

宏任务: 执行js脚本是一个宏任务, ui渲染 ajax, 定时器,事件, MessageChannel, setImmediate 宏任务队列 “队列只用有一个”
微任务: promise mutationObserver
const fs = require('fs').promises; // 将fs中的所有对象都转变成promise
fs.readFile('./a.txt','utf8').then((data)=>{
console.log(data);
})
function promisify(fn){ // 将node异步api转换成 promise写法
return function (...args){
return new Promise((resolve,reject)=>{
fn(...args,function(err,data){
if(err) return reject(err);
resolve(data);
})
})
}
}
// 最早异步 回调 -> promise (基于回调的) -> generator 生成器
// 生成器就是生成迭代器的 迭代器的含义就是 可以拥有迭代方法的
// Array.from 将类数组 转化成数组 拓展运算符必须要求对象是可以被迭代的
// function* read() { // 这就表示他是一个generator函数, 配合yield使用
// yield 'react'
// yield 'vue'
// yield 'node'
// }
// let it = read();
// let done = false
// do{
// let {value,done:flag} = it.next();
// console.log(value);
// done = flag
// }while (!done)
// console.log(it.next()); // 特点就是碰到yield 就停止
console.log([...{
0:1,
1:2,
2:3,
lenght:3,
[Symbol.iterator]: function* () {
}
}]);
// console.log([
// ...{
// 0: 1,
// 1: 2,
// 2: 3,
// length: 3,
// [Symbol.iterator]: function* () {
// let i = 0;
// while (i !== this.length) { // 怎么看this 谁调用的方法this 就是谁
// yield this[i++]
// }
// // 迭代器函数返回会一个对象 对象中有next方法 方法中返回value和done
// // let i = 0;
// // return {
// // next: () => {
// // // 迭代函数 每次迭代都会调用next方法
// // return {
// // // 对象里有value和done
// // value: this[i],
// // done: i++ == this.length,
// // };
// // },
// // };
// },
// },
// ]);
// function* read(){
// let a = yield 'node';
// console.log(a,52)
// let b = yield 'react';
// console.log(b,53)
// let c = yield 'vue'
// console.log(c)
// }
// let it = read();
// console.log(it.next()) // 第一次传递参数是没有任何意义的
// console.log(it.next('xxx')); // next传递的参数, 是可以赋予给上一次yield的返回值
// console.log(it.next('ooo')); // next传递的参数, 是可以赋予给上一次yield的返回值
// console.log(it.next('qqq')); // next传递的参数, 是可以赋予给上一次yield的返回值
这是co的写法
const fs = require("fs").promises;
function* read() { // 生成器 固定写法 加个*
// 很像同步的
let out1 = yield fs.readFile("a.txt", "utf8");
let out2 = yield fs.readFile(out1, "utf-8");
return out2;
}
function co(it){
return new Promise((resolve, reject)=>{
function next(data) {
let { value, done } = it.next(data);
if(done) {
return resolve(value);
}
Promise.resolve(value).then(data=>{
next(data)
});
}
next();
});
}

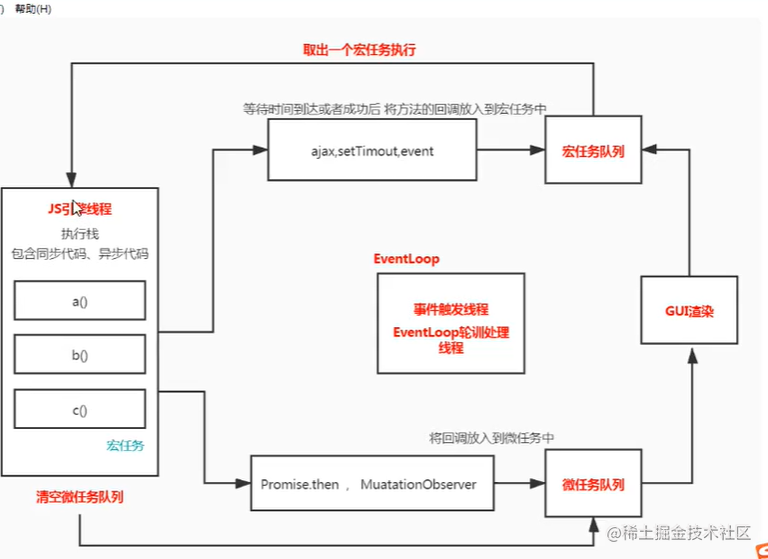
请看一道题
console.log(1);
async function async() {
console.log(2);
await console.log(3); // Promise.resolve(console.log(3)).then(()=>{console.log(4)})
console.log(4)
}
setTimeout(() => {
console.log(5);
}, 0);
const promise = new Promise((resolve, reject) => {
