
name: 'MyObj',
foo: function() {
console.log(this.name);
}
};
obj.foo(); // 'MyObj',隐式绑定生效
> 当把[obj.foo](https://obj.foo/)赋值给一个变量时,传递的是函数本身,而不是函数+对象的绑定关系。"
const bar = obj.foo;
bar(); // undefined(或window.name),隐式绑定丢失!因为bar()前面没有点
那如何保证隐式绑定不丢失?
- 用
bind绑定:setTimeout(obj.foo.bind(obj), 1000) - 用箭头函数包裹:
setTimeout(() => obj.foo(), 1000) - 在构造函数内部用箭头函数定义方法(这样方法继承的是实例化时的
this)"
默认绑定
独立函数调用,比如 fn()
- 在非严格模式下,
this指向全局对象(浏览器里是window,Node.js 里是global) - 在严格模式下,
this指向undefined
当上面的三种规则都不适用时,就会落到默认绑定
箭头函数——特例
它不参与上面的优先级规则,因为它根本没有自己的 this
- 箭头函数的
this是词法作用域决定的——它在定义时就确定了,指向外层作用域的this - 它不能被
call、apply、bind改变 - 也不能用作构造函数(不能用
new)
所以判断箭头函数的 this,不要看它怎么调用,只看它**在哪里定义
const obj = {
name: 'Obj',
foo: function() {
const arrow = () => {
console.log(this.name);
};
arrow(); // 这里的this继承自foo的this
},
bar: () => {
console.log(this.name); // 这里的this继承自全局(因为外层是全局作用域)
}
};
obj.foo(); // 'Obj'
obj.bar(); // undefined(或window.name)
箭头函数和普通函数的区别
箭头函数是ES6引入的新语法,它和普通函数主要有6个区别:this指向、构造函数、arguments对象、原型、重复参数、调用方式。其中最重要的区别就是this的绑定机制
| 不同 | 普通函数 | 剪头函数 |
|---|---|---|
| this指向不同 | this是动态绑定的,谁调用就指向谁,而且可以通过call/apply/bind改变 | 没有自己的this,定义时确定,继承外层作用域的this,且一旦确定就不能改变 |
| 构造函数 | 可以作为构造函数,用new来调用,会创建一个新对象 | 不能使用new。因为箭头函数没有自己的this,而new需要给this绑定新对象 |
| arguments对象 | 可使用argument对象 ,它是一个类数组对象,包含所有传入的参数 | 没有自己的arguments对象。如果想获取参数,需要用剩余参数替代,要么去外层作用域找arguments |
| 原型对象 | 有prototype属性,可以用来给实例添加方法 | 没有prototype属性,因为它不能作为构造函数,不需要原型 |
| 重复参数 | 在非严格模式下允许重复参数名,后面的会覆盖前面的;严格模式下会报错 | 始终不允许重复参数名,无论什么模式都会报错 |
| 调用方式 | 有多种调用方式:直接调用、对象方法、call/apply/bind、new调用 | 调用方式比较单一:只能直接调用或作为回调,不能用call改变this,也不能被new |
数组有哪些方法
分成4大类:修改器方法、迭代方法、查找方法、转换方法、根据不同的业务场景快速选择最合适的方法
修改器方法(会改变原数组)
- pop(移除最后元素)、push(在最后增加元素)、shift(删除第一个元素)、unshift(向数组的头部添加元素)、reverse(反转)、sort(排序)、splice(增删改任意位置)
const a = ['es','js','vue']
const b = a.push('css')
//push返回结果数组的长度
console.log(a,b) //['es','js','vue','css'] 4
const c = a.pop()
//pop 返回的是被移除的项
console.log(a,c) //['es','js','vue'] 'css'
const d = a.shift()
//shift 删除第一个元素 返回被删除的元素
console.log(a,d)//['js','vue'] 'es'
const e = a.unshift('es')
//unshift:返回结果数组的长度
console.log(a,d)//['es','js','vue'] 3
- sort:根据unicode编码排序不稳定:arr.sort((a,b)=>a-b)//a-b升序,b-a降序
- splice:对数组进行增减:arr.splice(index,howmany,item1,item2...)//下标从0开始,howmany数字是几就是删除几个
['a','b',2,3].splice(2,1,'add1','add2')//['a','b','add1','add2',3]
迭代方法(遍历数组,不会改变原数组)
forEach、map、filter、reduce、some、every、这些方法还可以链式调用
// 场景1:数据格式化(map)
const users = [
{ id: 1, firstName: '张', lastName: '三' },
{ id: 2, firstName: '李', lastName: '四' }
];
const formattedUsers = users.map(user => ({
label: `${user.firstName}${user.lastName}`,
value: user.id
}));
// 输出:[{ label: '张三', value: 1 }, { label: '李四', value: 2 }]
// 场景2:搜索功能(filter)
const products = ['苹果', '香蕉', '菠萝', '草莓'];
const keyword = '菠';
const searchResult = products.filter(item => item.includes(keyword));
// 输出:['菠萝']
// 场景3:购物车总价(reduce)
const cart = [
{ name: '手机', price: 2999, count: 2 },
{ name: '耳机', price: 399, count: 1 }
];
const total = cart.reduce((sum, item) => sum + item.price * item.count, 0);
// 输出:6397
// 场景4:权限检查(every)
const permissions = ['read', 'write', 'delete'];
const hasAllPermissions = ['read', 'write'].every(p => permissions.includes(p));
// 输出:true
// 场景5:是否有选中项(some)
const items = [
{ id: 1, selected: false },
{ id: 2, selected: true },
{ id: 3, selected: false }
];
const hasSelected = items.some(item => item.selected); // true
foEach和map区别
- 相同点
- 都循环数组中的每一项
- 每次循环的匿名函数都有三个参数:当前项item,当前索引index,原始数组arr
- 匿名函数的this都指向window
- 只能循环数组
- 不同点
- forEach没有返回值,会改变原数组
- map有返回值,返回新的数组,原数组不变,可以链式别的方法
- 用途上:forEach不改变原数组,只是用做数据做一些事情
every/some
- every:
- 判断数组中每一项是否都满足条件,只有所有项都满足条件,才会返回true
- 当每个回调函数的返回值都为true时,every的返回值为true,只要有一个回调函数的返回值为false,every的返回值都为false
- 当回调函数的返回值为true时,类似于forEach的功能,遍历所有;如果为false,那么停止执行,后面的数据不再遍历,停在第一个返回false的位置
var arr = ["Tom","abc","Jack","Lucy"];
var a = arr.every(function(value,index,self){
