这是我参与11月更文挑战的第7天
反向传播 backpropagation —— 一种快速计算代价函数梯度的算法
使⽤矩阵快速计算输出
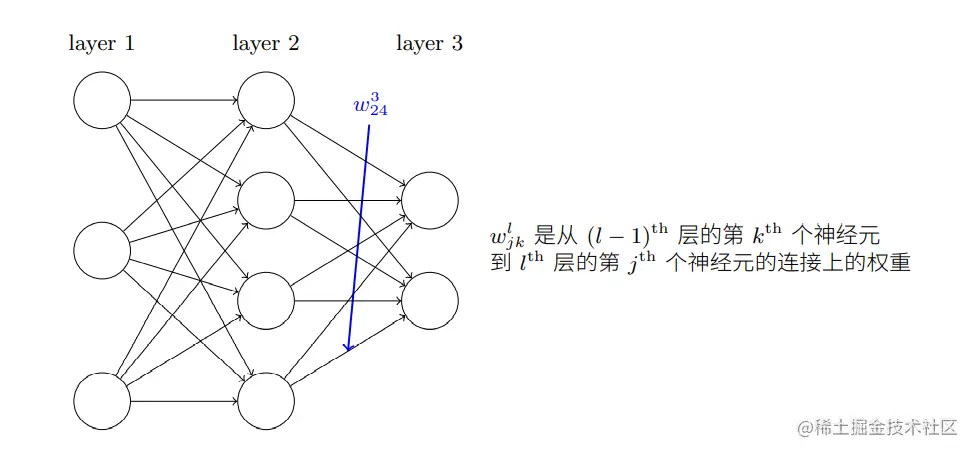
为了解释问题,首先给出神经网络中权重的清晰定义,如下图所示:
同样定义bjl为第l层的第j个神经元的偏置:
基于上面的定义,可以得到第l层的第j个神经元的激活值ajl(这个值和第l−1层的激活值akl−1有关):
ajl=σ(k∑wjklakl−1+bjl)
其中∑kwjklakl−1中的k表示l−1层中的所有神经元数量,对于每一层l定义一个权重矩阵wl,wl中的元素是l−1层到l层连接的权重,因此wjkl可以理解为l−1层中第k个神经元到l层第j个神经元的连接权重。
上面的公式可以简化为:
al=σ(wlal−1+bl)
在计算al需要计算中间量zl=wlal−1+bl,将zl称为l层神经元的带权输入,因此上面的公式又可以简化为al=σ(zl)。
代价函数的两个假设
反向传播算法的目标是计算代价函数C关于两个参数w和b的偏导数∂w∂C,∂b∂C。将C定义为一个二次代价函数:
C=2n1x∑∣∣y(x)−aL(x)∣∣2
n表示训练样本总数,∑x表示遍历了所有样本,y=y(x)是输入x时对应的期望目标输出,L表示网络层数,aL=aL(x)是当输入为x时网络输出的激活值向量。
为了应用反向传播算法,要对代价函数C做两个假设:
- 代价函数可以被写成一个在每个训练样本x上的代价函数Cx的均值C=n1∑xCx,其中每个独立样本的代价为Cx=21∣∣y−aL∣∣2。
- 代价函数可以写成神经网络的输出函数:cost C=C(aL),在这个假设下Cx可以进一步写成:
C=21∣∣y−aL∣∣2=21j∑(yj−ajL)2
背景知识 hadamard乘积/schur乘积: s⊙t
s⊙t表示按元素乘积,(s⊙t)j=sjtj,如下所示:
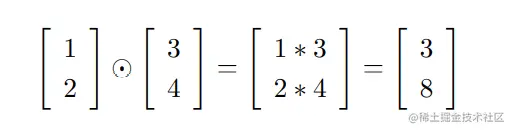
微分、梯度和梯度下降的关系
四个基本公式
反向传播算法的核心是计算偏导数∂wjkl∂C,∂bjl∂C,为达目的首先引入中间量δjl,表示第l层第j个神经元上的误差:
δjl=∂zjl∂C
这个公式基于一个启发式的认识,即∂zjl∂C是神经元误差的度量。
反向传播基于四个基本公式,这些公式让我们可以计算误差和代价函数梯度。
公式1
输出层误差δL的公式:
δjL=∂ajl∂Cσ′(zjL)(1)
公式中∂ajl∂C表示代价C随着第l层第j个神经元输出的激活值的变化而变化的速率,σ′(zjL)表示激活函数σ在zjL处的变化速率。对于二次代价函数C=21∑j(yj−aj)2,∂ajl∂C=(aj−yj)。
为方便计算将公式(1)重写为矩阵形式:
δL=∇aC⊙σ′(zL)
带入二次代价函数的偏导计算得到:
δL=(aL−y)⊙σ′(zL)
公式2
使用下一层的误差δl+1来表示当前层的误差δl:
δl=((wl+1)Tδl+1)⊙σ′(zl)(2)
公式(2)给出了由下一层误差推导当前层误差的方法,这就是反向传播中反向的含义,即可以将其看作沿着⽹络反向移动误差,通过组合公式(1)和公式(2)可以实现计算任意层的误差。
公式3
代价函数和网络中任意偏置相关的变化率:
∂bjl∂C=δjl(3)
公式(3)证明误差δjl和偏导数值∂bjl∂C完全一致。
公式4
代价函数和任何一个权重相关的变化率:
∂wjkl∂C=akl−1δjl(4)
公式(4)给出了偏导数∂wjkl∂C的计算方法,它可以简化为:
∂w∂C=ainδout
ain表示权重为w的链路上的输入激活值,δout表示权重为w链路上的输出误差,如下图所示:
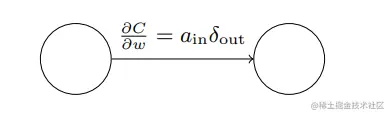