console.log(6);
resolve(7) // 立刻执行 status = fulfilled
})
promise.then(res => {
console.log(res)
})
async();
console.log(8)
function fn1() {
console.log('listener1');
Promise.resolve().then(() => console.log('micro task1'))
}
function fn2() {
console.log('listener2');
Promise.resolve().then(() => console.log('micro task2'))
}
// 事件是宏任务 宏任务的执行顺序是 1个个执行
// button.click(); // 没有基于宏任务 fn1() fn2() 直接就执行了
fn1()
fn2()
浏览器中的全局对象 window
服务端可以直接访问global
// let r = fs.readFileSync('./note1.md','utf8');
// let exists = fs.existsSync('./note1.md') ;// 这个方法的异步方法被废弃了 (异步的回调中 存在不存在,node中要求 error-first)
// console.log(exists)
console.log(path.join(__dirname,'a','b','c','/')); // a\b\c\ 拼接路径的
console.log(path.resolve(__dirname,'a','b','c')); // 解析出绝对路 也具备拼接的功能
console.log(path.dirname(__filename)); // __filename __dirname 取父路径的
console.log(path.extname('a.min.js')); // 取扩展名 都是最后一个
console.log(path.basename('a.min.js','.js'))
// eval 会引用上级作用域的变量 适合简单的js执行 不依赖上下文变量
// new Function () 会创造一个和全局平级的执行环境 也会引用上级变量
const vm = require('vm'); // 虚拟机模块 a b 两个模块没有关系
vm.runInThisContext('console.log(a)'); // 实现一个 安全的执行,但是挂载全局上已经可以获取到
// 我期望执行代码的时候 在一个干净的环境下执行代码 而不依赖当前的上下文
我们看看e.js的实现原理
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<%=name%> <%=age%>
<%arr.forEach(item=>{%>
<a href=""><%=item%></a>
<%})%>
</body>
</html>
// const ejs = require('ejs');
const fs = require('fs').promises
const path = require('path');
const ejs = {
async renderFile(filePath, data) {
let template = await fs.readFile(filePath,'utf8');
let head = 'let str = ``;\r\n';
head += 'with(obj){\r\nstr += `'
let content = template.replace(/<%=(.+?)%>/g,function(){
// <%=xxx%> -> ${xxx}
return '${' + arguments[1] + '}'
})
content = content.replace(/<%(.+?)%>/g,function(){
return '`\r\n'+arguments[1] + '\r\nstr+=`'
});
let tail = '`}\r\n return str'
return new Function('obj',head + content + tail)(data);
}
}
ejs.renderFile(path.resolve(__dirname, 'template.html'), { name: 'zf', age: 12,arr:[1,2,3] }).then(data => {
console.log(data)
})
// 模板引擎的实现原理 就是 with + new Function (掌握模板引擎的实现原理 都是这个套路 )
// commonjs 实现原理
// 1.with解决的是在模板中取值的问题
// 2.new Function 就是让代码传参 ,返回最终的结果
比如// let obj = {
// a:1
// }
// setTimeout(()=>{
// obj.a++;
// },1000);
var a = 100;
setTimeout(()=>{
a++;
},1000);
module.exports = a;
这种情况如果a是常量,那么导入的话不会发生变化,如果a是基本数据类型,那么在另一个文件require的值不会发生变化,如果a是一个对象就会发生变化,
默认是exports = module.exports = 'b';
= {};
如果exports = {a:1}
相当于module.exports还是{},给如果exports换了一个新房子为{a:1}
同理
exports = 'a'最终也是导入的{},因为module.exports还是{}
那么问题就来了一般导出都是module.exports,那么要exports有啥用呢?