console.log(value + "--" + index + "--" + (arr == self))
return true;//因为回调函数中没有return true,默认返回undefined,等同于返回false
})
// Tom--0--true
// abc--1--true
// Jack--2--true
// Lucy--3--true
//因为每个回调函数的返回值都是true,那么会遍历数组所有数据,等同于forEach功能
- some
- 判断数组中是否存在满足条件的项,只要有一项满足条件,就会返回true
- 因为要判断数组中的每一项,只要有一个回调函数返回true,some都会返回true、当遇到一个回调函数的返回值为true时,可以确定结果,那么停止执行,后面都数据不再遍历,停在第一个返回true的位置;当回调函数的返回值为false时,需要继续向后执行,到最后才能确定结果,所以会遍历所有数据,实现类似于forEach的功能,遍历所有。
- 只要有一个回调函数的返回值都为true,some的返回值为true,所有回调函数的返回值为false,some的返回值才为false
var arr = ["Tom","abc","Jack","Lucy","Lily","May"];
var a = arr.some(function(value,index,self){
return value.length > 3;
})
console.log(a); //true
var a = arr.some(function(value,index,self){
return value.length > 4;
})
console.log(a);//false
查找方法(不会改变原数组)
用于在数组中找元素或判断是否存在
// 场景1:用户登录验证(find)
const users = [
{ id: 1, username: 'alice', password: '123' },
{ id: 2, username: 'bob', password: '456' }
];
const user = users.find(u => u.username === 'alice' && u.password === '123');
// 场景2:权限判断(includes)
const userRoles = ['admin', 'editor'];
const isAdmin = userRoles.includes('admin'); // true
// 场景3:更新列表项(findIndex)
const todos = [
{ id: 1, text: '吃饭', done: false },
{ id: 2, text: '睡觉', done: true }
];
const index = todos.findIndex(t => t.id === 2);
if (index > -1) {
todos[index].done = false; // 更新
}
find
该方法对数组所有成员依次执行 callback 函数,直到找出第一个返回值为 true 的成员,然后返回该成员。如果没有符合条件的成员,则返回 undefined。
[1, 4, -5, 10].find((v,i,arr)=>v<0) //-5
[1,2,3,4,5].find(item=> item > 3) // 4
- map和forEach: forEach:用来遍历数组,没有返回值 map:1.同forEach功能; 2.map的回调函数会将执行结果返回,最后map将所有回调函数的返回值组成新数组返回。
//功能2:每次回调函数的返回值被map组成新数组返回
var arr = ["Tom","Jack","Lucy","Lily","May"];
var a = arr.map(function(value,index,self){
return "hi:"+value;
})
console.log(a); //["hi:Tom", "hi:Jack", "hi:Lucy", "hi:Lily", "hi:May"]
console.log(arr); //["Tom", "Jack", "Lucy", "Lily", "May"]---原数组未改变
filter::1.同forEach功能;2.filter的回调函数需要返回布尔值,当为true时,将本次数组的数据返回给filter,最后filter将所有回调函数的返回值组成新数组返回
//功能2:当回调函数的返回值为true时,本次的数组值返回给filter,被filter组成新数组返回
var arr = ["Tom","Jack","Lucy","Lily","May"];
var a = arr.filter(function(value,index,self){
return value.length > 3;
})
console.log(a); //["Jack", "Lucy", "Lily"]
console.log(arr); //["Tom", "Jack", "Lucy", "Lily", "May"]---原数组未改变
一:map(),foreach,filter循环的共同之处:
1.foreach,map,filter循环中途是无法停止的,总是会将所有成员遍历完。
2.他们都可以接受第二个参数,用来绑定回调函数内部的this变量,将回调函数内部的this对象,指向第二个参数,间接操作这个参数(一般是数组)。
二:map()循环和forEach循环的不同:
forEach循环没有返回值;map,filter循环有返回值。
三:map(环和filter()循环都会跳过空位,for和while不会
四:some()和every():
some()只要有一个是true,便返回true;而every()只要有一个是false,便返回false.
五:reduce(),reduceRight():
reduce是从左到右处理(从第一个成员到最后一个成员),reduceRight则是从右到左(从最后一个成员到第一个成员)。
六:Object对象的两个遍历Object.keys与Object.getOwnPropertyNames:
他们都是遍历对象的属性,也是接受一个对象作为参数,返回一个数组,包含了该对象自身的所有属性名。但Object.keys不能返回不可枚举的属性;Object.getOwnPropertyNames能返回不可枚举的属性。
转换方法(不会改变原数组)
把数组转换成其他形式
// 场景1:生成URL参数(join)
const params = ['sort=desc', 'page=1', 'size=10'];
const queryString = '?' + params.join('&'); // '?sort=desc&page=1&size=10'
// 场景2:分页数据加载(concat)
let list = [1, 2, 3];
const nextPage = [4, 5, 6];
list = list.concat(nextPage); // [1, 2, 3, 4, 5, 6]
// 场景3:分页截取(slice)
const allItems = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
const page1 = allItems.slice(0, 5); // [1, 2, 3, 4, 5]
const page2 = allItems.slice(5, 10); // [6, 7, 8, 9, 10]
// 场景4:扁平化多层数组(flat)
const nested = [1, [2, [3, 4]]];
const flat = nested.flat(2); // [1, 2, 3, 4]
var,let const、变量提升、暂时性死区
- var:声明以及函数内部的变量声明会被提升到作用域的顶端,但值不会
- let:变量会被绑定到块作用域上,它表现出了和函数 作用域相似的特征——出了块作用域,就访问不到里面的变量、而 var 是不感知块作用域的,即在代码块里用var声明的变量,在代码块之外也能访问到,let不能重复声明,可重新赋值、作用:for循环中var->let,var因变量声明提升会输出最后一个值,let输出当前值、2:不会污染全局变量
- const :声明的是常量且必须初始化且不能重新赋值,否则会报错、const声明的常量它的内存空间在哪个位置,这一点一开始就锁死了,不要尝试把 const 定义的变量指向新的内存空间
const a//定义的同时没有赋值,报错
const person={name:'wsn'} // 定义引用类型作为一个常量
person.name = 'hh' //修改对象的属性(object.name类型),没有改变对象的指针,即对象的引用仍然指向原有的内存地址可以修改, {name:'hh'}