S型函数的特征令σ在接近0或1时变化会非常小,这也会让权重学习变得缓慢,对于这样的情形,称为输出神经元已经饱和了,继而权重学习会终⽌(或者学习⾮常缓慢),从上面的公式可以看出学习的速率和σ′有关。
四个公式的证明
背景知识
多元微积分链式法则公式:
dtdw=i=1∑n∂xi∂wdtdxi
公式1证明
回忆输出误差δ的定义:
δjL=∂zjL∂C
基于上述背景知识可以将公式1改写为:
δjL=k∑∂akL∂C∂zjL∂akL
k表示输出层的所有神经元,第k个神经元的akL只依赖于k=j时的输入权重zjL,也就是说k=j时∂zjL∂akL不存在,基于前面的理论,上面的公式可以化为:
δjL=∂ajL∂C∂zjL∂ajL
基于ajL=σ(zjL)上面公式的右边可以写为σ′(zjL),因此可以得到公式1:
δjL=∂ajl∂Cσ′(zjL)(1)
公式2证明
继续延伸误差δ:
δjl=∂zjl∂C
依旧用链式法则,公式2的核心思想是用下一层误差表示当前误差,因此要想办法引入δkl+1,而δkl+1=∂zjl+1∂C,显然要想办法引入∂zjl+1到误差公式中:
δjl=∂zjl∂C=k∑∂zkl+1∂C∂zjl∂zkl+1=k∑∂zjl∂zkl+1δkl+1
由z的定义可得:
zkl+1=j∑wkjl+1ajl+bkl+1=j∑wkjl+1σ(zjl)+bkl+1
计算∂zjl∂zkl+1得到:
∂zjl∂zkl+1=wkjl+1σ′(zjl)
计算过程可以用数学归纳法证明,过程如下:
当j=1时:
∂z1l∂zkl+1=wk1l+1σ′(z1l)
当j=2时:
∂z2l∂zkl+1=wk2l+1σ′(z2l)
当j=m时:
∂zml∂zkl+1=wkml+1σ′(zml)
证明完毕
综合上述公式可以得到公式2:
δjl=k∑wkjl+1δkl+1σ′(zjl)=((wl+1)Tδl+1)⊙σ′(zl)
公式3的证明
∂bjl∂C=∂zjl∂C∂bjl∂zjl=δjl×1
公式4证明
∂wjkl∂C=∂zjl∂C∂wjkl∂zjl=δjl∂wjkl∂(∑kwjklakl−1+bjl)=akl−1δjl
反向传播算法过程
- 输入x:为输入层设置激活值a1
- 前向传播:对于从第二层开始的l=2,3,4...,L计算中间值zl=wlal−1+bl和al=σ(zl)
- 输出层误差δL:计算最后一层(输出层)误差δL=∇aC⊙σ′(zL)
- 反向误差传播:基于δL逆推前面层的误差(l=L−1,L−2,...,2),计算δl=((wl+1)Tδl+1)⊙σ′(zl)
- 输出:计算代价函数梯度,即∂bjl∂C=δjl、∂wjkl∂C=akl−1δjl。
在反向传播算法的基础上应用梯度下降方法更新参数过程:

算法的实现
def backprop(self,x,y):
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
activation = x
activations = [x]
zs = []
for b, w in list(zip(self.biases, self.weights)):
z = np.dot(w, activation) + b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
delta = self.cost_derivative(activations[-1], y) * sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
for l in range(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l + 1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l - 1].transpose())
return nabla_b, nabla_w