如果这个时候导出的是对象,那么作用就来了
exports.a = 1;exports.b = 1;
相当于和module.exports时一个房子,所以这样导出很有效,就不用
module.exports.a = 1; module.exports.b = 1;
common.js的实现原理
const path = require('path');
const fs = require('fs')
const vm = require('vm')
function Module(id) {
this.id = id;
this.exports = {}
}
Module._extensions = {
'.js'(module){
let source = fs.readFileSync(module.id); // js中的源代码
let wrapper = ['(function(exports,module,require,__dirname,__filename){','})']
const script = wrapper[0] + source + wrapper[1]; // 字符串
let fn = vm.runInThisContext(script); // 字符串转成的函数
let exports = module.exports
let filename = module.id
let dirname = path.dirname(filename)
// 执行此函数 用户会自动的给module.exports 赋值
// 此函数执行的时候 this 发生了变化
fn.call(exports,exports,module,req,dirname,filename); // 用户module.exports = 'hello'
},
'.json'(module){
let content = fs.readFileSync(module.id); // content 就是json中的内容
module.exports = JSON.parse(content)
}
}
Module._resolveFilename = function (id) {
let filepath = path.resolve(__dirname,id);
if(fs.existsSync(filepath)) return filepath
let exts = Object.keys(Module._extensions);
for(let i = 0; i < exts.length;i++){
let p = filepath + exts[i];
if(fs.existsSync(p)) return p
}
// 不存在尝试添加后缀 , .json ,json
throw new Error('模块不存在')
}
Module.prototype.load = function(){ // 加载模块
let extension = path.extname(this.id);
Module._extensions[extension](this)
}
Module._cache = {}; // 全局的缓存区 用来缓存模块的
function req(id) {
// 将路径变成绝对路径 进行操作, 可能id 没有后缀 需要依次尝试追加后缀 .js .json
let filepath = Module._resolveFilename(id); // 根据相对路径获取一个绝对路径
if(Module._cache[filepath]){ // 如果缓存中有 直接使用上一次缓存的结果
return Module._cache[filepath].exports
}
let module = new Module(filepath);
Module._cache[filepath] = module; // 将模块进行缓存
module.load(); // 加载模块
return module.exports; // 最终返回的是module.exports
}
let r = req('./a.js');
r = req('./a.js');
r = req('./a.js');
const EventEmitter = require('./events');
// const {inherits} = require('util')
// on 订阅 emit 发布 once 订阅一次 off 移除监听 removeAllListeners 删除所有监听
class Girl extends EventEmitter {
}
let girl = new Girl();
let pending = false
girl.on('newListener', function (eventName) { // 当触发这个回调的时候 ,绑定的事件还未绑定成功
if (!pending) { // vue的nextTick flushSqudualerQueue 异步更新原理
Promise.resolve().then(() => {
girl.emit(eventName); // [] ['哭'] [库,吃] ['哭',’吃‘,’购物‘]
pending = false;
})
pending = true;
}
});
girl.on('我失恋了', function () { // {'我失恋了':[fn1,fn2,fn3],结婚了:[fn]}
console.log('哭')
})
girl.on('我失恋了', function () {
console.log('吃')
})
function shopping () {
console.log('购物')
}
// girl.once('我失恋了',shopping )
girl.off('我失恋了',shopping )
// [fn1,fn2,fn3]
// 只要你绑定了这个事件 我就让你自动触发
girl.emit('我失恋了')
girl.emit('我失恋了')
const fs = require('fs');
// process
// 写命令行工具的时候 找运行的配置文件 webpack (会去当前目录下查找这个webpack.config.js 文件)
// vite vite.config,js
// 环境变量的设置是在当前命令中设置的,切换到其他地方执行就不一样了
const path = require('path');
console.log(process.cwd(), path.resolve()); // 如果为了方便 完全可以只使用process.cwd 获取路径
// global上的属性 可以直接访问process pwd print working directory
如果写一个.env的文件,需要怎么加到环境变量里(process.env里)?