person = {name:'hh'} //会报错,这是给person重新赋值了,把该对象的引用指向一个全新的对象,指向另一块内存空间既改了引用类型的指针
这是由于对象或者数组属于引用数据类、改变对象和数组的引用是改变了引用的对象的内存地址、而在原来的对象或数组里里添加删除数据,成员所在的对象的内存地址并没有改变,也就不会报错
let和const作用1: const me = 'xiuyan' me = 'Bear'//重新修改值,会报错 let和const:声明生效时机和具体代码的执行 时机保持一致、区别于var的一个重要特性是:不存在变量提升,须声明后才能调用不然会报错,这就是暂缓性死区(为减少运行时错误,防止声明之前就使用)
var、let、const
- var
- 是es5提出的,只有函数和全局作用域
- 可重复声明同一个值,后面的会覆盖前面的
var a = 1; //全局作用域
console.log(a) //1
{
var a = 2; // 代码块中声明,毫无影响
console.log(a) //2
}
console.log(a) //2
-
let、const
-
是es6提出的块级作用域
-
不存在变量声明提升,在声明前不可获取,称为暂时性死区
-
不能重复声明同一个值
-
const声明的常量,不能被修改且声明时必须赋值
-
let,var声明的是变量,可以被修改
var a = 1; let a = 1; //不能重复声明 报错 Identifier 'a' has already been declaredvar a = 1; //全局作用域 { let a = 2; // 代码块中声明,毫无影响 console.log(a)//2 } console.log(a)//1
-
-
变量声明提升
- 函数声明提升:即将函数声明提升到作用域顶部
-
函数声明式:声明和赋值都提升:
fn() function fn(){console.log(1)} //1 -
变量形式:只提升变量不提升值 fn() var fn = function(){console.log(1)} //报错
-
- 函数声明提升:即将函数声明提升到作用域顶部
-
变量声明提示:将变量声明提升到作用域顶部,但只提升声明不提升值、只有var才可以,let,const没有
console.log(num)//报错 var num = 10 console.log(fun)//报错 var fun = function(){}
const声明的是常量,常量不可以修改。常量定义必须初始化值,如果不初始化值就会报错。
tips:const变量不能修改指针,但是可以修改值
const b = 1
b = 2
console.log(b)//报错
const car = { type:'fait',mode:'500',color:'red' };//创建常量对象
car.type = 'hhh'//修改属性
car.owner = 'wsn'//添加属性
console.lo/(car)//最新/属性{type: 'hhh', mode: '500', color: 'red', owner: 'wsn'}
// 但是不能对常量对象重新赋值
car = {type: 'test', mode: '500', color: 'red'}//报错
两数之和
- 整数数组nums,目标值target,返回下标,假设只对应一个答案
let arr = [1, 4, 7, 2, 9, 10]
let target = 9
const towNums = (nums, target) => {
let len = nums.length
for (let i = 0; i < len; i++) {
for (let j = i + 1; j < len; j++) {//因同一个元素不允许重复出现,所以从i的下一位开始遍历
if (nums[i] + nums[j] === target) {
return [i, j]
}
}
}
}
console.log(towNums(arr, target))
反转字符串
- split()将字符串拆分为子字符串数组
- reverse:Array.prototype.reverse()反转数组中的元素,并返回同一数组的引用
- join()把数组中的所有元素转换一个字符串
let str = 'the sky is blue'
const reverseWord = (str) => {
return str.trim().split(' ').reverse().join(' ')
}
console.log(reverseWord(str))//blue is sky the
排序
| 标题 | 时间复杂度 | 稳定性 | 空间 |
|---|---|---|---|
| 冒泡 | o(n²) | 稳定 | o(1) |
| 插入 | o(n²) | 稳定 | o(1) |
| 选择 | o(n²) | 稳定 | o(1) |
| 快排 | o(nlogⁿ) | 不稳定 | o(logⁿ) |
空间:o(1)算法执行所需临时空间,不随n大小变化
时间:平方阶o(n²:把o(n)在嵌套循环一遍
常数阶:o(1)无论代码执行多少行,只要无循环等复杂结构
线性阶:o(n)如for循环的代码执行n遍,消耗时间随n变化
对数阶:o(logⁿ)
let arr = [12, 4, 2, 15, 5, 7, 9, 10, 1]
冒泡排序
- 将数组中两个相邻元素进行比较,
- 对每一队相邻元素作同样的比较,最后会是最大的元素,
- 针对所有元素重复以上步骤(除最后一个),直到所有元素排序完
function bubbleSort(arr) {
const len = arr.length
for (let i = 0; i < len - 1; i++) {//外层循环i控制比较的轮数
for (let j = 0; j < len - 1 - i; j++) {// 里层循环控制每一轮比较的次数j,arr[i] 只用跟其余的len -i-1个元素比较
if (arr[j] > arr[j + 1])[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]]
}
}
return arr
}
插入排序
- 将数组分为有序和无序
- 每次从后面未排序不分从头到尾依次扫描
- 把扫描的每个元素插入到有序的适当位置
function insertSort(arr) {
const len = arr.length
for (let i = 1; i < len; i++) {
//将arr[i]插入到arr[i-1],arr[i-2],arr[i-3]……之中
for (let j = i; j > 0; j--) {
if (arr[j] < arr[j - 1]) {
[arr[j - 1], arr[j]] = [arr[j], arr[j - 1]]
}
}
}
return arr
}
快速排序
- 从数组中找一个中间项作为基准值,在原有的数组中把它移除
- 重新排序数组,准备左右两个数组,循环剩下数组中的每一项,比当前项小的放到左边数组中,反之放到右边数组中
- 递归方式让左右两边的数组持续这样处理,一直到左右两边都排好序为止
function quickSort(arr) {
if (arr.length <= 1) return arr //结束递归(当ary小于等于一项,则不用处理)
const middleIndex = Math.floor(arr.length / 2)//中间项
const middle = arr.splice(middleIndex, 1)[0]
const leftArr = [],
rightArr = []
for (let i = 0; i < arr.length; i++) {
const current = arr[i]
current < middle ? leftArr.push(current) : rightArr.push(current)
}
return quickSort(leftArr).concat(middle, quickSort(rightArr))//递归处理,最后左,中间项,右拼接
}
选择排序
- 将数组分成2部分,已排序和未排序
- 先在未排序中找到最小元素,放到已排序中首位
- 再从剩余未排序中继续找最小,放到已排序的末尾
- 重复2直到所有元素排序完
function selectionSort(arr) {
const len = arr.length
for (let i = 0; i < len - 1; i++) {
let minIndex = i;
for (let j = i + 1; j < len; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j //保存最小数的下标
}
}
// const temp = arr[i]
// arr[i] = arr[minIndex]
