这是我参与11月更文挑战的第3天,活动详情查看:2021最后一次更文挑战。
theme: juejin
ICCV 2017
Abstract
Gatys方法适应多种风格,但太慢;前馈神经网络快,但风格固定。作者提出一种适应任何风格的实时转换方法,核心为ALADIN层(自适应内容归一化),速度接近前馈方法。
Related Work
Deep generative image modeling
VAE(自动变分编码器),auto_regression model(自回归模型),GAN(生成对抗网络),其中GAN的效果最好
Background
Batch Normalization
BN通过归一化特征图统计量简化训练,一开始是被用来加速判别器的训练,但也被发现在生成图像建模中有用。其统计特征是基于一整个Batch。
BN(x)=γ(σ(x)x−μ(x))+β
其中γ和β是从数据中学习的仿射参数,μ(x)和σ(x)每个channel独立计算,N为Batchsize大小,具体公式如下:
μc(x)=NHW1n=1∑Nh=1∑Hw=1∑Wxnchw
σc(x)=NHW1n=1∑Nh=1∑Hw=1∑W(xnchw−μc(x))2+ϵ
Instance Normalization
IN是针对BN在风格转化中的改进,针对每个通道和每个样本独立计算:
μnc(x)=HW1h=1∑Hw=1∑Wxnchw
σnc(x)=HW1h=1∑Hw=1∑W(xnchw−μnc(x))2+ϵ
Conditional Instance Normalization
改进了仿射变换参数μ(x)和 σ(x) ,不是只学习两个参数,而是两组。用不同的参数组合即可控制生成不同的风格。但它的缺点在于额外的参数量和style个数呈线性关系,所以不适用于对需要大量风格的任务建模。
Adaptive Instance Normalization
x为内容输入,y为样式输入,两者通过以下公式自适应耦合。
AdaIN(x,y)=σ(y)(σ(x)x−μ(x))+μ(y)
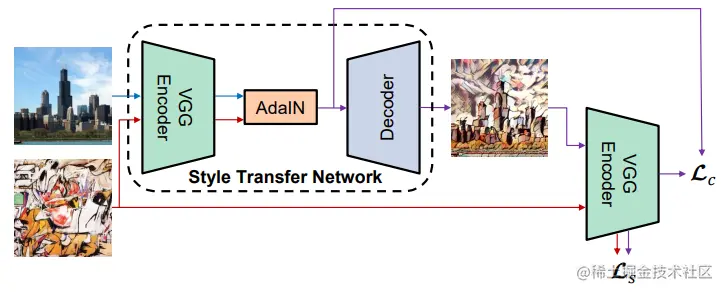
Experimental Setup
Achitecture
Encoder使用预训练过的VGG的前几层,编码后将内容和风格的特征图送入AdaIN产生目标特征图。decoder被随机初始化,在训练中学习将目标特征图映射回图像空间。
Traning
Loss函数是Lstyle和Lcontent的线性加权和,Lcontent依然是欧式距离,但Lcontent不再是Gatys使用的Gram Matrix,作者选择计算原始风格图和生成图在encoder中逐层的均值和方差差异:
Ls=i=1∑L∥μ(ϕi(g(t)))−μ(ϕi(s))∥2+i=1∑L∥σ(ϕi(g(t)))−σ(ϕi(s))∥2 