const res = fs.readFileSync('.env', 'utf-8');
process.env[res.split('=')[0]] = res.split('=')[1];
console.log(process.env.VUE_APP_TITLEA, 'ee');
// env webpack 当前的是环境变量 enveriorment
// axios baseURL npm install cross-env webpack vite rollup
let baseURL = ''
if (process.env.VUE_APP_TITLEA === 'dev') {
baseURL = 'http://localhost:3000'; // 服务器在本地市话是3000
} else {
baseURL = 'http://39.106.175.189'
}
console.log(baseURL); // 先设置环境变量在使用 在windows下可以使用 set 命令 对于mac export
// set xxx=1
// export xxx=1
// corss-env
// argv 通过argv属性来获取用户传递的参数 webpack --config a 1 --port 3000 ...
// 默认argv是一个数组 1.可执行文件 2.执行的文件 other 所有用户的参数。。。。
// let args = process.argv.slice(2);
// webpack --watch
// let r = args.reduce((memo,current,index,arr)=>{
// if(current.startsWith('--')){
// memo[current.slice(2)] = arr[index+1];
// }
// return memo
// },{})
// console.log(r); // commander 可以实现命令行工具
// 组成一个用户参数列表
const { program } = require('commander'); // 用别人包来解析参数
const pkg = require('./package.json')
program.name('zf');
program.usage('xxx') //这个name与usage是链式调用 只能设置一个name与usage
program.version(pkg.version) --Version和--Help是内置的
直接node 文件 --Version 就可以查到
program.option('-c|--config <x>','config file') 相当于 在终端执行-c
program.option('-p|--port <c>','sever port')
program.command('create [projectName]').action((args)=>{
console.log(args)
})
// --config --port
program.on('--help',function(){
console.log('\r\n my help')
})
program.parse(process.argv)
console.log(program.opts()); // commander 内部就是解析process.argv的
// process.env
// process.argv
// process.cwd
// process.nextTick
接下来看一看进制的讲解
// --------------------------------
Buffer.prototype.split = function (sep) { // sep 做分隔符
// buffer 和字符串的长度不一样
sep = Buffer.isBuffer(sep) ? sep : Buffer.from(sep);
let offset = 0; // 不停的修改
let position = 0; // 找到的位置
const arr = [];
while (-1 !== (position = this.indexOf(sep, offset))) {
arr.push(this.slice(offset,position));
offset = position + sep.length
}
arr.push(this.slice(offset));
return arr;
}
let buffer10 = Buffer.from('**|**|**'); // 分割buffer -> 分割成buffer[]
// console.log(buffer10.indexOf('我',7)); // 返回的是字节索引
console.log(buffer10.split('|')) // 实现一个buffer的split方法
// buffer.length !== 字符串长度
// buffer.slice 可以截取buffer, buffer在截取的时候 截取的是内存
// concat 这个用的是最大
// Buffer.isBuffer() 判断是不是buffer
// buffer.indexOf('x',从哪里开始找) 类似于字符串的indexOf
// buffer的使用 没有数组中filter forEach buffer 用法很像数组 也很像 字符串 (字符串具备不可变性)
Buffer.concat = function (list, len = list.reduce((a, b) => a + b.length, 0)) {
let bigBuffer = Buffer.alloc(len);
let offset = 0;
for (let i = 0; i < list.length; i++) {
list[i].copy(bigBuffer, offset);
offset += list[i].length
}
return bigBuffer
}
let bigBuffer2 = Buffer.concat([buf5, buf6]);
console.log(bigBuffer2)
let bigBuffer = Buffer.alloc(6);
buf5.copy(bigBuffer, 0, 0, 2); // 第一次把两个字节拷贝过去
buf6.copy(bigBuffer, 2, 0, 4) // 第二次是把4个字节拷贝过去