// arr[minIndex] = temp
[arr[i], arr[minIndex]] = [arr[minIndex], arr[i]]
}
return arr
}
防抖、节流
防抖
是指当事件被触发后,函数不会立即执行,而是等待一段时间,如果在这段时间内没有再次触发该事件,函数才会执行。如果在这段时间内再次触发了该事件,则会重新计算等待时间
- 单位时间内频繁触发事件,只执行最后一次(重新计时)
- 场景:
- 按钮点击:防止误触或者误操作。例如,当用户在短时间内多次点击提交按钮时,防抖技术可以只将其视作一次有效的点击操作
- 输入框实时搜索:用防抖技术延迟执行搜索查询,减少不必要的查询和服务器压力
- 窗口大小调整:用防抖技术避免在调整过程中频繁地重新计算布局。这样可以提高性能,减少不必要的计算。
- 表单验证:用防抖技术在用户停止输入一段时间后再执行验证,减少验证的次数
- 利用定时器每次触发先清掉以前的定时器重新计时
//第一种方法:最优
var debounce = function (fn, t) {
let timer = null//用来保存setTimeout的返回值
return function (...args) {//返回一个新函数
if (timer) clearTimeout(timer)//若timer不为null,说明之前已调用过setTimeout,那就清除之前的定时器重新计时
timer = setTimeout(() => fn(...args), t)//调用setTimeout,在t毫秒后调用fn函数并传入参数
}
}
//第二种方法
function debounce(fn, t) {
let timer = null
return function () {
if (timer) clearTimeout(timer) //重新计时
timer = setTimeout(() => {
fn.apply(this.argument)
timer = null
}, t)
}
}
节流
是指在一定时间内只执行一次函数,即使事件被连续触发
- 单位时间内频繁触发事件只执行一次
- 场景:通常用于处理高频事件:
- **鼠标滑动:**例如实现一个拖拽功能,可以使用节流技术减少鼠标移动事件的处理频率。这样可以降低处理鼠标移动事件的开销,提高性能
- 滚动事件监听: 用节流技术减少检查滚动位置的频率,提高性能。这样可以避免在滚动过程中频繁地触发加载操作,提高页面的加载效率
- 动画效果: 当实现一个基于时间的动画效果时,可以使用节流技术限制动画帧率,降低计算开销。这样可以避免动画效果过于复杂而导致的性能问题
- 窗口调整 页面滚动或者抢购等场景:在这些场景中需用节流来控制事件的执行频率,以防止资源的浪费
- 利用定时器等定时器执行完才开启定时器
function throttle(fn, t) {
let timer = null
return function () {
if (timer) return //规定时间内只执行一次
timer = setTimeout(() => {
fn.apply(this.argument)
timer = null
}, t)
}
}
两者区别
- 执行时机不同:防抖是在最后一次触发事件之后等待一段时间执行函数,而节流则是在一定时间内只执行一次函数。
- 应用场景不同:防抖更适合处理一些需要用户稳定操作完成后的行为,如提交表单,而节流更适合处理高频率触发的事件,如鼠标移动、页面滚动等
拷贝
- 深拷贝和浅拷贝是只针对Object和Array这样的引用数据类型的
| 和原数据是否指向同一对象 | 第一层数据为基本类型 | 原数据中含子对象 | |
|---|---|---|---|
| 赋值 | 是 | 新旧数据相互影响 | 新旧数据相互影响 |
| 浅拷贝 | 否 | 新旧数据互不影响 | 新旧数据相互影响 |
| 深拷贝 | 否 | 新旧数据互不影响 | 新旧数据互不影响 |
赋值
赋值没有创建新对象,仅仅是拷贝了原对象的指针
赋值赋的其实是该对象的在栈中的地址,而不是堆中的数据、即两个对象指向的是同一块内存地址,无论哪个对象发生改变,其实都是改变的存空间的内容,因此,两个对象是联动的
let obj1 = {
a: 1,
b: 2,
c: {
q: 6
}
}
let obj2 = obj1//因为obj2只是复制了obj1的引用,指向的是同一块内存地址,所以是联动的
obj2.a = 3
obj1.c.q = 7
console.log(obj1) // {a: 3, b: 2, c: {q:7}}
console.log(obj2) // {a: 3, b: 2, c: {q:7}}
console.log(obj1===obj2) // true
浅拷贝
浅拷贝是创建一个新对象,这个对象仅对原对象的属性进行拷贝,属性值是基本类型时,拷贝的是原数据,属性值是引用类型时,拷贝的是指针。因此,如果原对象的属性有引用类型数据,无论修改新对象还是原对象的引用类型数据,另一个都会随之改变
-
和赋值区别:
-
赋值赋的其实是该对象的在栈中的地址,而不是堆中的数据。即两个对象指向的是同一个存储空间,无论哪个对象发生改变,其实都是改变的存储空间的内容,所以两个对象是联动的
-
而浅拷贝是创建一个新对象,若属性是基本类型,拷贝的就是基本类型的值,若属性是引用类型,拷贝的就是内存地址 ,所以其中一个对象改变了这个地址会影响到另一个对象基本类型不影响,引用类型相互影响
- Object.assign():把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象:let obj2 = Object.assign({}, obj1)
- 展开运算符…与 Object.assign ()的功能相同:let obj2= {... obj1}
- Array.prototype.concat()
- Array.prototype.slice()返回一个新的副本对象
-
Object.assign()
- 把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象,拷贝的是对象的属性的引用,而不是对象本身
var obj = { a: {a: "kobe", b: 39} };
var initalObj = Object.assign({}, obj);
initalObj.a.a = "wade";
console.log(obj.a.a); //wade、新旧数据相互影响
console.log(obj===initalObj)//false
- 当object只有一层的时候,是深拷贝
let obj = {username: 'kobe'};
let obj2 = Object.assign({},obj);
obj2.username = 'wade';
console.log(obj);//{username: "kobe"}//新旧数据互不影响
console.log(obj === obj2) //false
Array.prototype.concat()
let arr = [1, 3, {username: 'kobe',age: 6}];
let arr2 = arr.concat();
arr2[2].age = 7;
arr2[0] = 4
arr2[2].username = 'wade';
console.log(arr);//修改新对象会改到原对象,但数组里的第一层的基本类型新旧互不影响
//arr:[1, 3, {username: 'wade',age: 7}]
//arr2:[4, 3, {username: 'wade',age: 7}]
Array.prototype.slice()
let arr = [1, 3, {username: 'kobe',age: 6}];
let arr2 = arr.slice();
arr2[2].username = 'wade'
console.log(arr);//修改新对象会改到原对象,但数组里的第一层的基本类型新旧互不影响
//arr:[1, 3, {username: 'wade',age: 7}]
//arr2:[4, 3, {username: 'wade',age: 7}]
关于Array的slice和concat方法的补充说明:Array的slice和concat方法不修改原数组,只会返回一个浅复制了原数组中的元素的一个新数组
原数组的元素会按照下述规则拷贝:
- 如果该元素是个对象引用(不是实际的对象),slice 会拷贝这个对象引用到新的数组里。两个对象引用都引用了同一个对象。如果被引用的对象发生改变,则新的和原来的数组中的这个元素也会发生改变。
- 对于字符串、数字及布尔值来说(不是 String、Number 或者 Boolean 对象),slice 会拷贝这些值到新的数组里。在别的数组里修改这些字符串或数字或是布尔值,将不会影响另一个数组
扩展运算符...