console.log(bigBuffer.toString('utf8')); // 拼接后一起消费
// 文件不能太大, 如果文件很大超过了内存大小 就无法读取了
// 一般认为 小于64k的都可以采用这种方式
fs.readFile(path.resolve(__dirname, 'package.json'), (err, data) => {
if (err) return console.log(err);
fs.writeFile(path.resolve(__dirname, 'a.txt'), data, function (err) {
if (err) return console.log(err);
console.log('写入成功')
})
})
一般来说我们先会读流
// 返回的是一个可读流对象
const rs = fs.createReadStream(path.resolve(__dirname,'a.txt'),{ // 可读流一次可以读取64k
flags: 'r',// fs.open
encoding:null, // 默认就是buffer
mode:0o666, // fs.open(mode)
autoClose: true, // 读取后是否自动关闭
emitClose:true, // 是否内部触发一个事件 emit('close')
start:0, // 从哪到哪
end:5, // 0 - 5 6个字节 包前又包后
highWaterMark:2,// 64k 每次读取多少个 默认64k
});
rs.on('open',function(fd){
console.log(fd);
})
// 默认会在内部递归的将数据读取完毕
rs.on('data',function(data){ // fs.read() -> rs.emit('data',读取到的数据)
console.log(data)
// 我们希望能控制读取的速率 ,读完后 等我写入到文件中了 在去读取
rs.pause(); // 不会触发data事件 配合可写流
})
rs.on('end',function(){ // 当指定的内容读取完毕后 会触发end事件 rs.emit('end')
console.log('读取完毕')
})
rs.on('close',function(){ // rs.emit('close')
console.log('close');
clearTimeout(timer)
})
rs.on('error',function(){ // rs.emit('error')
console.log('error')
})
let timer = setInterval(()=>{
rs.resume(); // 1s 后恢复读取 再触发data事件
},1000)
来看下WriteStream
const ws = new WriteStream(path.resolve(__dirname,'b.txt'),{
// 可读流的 highWaterMark 每次读取多少个 可写流: 我期望每次能写入多少
highWaterMark: 3, // 默认值是16k
flags:'w', // 写入的标识
encoding:'utf8',
start:0, // 开始写入的位置 没有end
emitClose:true // 是否触发close
});
// 我期望 用3个内存大小的字节 来进行整个写入的操作
let i = 0; // 0-9
function write(){
let flag = true;
while(flag && i<=9){
flag = ws.write(i++ + '','utf8',()=>{
console.log( '写入了')
}); // 当写入的时候达到了预期的时候 此时flag 就会变为false
}
if(i > 9){
ws.end('ok');
}
}
write();
ws.on('drain',()=>{ // 等待内存全部写入到文件中后,会触发drain. drain事件只有当达到预期值 (并且消耗掉)的时候才能触发
console.log('drain')
write();
})
其实在工作中 我们用的最多的就是
const ReadStream = require('./readstream');
const WriteStream = require('./writeStream');
const path = require('path');
const rs = new ReadStream(path.resolve(__dirname,'a.txt'),{
highWaterMark:4 // 64k
});
const ws = new WriteStream(path.resolve(__dirname,'b.txt'),{
highWaterMark:1 // 16k
})
// pipe 可以实现 从 a->b 效果是读一点写一点 是异步的
rs.pipe(ws);
当然还有其它写法,了解一下就行
const { Readable, Writable } = require('stream');
class MyReadStream extends Readable {
_read() {
this.push('123');
this.push(null); // push null 后会调用end方法
}
}
let mrs = new MyReadStream();
mrs.on('data', function (chunk) { // 内部默认调用的是Readable中的.read , 会去调用自己写的 _read
console.log(chunk)
})
mrs.on('end', function () {
console.log('读取完毕了')
})
// 可读流内部实现原理 就是 内部创建后 当用监听了data事件 就会触发Readable 对应的read方法
// 默认会调用子类的_read 方法 (具体实现你可以自己实现 只是fs中用了fs.read方法)
// 将自己造的数据放到Readable.push方法中, 内部会自动触发data事件 将结果抛出来
class MyWriteStream extends Writable {
_write(chunk, encoding, withClearBufferCallback) {
console.log(chunk,'---'); // 第一次真的调用的是 _write 后续都放到缓存中了
withClearBufferCallback();
}
}
let mws = new MyWriteStream();
mws.write('ok')
mws.write('ok')
mws.write('ok')
mws.write('ok')
mws.end('123')
这个就是链表
// 队列 栈 链表 线性结构
class Node {
constructor(element, next) {
this.element = element; // 存放当前节点的内容
this.next = next; // 下一个指针
}
}
class LinkedList {
constructor() {
this.head = null;
this.size = 0; // 当前链表存放数据的个数
}
getNode(index) {
let current = this.head; // 根据头部一直向下查找
for (let i = 0; i < index; i++) {
current = current.next;
}
return current; // 找到所引处返回
}
add(element, index = this.size) {
if (index === 0) {
let head = this.head; // 先把老的头部拿到
this.head = new Node(element, head); // 创造新节点替换掉老节点
} else {
// 通过索引添加 要循环找到对应的元素在添加
let prevNode = this.getNode(index - 1);// 获取前一个节点
prevNode.next = new Node(element, prevNode.next);
}
this.size++;
}
remove(index) {
let node;
if (index == 0) {
if (this.head) {
node = this.head;
this.head = this.head.next; // 将头部的内容指向下一个节点 , 第一个就删掉了
this.size--;
}
} else {
let preveNode = this.getNode(index - 1);
node = preveNode.next; // 要删除的节点
preveNode.next = node.next;
this.size--;
}
return node;
// 删除返回删除后的节点
}
reverse1() {
let head = this.head;
if (head == null || head.next == null) return head; // 一个节点没有, 或者就一个节点
let newHead = null;
while (head) { // 把链表的内容 整个搬运一遍,什么时候没有了就没了
let temp = head.next; // 先把除了对一个节点的节点保存一下
head.next = newHead; // 将第一个头 指向新接的节点
newHead = head; // 让新链表的头指向这个节点
head = temp; // 将原来的链表更新
}
return newHead
}
}
来看下二叉树
class Node {
constructor(element, parent) {
this.element = element;
this.parent = parent;
this.left = null;
this.right = null;
}
}
class BST {
constructor(compare) {
this.size = 0;
this.root = null;
let defaultCompare = this.compare;
this.compare = compare || defaultCompare;
}
compare(e1, e2) {
return e1 - e2
}
add(element) {
if (this.root === null) {
this.root = new Node(element, null);
} else {
// this.insertNode(this.root, element)
let current = this.root;
let parent;
let v;
while (current !== null) {
// v 决定是放左边还是放右边
v = this.compare(element, current.element); // 用当前的插入元素 和 根元素比较
parent = current; // parent决定了把数据放在谁的下面
if (v < 0) {
current = current.left; // 如果比当前节点小的 放在左边
} else if (v > 0) {
current = current.right
} else {
current.element = element; // 直接用新的覆盖掉老的
}
}
// current = null
let node = new Node(element, parent)
if (v < 0) {
parent.left = node
} else {
parent.right = node
}
}
this.size++;
}
// 先序遍历
prevOrderTraversal(visitor) { // 自己实现以下 非递归的 先序中序 后续
let flag = false
const traversal = (node) => {
if (node == null || flag) return;
flag = visitor.visit(node.element); // 当前 左边 右边
traversal(node.left);
traversal(node.right)
}
traversal(this.root);
}
inorderTraversal(visitor) {
let flag = false
const traversal = (node) => {
if (node == null || flag) return;
traversal(node.left); // 左边已经有节点是6 了 就不要在继续访问左边了 8 6
if (flag) return
flag = visitor.visit(node.element); // 左边 当前 右边