slice
let arr1 = [1, 2, { username: 'Kobe' }];
let arr2 = arr1.slice();
arr2[2].username = 'Wade'
arr1[0] = 3
console.log(arr1); // [3, 2, {username: 'Wade' }]
console.log(arr2); //[1, 2, {username: 'Wade' }]
手写实现
function shallowClone(source) {
var target = {};
for(var i in source) {
if (source.hasOwnProperty(i)) {
target[i] = source[i];
}
}
return target;
}
let obj1 = {...}
let obj2 = shallowClone(obj1)
深拷贝
深拷贝也是创建一个新对象,但不仅对原对象的属性进行拷贝,还在堆内存中开辟一个新的地址用来存储新对象,所以新对象和原对象没有关联,修改其中一个另一个不会变化
- 无论是基本类型还是引用类型,拷贝的是一个新的完整的对象
- 使用场景:
- 原对象仅使用一次(被修改也不产生副作用),用赋值。
- 原对象需多次使用(被修改会导致后续使用数据不准确),且属性只有基本类型,无引用类型,用浅拷贝。
- 原数据需多次使用(被修改会导致后续使用数据不准确),且属性含有引用类型,用深拷贝
JSON.parse(JSON.stringify())
- 原理:用JSON.stringify将对象转成JSON字符串,再用JSON.parse()把字符串解析成对象,一去一来,新的对象产生了,而且对象会开辟新的栈,实现深拷贝
- 第一层基本类型和后面的引用类型都互不影响
- 但不能处理函数,因为JSON.stringify() 方法是将一个JavaScript值(对象或者数组)转换为一个 JSON字符串,不能接受函数,会被转成null
let arr = [1, 3, {
username: 'kobe',
age: 6
}];
let arr2 = JSON.parse(JSON.stringify(arr));
arr2[2].username = 'wade';
arr2[2].age = 7
arr2[0] = 4
console.log(arr);
console.log(arr2)
//arr:[1, 3, {username: 'kobe',age: 6}]
//arr2:[4, 3, {username: 'wade',age: 7}]
递归
- Date,正则,map,set等处理不完善
let arr = [1, 3, {
username: 'kobe',
age: 6
}];
const deepCopy = (obj) => {
if (typeof obj !== 'object' || obj === null) return obj//判断数据不是对象,数组或null时直接返回该值
const newObj = Array.isArray(obj) ? [] : {}
for (const key in obj) {
console.log(key); //username、age
if (obj.hasOwnProperty(key)) {//拷贝是拷贝对象的自身属性,所以要规避掉原型上的自定义属性、自身属性(true),还是继承属性(false),
newObj[key] = deepCopy(obj[key])
}
}
return newObj
}
let obj2 = deepCopy(obj);
obj2[2].username = 'wade';
obj2[2].age = 7
obj2[0] = 4
console.log(obj);
console.log(obj2)
//obj:[1, 3, {username: 'kobe',age: 6}]
//obj2:[4, 3, {username: 'wade',age: 7}]
数组的操作
扁平化数组
递归
通过for循环,逐层逐个元素的去展平,若当前元素是一个数组,那就把它进行递归处理,再将递归处理的结果拼接到结果数组上
const flatten = (arr) => {
let result = []
let len = arr.length
for (let i = 0; i < len; i++) {
if (Array.isArray(arr[i])) {
result = result.concat(flatten(arr[i]))//递归展平结果拼接到结果数组上
} else {
result.push(arr[i])//否则直接加入结果数组
}
}
return result
}
console.log(flatten(arr))[1, 2, 3, 4, 5, 6]
扩展运算符...+some
let arr = [1, [2, [3, 4, [5, 6]]]]
const flatten = (arr) => {
while (arr.some(i => Array.isArray(i))) {
arr = [].concat(...arr)
}
return arr
}
console.log(flatten(arr))[1, 2, 3, 4, 5, 6]
toString + split
- toString会将数组转成一个元素间以逗号相隔的字符串,它内部会先将数组展平一维后再转成字符串,因此可用toString进行展平
- 在通过split逗号分隔每个元素来复原一个包含所有元素的数组
- 缺点:对于包含引用类型元素的数组来说,在toString过程中会发生类型转换,从而转换结果异常
let arr = [1, [2, [3, 4, [5, 6]]]]
const flatten = (arr) => {
return arr.toString().split(',').map(i => Number(i))
}
console.log(flatten(arr))[1, 2, 3, 4, 5, 6]
Array.property.flat
let arr = [1, [2, [3, 4, [5, 6]]]]
const flatten = (arr) => {
return arr.flat(Infinity)
}
console.log(flatten(arr))[1, 2, 3, 4, 5, 6]
reduce + 递归
let arr = [1, [2, [3, 4, [5, 6]]]]
const flatten = (arr) => {
return arr.reduce((pre, cur) => {
return pre.concat(Array.isArray(cur) ? flatten(cur) : cur)
}, [])
}
console.log(flatten(arr))[1, 2, 3, 4, 5, 6]
数组和对象相互转换
检测数组:判断一个对象是不是数组
- arr instanceof Array //true/false
- Object.prototype.toString.call(arr) == '[object Array]'
- Array.isArray(arr)
- arr.constructor == Array
-
Array.isArray 实现
Array.myIsArray = function(arr) {
return Object.prototype.toString.call(arr) === '[object Array]';
};
console.log(Array.myIsArray([])); // true
对象转数组
const obj = {a: 1,b: 2}
Object.entries(obj)
const arr = Object.entries(obj)//[['a':1],['b':2]]
Object.keys(obj)
const arr = Object.keys(obj).map(item => [item, obj[item]])
其中Object.keys(obj)//['a', 'b']
//[['a':1],['b':2]]
Object.values(obj)
const arr = Object.values(obj)//[1,2]
Array.from(array,fn,this)
从一个类似数组对象或可迭代对象创建一新的。浅拷贝的数组实例,返回一个新的数组实例
const obj = {
0: 'name',
1: 'age',
2: 'sex',
length: 2 //含有length和索引的对象,决定了返回数组的长度
}
const arr = Array.from(obj) //['name', 'age']
数组转对象
扩展运算符...
const arr = ['one', 'two']
const obj = {...arr}
console.log(obj)//{0: 'one', 1: 'two'}
forEach
let obj = {}
arr.forEach((item, index) => {
obj[index] = item
})
console.log(obj) //{0: 'one', 1: 'two'}
Object.fromEntries()
把键值对转换为一个对象,返回由该迭代对象条目提供对应属性的新对象
const arr = [ ['a', 1],
['b', 2]
]
const obj = Object.fromEntries(arr)
console.log(obj) //{a: 1, b: 2}
map/forEach
let arr = [{
id: 1,
emNo: 18,
name: '王'
},
{
id: 2,
emNo: 19,
name: '仲'
},
]
let obj = {}
arr.map(item => {
obj[item.emNo] = item.name
})
console.log(obj) //{18: '王', 19: '仲'}
数组去重
let arr = [1,1,'true','true',true,true,false,false,undefined,undefined,null,null,NaN,NaN,'NaN','NaN','a','a',{},{},[1,2],[1,2],[],[],{a:1},{a:1}]
set
- 类似数组,其成员的值都是唯一的,利用Array.from将set结构转成数组
- 缺点:对象,数组未去重
const result = Array.from(new Set(arr))//对象,数组未去重
双重for循环+splice
- 外层循环元素,内层循环时比较值,值相同时则删去这个值,否则push进数组
- 缺点:NaN,对象,数组未去重
function unique(arr) {
let len = arr.length
for (let i = 0; i < len; i++) {
for (let j = i + 1; j < len; j++) {
if (arr[i] === arr[j]) {
arr.splice(j, 1)
len--
j--
}
}
}
return arr
}
unique(arr)
indexOf
- 缺点:NaN,对象,数组未去重
- 新建一个空数组,遍历需要去重的数组,将数组元素存放到新数组中,存放前判断数组返回是否包含当前元素,没有则存入
- 该方法返回调用他的string对象中第一次出现指定值的索引,从formIndex处进行搜索,若未找到该值,返回-1
function unique(arr) {
if (!Array.isArray(arr)) {
console.log('type error!')