traversal(node.right)
}
traversal(this.root);
}
postorderTranversal(visitor) {
let flag = false
const traversal = (node) => {
if (node == null || flag) return;
traversal(node.left); // 右边已经有节点是6 了 就不要在继续访问左边了
traversal(node.right) // 左边 右边中间
if (flag) return
flag = visitor.visit(node.element);
}
traversal(this.root);
}
levelOrderTraversal(visitor) {
if (this.root == null) return;
let stack = [this.root];
let index = 0;
let currentNode;
while (currentNode = stack[index++]) {
if (visitor.visit(currentNode.element)) return;
if (currentNode.left) {
stack.push(currentNode.left)
}
if (currentNode.right) {
stack.push(currentNode.right)
}
}
}
invert() {
const traversal = (node) => {
if (node == null ) return;
const temp = node.left; // 左右交换
node.left = node.right;
node.right = temp;
traversal(node.left); // 左右交换了 , 接着交换
traversal(node.right)
}
traversal(this.root);
}
}
let bst = new BST((e1, e2) => {
return e1.age - e2.age
});
// 二叉搜索树的特点是存储的数据 必须有课比较性
// 数据存储的类型 必须是数字吗? sort Api 支持数字的排序 传入排序器
[{ age: 10 }, { age: 8 }, { age: 6 }, { age: 19 }, { age: 15 }, { age: 22 }, { age: 20 }].forEach(item => {
bst.add(item);
})
bst.levelOrderTraversal({
visit(element) { // 后面我们使用babel的时候 遍历语法树的时候 写法就是这样的
console.log(element)
return element.age == 6; // 返回true 则停止遍历
}
});
// diff算法 目录操作 路由配置 权限配置 ---- 树 常用的就是遍历树 和 格式化数据
// 如何反转二叉树 ? homebrew
bst.invert();
console.dir(bst,{depth:20})
第二种写法
class Node {
constructor(element, parent) {
this.element = element;
this.parent = parent;
this.left = null;
this.right = null;
}
}
class BST {
constructor(compare) {
this.size = 0;
this.root = null;
let defaultCompare = this.compare;
this.compare = compare || defaultCompare;
}
compare(e1, e2) {
return e1 - e2
}
add(element) {
if (this.root === null) {
this.root = new Node(element, null);
} else {
// this.insertNode(this.root, element)
let current = this.root;
let parent;
let v;
while (current !== null) {
// v 决定是放左边还是放右边
v = this.compare(element, current.element); // 用当前的插入元素 和 根元素比较
parent = current; // parent决定了把数据放在谁的下面
if (v < 0) {
current = current.left; // 如果比当前节点小的 放在左边
} else if (v > 0) {
current = current.right
} else {
current.element = element; // 直接用新的覆盖掉老的
}
}
// current = null
let node = new Node(element, parent)
if (v < 0) {
parent.left = node
} else {
parent.right = node
}
}
this.size++;
}
// 这里想用非递归的方式 遍历树 可以采用栈的形式来实现 , 前序遍历 将左右都存放起来 ,弹出左边,最后弹出右边
prevOrderTraversal(visitor) {
if (this.root == null) return;
let stack = [this.root]; // 先进入的后出
// 按照存放的顺序 去入栈,之后倒叙出栈
// 队列 先进的先出 层序遍历
// 栈 是先进的后出 后进的先出
while (stack.length > 0) { // 栈中有内容 我们就不停的循环
let node = stack.pop();
if (visitor.visit(node.element)) return;
if (node.right !== null) {
stack.push(node.right)
}
if (node.left !== null) {
stack.push(node.left)
}
}
}
// 中序遍历 就是将左边不停的入栈 , 弹出后访问在看有没有右边
inorderTraversal(visitor) {
if (this.root == null) return;