return
}
const newArr = []
arr.forEach(item => {
if (newArr.indexOf(item) === -1) {
newArr.push(item)
}
});
return newArr
}
unique(arr)
includes
- 和indexof方法异曲同工,只是用includes用来判断一个数组是否包含指定的值,根据情况若包含则返true,否则false
- 缺点:对象,数组未去重
function unique(arr) {
const newArr = []
arr.forEach(item => {
if (!newArr.includes(item)) {//检测某个值是否存在
newArr.push(item)
}
});
return newArr
}
unique(arr)
hasOwnProperty
- 缺点:空对象,数组都可去重,但有值的对象被删除了
function unique(arr) {
let obj = {}
return arr.filter((item) => {
return obj.hasOwnProperty(typeof item + item) ? false : (obj[typeof item + item] = true)
//利用一个空的object对象,把数组的值存成object的key值,如objcet[value] = true,在判断另一个值时,若object[value]存在的话说明该值重复
//obj[typeof item + item]= true未直接用obj[item]是因123和'123'不同,直接用前面的方法会判断为同一个值,因对象的键值只能是字符串,所以用typeof item+item拼成字符串作为key值来避免着恶搞问题
})
}
unique(arr)
递归
- 先排序,然后从最后开始比较,遇到相同则删除
- 缺点: NaN,对象,数组未去重
function unique(arr) {
let array = arr;
let len = array.length
array.sort((a, b) => a - b) //排序后更加方便去重
function loop(index) {
if (index >= 1) {
if (array[index] === array[index - 1]) {
array.splice(index, 1)
}
loop(index - 1)//递归loop然后数组去重
}
}
loop(len - 1)
return array
}
unique(arr)
reduce+includes
function unique(arr){
return arr.reduce((prev,cur) => prev.includes(cur) ? prev : [...prev,cur],[]);
}
// [1, "true", true, 15, false, undefined, null, NaN, "NaN", 0, "a", {…}, {…}]
filter+indexof
- filter会创建一个新数组,对满足条件的元素存到一个新数组中,结合indexof进行判断
- filter()把传入的函数依次作用于每个元素,然后根据返回值是true/false决定保留还是丢弃元素
const unique = arrs => {
return arrs.filter((ele, index, array) => {
//当前元素,在原始数组中的第一个索引==当前索引值,否则返回当前元素
return array.indexOf(ele,0) === index
})
}
unique(arrs);
push和pop实现
//push首推:底层实现是依赖于 数组的length属性的
Array.prototype.push2 = function(...rest){
this.splice(this.length, 0, ...rest)
return this.length;
}
//pop尾删--也是同理:
Array.prototype.pop2 = function(){
return this.splice(this.length - 1, 1)[0];
}、
数组的深拷贝
const arr = [1,2,3,4]
- 以下方法都返回一个新数组,新旧数据互不影响
slice
const newArr = arr.slice(arr)
concat
const newArr = arr.concat()
map
const newArr = arr.map(num => num)
Array.form
const newArr = Array.from(new Set(arr))
扩展运算符...
const newArr = [...arr]
forEach +push
const newArr = []
arr.forEach(val => {
newArr.push(val)
})
for+push
const newArr = []
const len = arr.length
for (let i = 0; i < len; i++) {
newArr.push(arr[i])
}
判断是否为数组
- 最优:Array.isArray:Array.isArray(arr)

二分查找
- 数组必须有序,不存在重复
- 每次比较数组中间的元素,若中间元素正好是要查找元素,则查找成功
- 否则根据中间元素与要查找的元素的大小关系确定新的查找范围、、或者每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,知道找到目标元素
const BinarySearch = (arr, target) => {
//arr 待排序数组、target 目标数据
let len = arr.length
if (len <= 1) return -1
let left = 0 //左边界
let right = len - 1 //右边界
while (left <= right) {
const mid = Math.floor((left + right) / 2) //计算中间位置
if (target > arr[mid]) {
left = mid + 1 //则将左边界设为中间位置的右侧
} else if (target < arr[mid]) {
right = mid - 1 //否则将右边界设为中间位置的左侧
} else {
return mid
}
}
return -1 //若没有找到目标元素则返回-1
}
const arr = [1, 4, 5, 6, 7, 8, 10]
console.log(BinarySearch(arr, 5)) //表示5在arr中的位置下标->2
console.log(BinarySearch(arr, 1)) //0
查找第一个值等于target
- 数组必须有序,存在重复
const BinarySearch = (arr, target) => {
//arr 待排序数组、target 目标数据
let len = arr.length
if (len <= 1) return -1
let left = 0 //左边界
let right = len - 1 //右边界
while (left <= right) {
const mid = Math.floor((left + right) / 2) //计算中间位置
if (target > arr[mid]) {
left = mid + 1 //则将左边界设为中间位置的右侧
} else if (target < arr[mid]) {
right = mid - 1 //否则将右边界设为中间位置的左侧
} else {
if (mid === 0 || arr[mid - 1] < target) return mid
// 当 target=== arr[mid]时、如果 mid为0或者前一个数比 target 小那么就找到了第一个等于给定值的元素,直接返回
right = mid -1 //// 否则高位下标为中间下标减1,继续查找
}
}
return -1 //若没有找到目标元素则返回-1
}
const arr = [1, 4, 5, 6, 11, 11]
console.log(BinarySearch(arr, 11)) //4
查找最后一个值等于给定值的元素
- 有序数据集合中存在重复的数据
const BinarySearch = (arr, target) => {
//arr 待排序数组、target 目标数据
let len = arr.length
if (len <= 1) return -1
let left = 0 //左边界
let right = len - 1 //右边界
while (left <= right) {
const mid = Math.floor((left + right) / 2) //计算中间位置
if (target > arr[mid]) {
left = mid + 1 //则将左边界设为中间位置的右侧
} else if (target < arr[mid]) {
right = mid - 1 //否则将右边界设为中间位置的左侧
} else {
if (mid === 0 || arr[mid + 1] !== target) return mid
// 当 target === arr[mid]时,若mid为0或者后一个数不等于 target 那么就找到了最后一个等于给定值的元素,直接返回
// 这里不能取a rr[mid + 1] > target 可能会存在边界问题
left = mid + 1 // 否则低位下标为中间下标加1,继续查找