let stack = [];
let node = this.root;// 第一个节点
while (true) {
if (node !== null) {
stack.push(node);
node = node.left; // 不停的找左边
} else if (stack.length === 0) {
return;
} else {
node = stack.pop(); // 弹出来一个就访问一个
if (visitor.visit(node.element)) return; // 交给用户访问节点
node = node.right
}
}
}
// 后续遍历 就是左右都放入 ,先弹出左边,在弹出右边 ,最后访问自己
postorderTranversal(visitor) {
if (this.root == null) return;
let stack = [this.root];
let node;
while (stack.length > 0) {
let current = stack[stack.length - 1]; // 取出最后一个
if ((current.left == null && current.right == null) || (node && node.parent == current)) { // 1永远有左右
node = stack.pop(); // 左边出来
if (visitor.visit(node.element)) return
} else {
if (current.right !== null) { // 有右边 我就先扔到栈中
stack.push(current.right); // 先将右边放入 先放右在放左 出来的就是左
}
if (current.left !== null) {
stack.push(current.left); // 先将右边放入 先放右在放左 出来的就是左
}
}
}
}
}
let bst = new BST((e1, e2) => {
return e1.age - e2.age
});
[{ age: 11 }, { age: 8 }, { age: 6 },{ age: 7 }, { age: 19 },{age:22},{age:20},{ age: 9 }].forEach(item => {
bst.add(item);
})
bst.inorderTraversal({
visit(element) {
console.log(element)
}
});
接下来来看操作文件目录
// 目录操作
const fs = require('fs');
const path = require('path')
// fs.mkdir (fs.existsSync -> fs.access -> fs.stat 都可以判断文件的存在性 stat用的比较多)
// fs.rmdir (默认支持递归删除)
// 异步api
// mkdir('a/b/c',function(err){ // mkdir -p a/b/c
// console.log(err)
// })
// 删除的过程中需要先删除子目录 在删除 父目录
// dirs = fs.readdirSync('a'); // 只能读取子目录
// dirs = dirs.map((item)=>path.join('a',item)); // a/b a/e a/f a/index.js
// dirs.forEach(item=>{
// let statObj = fs.statSync(item);
// if(statObj.isDirectory()){
// fs.rmdirSync(item)
// }else{
// fs.unlinkSync(item);
// }
// });
// fs.rmdirSync('a')
// fs.readdir 读取子目录
// fs.stat 判断状态 isDirectory isFile
// fs.rmdir 删除目录
// fs.unlink
// fs.acess
// fs.writeFileSync('a/b/c/index.js','aaa')
// (tapble) 目前现在写的是异步串行
这个是异步并行
let { stat, unlink, readdir, rmdir } = require('fs').promises;
async function rmdir4(dir) {
let statObj = await stat(dir) // 如果是文件 删除即可
if (statObj.isFile()) {
await unlink(dir)
} else {
let dirs = await readdir(dir);
// 删除完毕儿子后 删除自己
await Promise.all(dirs.map(item => rmdir4(path.join(dir, item))))
await rmdir(dir);
}
}
// rmdir4('a').then(() => {
// console.log('ok 删除成功')
// }).catch(err=>{
// console.log(err)
// })
// 异步串行 异步并行 这个就是异步串行
function rmdir5(dir) {
let stack = [dir];;
let index = 0;
let current;
while (current = stack[index++]) {
let stats = fs.statSync(current);
if (stats.isDirectory()) {
stack = [...stack, ...fs.readdirSync(current).map(item => path.join(current, item))]
}
}
index = stack.length - 1
while (index >= 0) {
let current = stack[index--];
let stats = fs.statSync(current);
if (stats.isDirectory()) {
fs.rmdirSync(current);
} else {
fs.unlinkSync(current)
}
}
}
rmdir5('a');
说到底如果真的想删除文件夹直接
fs.rmdir('a',{recursive:true})