}
}
return -1 //若没有找到目标元素则返回-1
}
const arr = [1, 4, 5, 6, 11, 11]
console.log(BinarySearch(arr, 11)) //5
查找第一个大于等于给定值的元素
- 有序数据集合中存在重复的数据
const BinarySearch = (arr, target) => {
//arr 待排序数组、target 目标数据
let len = arr.length
if (len <= 1) return -1
let left = 0 //左边界
let right = len - 1 //右边界
while (left <= right) {
const mid = Math.floor((left + right) / 2) //计算中间位置
if (target <= arr[mid]) {
// 如果 midIndex 为0或者前一个数小于 target 那么找到第一个大于等于给定值的元素,直接返回
if (mid === 0 || arr[mid - 1] < target) return mid
right = mid - 1// 否则高位下标为中位下标减1
} else {
left = mid + 1
}
}
return -1 //若没有找到目标元素则返回-1
}
const arr = [1, 4, 5, 6, 7, 8, 11, 11, 11]
console.log(BinarySearch(arr, 8)) //5
查找最后一个小于等于给定值的元素
- 有序数据集合中存在重复的数据
const BinarySearch = (arr, target) => {
//arr 待排序数组、target 目标数据
let len = arr.length
if (len <= 1) return -1
let left = 0 //左边界
let right = len - 1 //右边界
while (left <= right) {
const mid = Math.floor((left + right) / 2) //计算中间位置
if (target >= arr[mid]) {
// 如果 mid 最后一个或者后一个数大于 target 那么找到最后一个小于等于给定值的元素,直接返回
if (mid === len - 1 || arr[mid + 1] > target) return mid
left = mid + 1 //否则低位下标为中位下标加1
} else {
right = mid - 1
}
}
return -1 //若没有找到目标元素则返回-1
}
const arr = [1, 4, 5, 6, 7, 8, 11, 11, 11]
console.log(BinarySearch(arr, 4)) //1
找到第一个不重复字符的下标或字母
//第一种方法
let str = 'eertre'
const findOneStr = (str) => {
if (!str) return -1
let obj = {} //存储每个字符出现的次数
let arr = str.split('')
arr.forEach(item => {
let val = obj[item]
obj[item] = val ? val + 1 : 1 //val为undefined时表示未存储,obj[item] =1
});
let len = arr.length
for (let i = 0; i < len; i++) {
if (obj[arr[i]] == 1) return i //返回下标 return arr[i]是返回该字符
}
return -1
}
findOneStr(str)//3
//第二种方法
let str = 'eettre'
const fun = (str) => {
let arr = [];
let arr1 = [];
arr = str.split('')
arr.forEach(item => {
let num = str.split(item).length - 1//通过指定分割符合分割字符串
if (num == 1) arr1.push(item)//当只有一个时,切割后的数组长度为2,num会为1,把该字符push到arr1中
});
if (arr1.length !== 0) return arr1[0]//返回该字符串
return '无符合条件的值'
}
console.log(fun(str))//r
比较2个版本号的大小
- 若v1大于v2返回1、v1小于v2返回-1,否则返回0
- 将版本号转成数组,两两比较
const compareVersion = (v1, v2) => {
if (v1 == v2) return 0
const vs1 = v1.split(".").map(e => parseInt(e));//使字符串转成数字
const vs2 = v2.split(".").map(e => parseInt(e));
const length = Math.max(vs1.length, vs2.length);//取最大长风值
for (let i = 0; i < length; i++) {
if (vs1[i] > vs2[i]) return 1;
if (vs1[i] < vs2[i]) return -1
}
if (length == vs1.length) return -1;
return 1;
}
console.log(compareVersion('2.2.3', '2.2.2'))//1
版本号排序
const verList = ['0.1.1', '2.3.3', '0.3002.1', '4.2', '4.3.5', '4.3.4.5', '4.3.5.1']
const sort = (ver) => {
return ver.sort((v1, v2) => compareVersion(v1, v2));//compareVersion是比较两个版本号大小的方法
}
//['0.1.1', '0.3002.1', '2.3.3', '4.2', '4.3.4.5', '4.3.5.1', '4.3.5']
Object.create基本实现原理
//Object.create()实现原理、将传入的对象作为创建的对象的原型
function create(obj) {
function F() {}
F.prototype = obj // 将被继承的对象作为空函数的prototype
// 返回new期间创建的新对象,此对象的原型为被继承的对象, 通过原型链查找可以拿到被继承对象的属性
return new F()
}
reverse底层原理和扩展
// 用于颠倒*数组*中元素的顺序,会改变原数组
Array.prototype.myReverse = function () {
var len = this.length;
for (var i = 0; i < len; i++) {
var temp = this[i];
this[i] = this[len - 1 - i];
this[len - 1 - i] = temp;
}
return this;
}
回文数
字符串的转换
先将数字转成字符串,再经过变成数组,数组反转,数组变成字符串之后,最后比较两组字符串
let num = 123210
const isPalindrome = (x) => {
if (x < 0) return false
let str = '' + x
return Array.from(str).reverse().join('') === str
}
数字转换:求末得尾数, 除10得整数
- 先判断一些特殊情况【 小于0的、 尾数为0的、 小于10的正整数】
- 之后, 将整数反转, 反转前后两个整数是否相等来判断是否为回文整数
这里的反转:将整数求末得到尾数,之后每求一次末,都再原数上添加一位(通过 * 10 来得到),就能得到一个反转的数
计算需要求末的次数: 将整数除10,来计算求模的次数,Math.floor() 返回小于或等于一个给定数字的最大整数
let num = 12321
const isPalindrome = (x) => {
if (x < 0 || (x !== 0 && x % 10 === 0)) return false
if (0 <= x && x < 10) return true
let res = x
let num = 0
while (x !== 0) {
num = x % 10 + num * 10
x = Math.floor(x / 10)
}
return res === num
}
console.log(isPalindrome(num)) //true
最长回文串
let str = 'afrttrr'
const longStr = (str) => {
if (str.length < 2) return str
let res = ' '
let len = str.length
for (let i = 0; i < len; i++) {
helper(i, i) //回文子串长度是奇数 aba
helper(i, i + 1) //回文子串长度是偶数 abba
function helper(m, n) {
while (m >= 0 && n < len && str[m] == str[n]) {
m--
n++
}
//此处是m,n的值循环后,是恰好不满足循环条件的时刻
//此时m到n的距离为n-m+1,但m,n两个边界不能取,所以应取m+1到n-1的区间,长度是n-m-1
if (n - m - 1 > res.length) {
res = str.slice(m + 1, n)//slice也要取(m+1,n-1]这个区间
}
}
}
return res
}
console.log(longStr(str))
继承方式
原型链继承prototype:父类用this声明的属性被所有实例共享
function Parent() {
this.name = 'kevin';
this.age = 18;
this.getName = function () {
console.log(this.name);
}
}
Parent.prototype.getAge = function () {
console.log(this.age);
}
function Child() {}
Child.prototype = new Parent();
var child1 = new Child();
console.log(child1.getName(),child1.getAge()) // kevin,18
child1.name = 'wsn'
child1.age = 20
console.log(child1.getName(), child1.getAge()) // wsn,20
优点:
- fatherFn通过this声明的属性/方法都会绑定在
new期间创建的新对象上。 - 新对象的原型是father.prototype,通过原型链的属性查找到father.prototype的属性和方法
缺点:
- 父类所有引用类型(对象,数组)会被子类共享,更改一个子类的数据,其他数据也受影响
- 子类实例不能给父类参,不够灵活
原型式继承(Object.create())
继承对象原型-Object.create()实现
let oldObj = { p: 1 };
let newObj = cloneObject(oldObj)
oldObj.p = 2
console.log('oldObj newObj', oldObj, newObj)
优点: 兼容性好,最简单的对象继承。
缺点:
- 包含引用类型的属性值始终都会共享相应的值,这点跟原型链继承一样。
- 因为旧对象(oldObj)是实例对象(newObj)的原型,多个实例共享被继承对象的属性,存在篡改的可能。
- 无法传参
借用构造函数继承(call)
function Parent (name) {
this.age = 10
this.name = name;
}
function Child (name) {
Parent.call(this, name);
}
var child1 = new Child('kevin');
console.log(child1.name); // kevin
var child2 = new Child('daisy');
console.log(child2.name); // daisy
//第二种
function fatherFn(...arr) {
this.some = '父类的this属性';
this.params = arr // 父类的参数
}
fatherFn.prototype.fatherFnSome = '父类原型对象的属性或者方法';
function sonFn(fatherParams, ...sonParams) {
fatherFn.call(this, ...fatherParams); // 核心步骤: 将fatherFn的this指向sonFn的this对象上
this.obkoro1 = '子类的this属性';
this.sonParams = sonParams; // 子类的参数
}
sonFn.prototype.sonFnSome = '子类原型对象的属性或者方法'
let fatherParamsArr = ['父类的参数1', '父类的参数2']
let sonParamsArr = ['子类的参数1', '子类的参数2']
const sonFnInstance = new sonFn(fatherParamsArr, ...sonParamsArr); // 实例化子类
console.log('借用构造函数子类实例', sonFnInstance)
- 优点:
- 父类的引用类型不被子类共享,不会互相影响
- 子类可向父类传参
- 缺点:
- 子类只能继承父类通过this声明的属性和方法,不能继承父类prototype上的属性和方法
- 方法都在构造函数中,每次创建实例都会创建一遍方法,会调用2次父类的构造函数,会有2份一样的的属性和方法,影响性能
- 父类方法无法复用:因为无法继承父类的prototype,所以每次子类实例化都要执行父类函数,重新声明父类this里所定义的方法,因此方法无法复用
组合式继承(call+new)
原理:使用原型链继承(new)将this和prototype声明的属性/方法继承至子类的prototype上,使用借用构造函数来继承父类通过this声明属性和方法至子类实例的属性上
function Parent() {
this.age = 10
}
function child() {
this.name = 'test'
Parent.call(this)
}
child.prototype = new Parent()
let o1 = new child()
- 优点:
- 父类通过this声明的属性和方法被子类实例共享的问题(原型链继承中存在的问题)-
- 父类通过prototype声明的属性和方法无法继承的问题(借用构造函数继承存的问题)
- 缺点:
- 2次调用父类函数造成一定性能消耗
- 因调用两次父类,导致父类通过this声明的属性/方法,生成两份的问题。
es6继承
class Parent {
constructor() {
this.age = 10
}
}
class child extends Parent {
constructor() {
super();
this.name = 'test'
}
}
寄生组合式继承(call+寄生式继承(封装继承过程))
原理:
- 使用借用构造函数(call)来继承父类this声明的属性/方法
- 通过寄生式封装函数设置父类prototype为子类prototype的原型来继承父类的prototype声明的属性/方法
function fatherFn(...arr) {
this.some = '父类的this属性';
this.params = arr // 父类的参数
}
fatherFn.prototype.fatherFnSome = '父类原型对象的属性或者方法';
function sonFn() {
fatherFn.call(this, '借用构造继承'); // 核心1 借用构造继承: 继承父类通过this声明属性和方法至子类实例的属性上
this.obkoro1 = '子类的this属性';
}
// 核心2 寄生式继承:封装了son.prototype对象原型式继承father.prototype的过程,并且增强了传入的对象。
function inheritPrototype(son, father) {
const fatherFnPrototype = Object.create(father.prototype); // 原型式继承:浅拷贝father.prototype对象 father.prototype为新对象的原型
son.prototype = fatherFnPrototype; // 设置father.prototype为son.prototype的原型
son.prototype.constructor = son; // 修正constructor 指向
}
inheritPrototype(sonFn, fatherFn)
sonFn.prototype.sonFnSome = '子类原型对象的属性或者方法'
const sonFnInstance = new sonFn();
console.log('寄生组合式继承子类实例', sonFnInstance)
修正constructor指向de原因:
constructor的作用:返回创建实例对象的Object构造函数的引用即返回实例对象的构造函数的引用: let instance = new sonFn() instance.constructor // sonFn函数
constructor的应用场景: 1.当只有实例对象没有构造函数的引用时:某些场景下,对实例对象经过多轮导入导出,不知道实例是从哪个函数中构造出来或者追踪实例的构造函数,较为艰难 let instance = new sonFn() // 实例化子类 export instance; // 多轮导入+导出,导致sonFn追踪非常麻烦,或者不想在文件中再引入sonFn let fn = instance.constructor 2.保持constructor指向的一致性:因此每次重写函数的prototype都应该修正一下constructor的指向,以保持读取constructor行为的一致性寄生组合式继承是最成熟的继承方法, 也是现在最常用的继承方法,众多JS库采用的继承方案也是它。
优点:
- 只调用一次父类fatherFn构造函数。
- 避免在子类prototype上创建不必要多余的属性。
- 使用原型式继承父类的prototype,保持了原型链上下文不变。 子类的prototype只有子类通过prototype声明的属性/方法和父类prototype上的属性/方法泾渭分明
ES5继承与ES6继承的区别:
- ES5的继承实质上是先创建子类的实例对象,再将父类的方法添加到this上。
- ES6的继承是先创建父类的实例对象this,再用子类的构造函数修改this。 因为子类没有自己的this对象,所以必须先调用父类的super()方法
