

学习MySQL事务思维导图
1. 关于数据库事务
1.1 什么是数据库事务
事务是数据库管理系统(DBMS)执行过程中的一个逻辑单位,有一个有限的数据库操作序列构成。
1.1.1 事务的典型场景
订单表、资金表、物流表,需要让这些操作在一个事务里面完成。当一个业务流程设计多个表的操作的时候,我们希望是要么全部成功,要么都不成功,这个时候我们会启动事务。比如:转账,扣款和到账必须是在一个事务内,要么都成功要么都失败。
@Transactional
<tx:method name="save*" rollback-for="Throwable" />
conn.commit()/conn.rollback()
1.1.2 数据库什么时候会出现事务
它可能包含一系列的DML语句,包括insert、delete、update,单体DDL(create、drop)和DCL(grant、revoke)也会有事务。
MySQL支持事务的存储引擎:InnoDB、NDB
1.2 事务的四大特性ACID
1.2.1 原子性(Atomicity)
Atomicity数据库最小工作单元,不可再分。对数据库一系列操作,要么成功要么失败。不可能出现部分成功或部分失败的情况。如果出现部分失败,必须回滚。
如何做到原子性:原子性在InnoDB里面是通过undo log实现的,它记录了数据修改之前的值(逻辑日志),一旦发生异常,就可以用undo log来实现回滚操作。
1.2.3 一致性(Consistency)
指的是数据库的完整性约束没有被破坏,事务执行的前后都是合法的数据状态。比如主键必须是唯一的,字段长度复合要求。比如A账户向B账户转账1000,B账户只增加了500,这时两个操作都成功了,满足原子性,但是它没有满足一致性,因为它导致了会计科目的不平衡。
1.2.4 隔离性(Isolation)
有了事务的定义以后,在数据库里面会有很多的事务同时去操作同一张表或者同一行数据,必然会产生一下并发或者干扰操作这就是对隔离性的定义。就是有很多个事务对表或者行并发操作,应该是透明、互相不干扰的。通过这种方式,保证业务数据的一致性。
1.4.4 持久性(Durability)
对数据的任意操作,增删改,只有事务提交成功,那么结果就是永久性的,不可能因为系统宕机或者重启了数据库的服务器,他又恢复到原来的状态。这就是事务的持久性。
持久性怎么实现?数据库崩溃恢复(crash-safe)是通过什么实现的? 持久性是通过redo log和double write双写缓冲来实现的,我们操作数据的时候,会先写到内存的buffer pool里面,同时记录redo log,如果在刷盘之前出现异常,在重启后就可以读取redo log的内容,写入到磁盘,保证数据的持久性。当然,恢复成功no的前提是数据页本身没有被破坏,是完整的,这个通过双写缓冲(double buffer write)保证。
原子性,隔离性,持久性,最后都是为了实现一致性。
2. 事务并发问题和SQL92标准
2.1 事务并发带来的问题
2.1.1 脏读
1.事务ID为2673的事务内,内第一次查询id=1的记录,age=16
2.事务ID为2674的事务内,修改id=1的记录,修改age=18
3.事务ID为2673的事务内,第二次查询id=1的记录,得age=18
结论:在一个事务里面,读取到其他事务update且未提交的数据,导致前后两次读取数据不一致,这种事务并发问题叫做脏读。
2.1.2 不可重复读
1.在事务ID为2673的事务内,查询id=1的记录
2.在事务ID为2674的事务内,修改id=1的记录,修改age=18,并且提交事务
3.在事务ID为2673的事务内,第二次查询id=1的记录,得age=18
结论:在一个事务里面,读取到其他事务update/delete且已提交的数据,导致前后两次读取数据不一致,这种事务并发问题叫做不可重复读。
小结:脏读、不可重复读、幻读,都是数据库读一致性问题,都是在一个事务内前后两个读取数据不一致情况。必须有数据库提供一定的事务隔离机制来解决。
2.1.3 幻读
1.在事务ID为2673的事务内,查询age>15的记录,只有一行数据
2.在事务ID为2674的事务内,insert一行数据age=22,并且提交事务
3.在事务ID为2673的事务内,第二次查询age>15的记录,得到两行数据
结论:在一个事务里面,读取到其他事务insert且已提交的数据,导致前后两次读取数据不一致,这种事务并发问题叫做幻读。
2.2 SQL92标准
数据库专家连个制定的一个标准,建议数据库厂商都按照这个标准,提供一定的事务隔离级别,解决事务并发问题,这就是SQL92标准。
官网:www.contrib.andrew.cmu.edu/~shadow/sql…
2.2.1 SQL92标准定义的4个隔离级别
2.2.1.1 Read Uncommitted(未提交读)
一个事务可以读取到其他事务未提交的数据,会出现脏读,所以叫做RU,未解决任何问题。
2.2.1.2 Read Committed(已提交读)
一个事务只能读取到其他事务已提交的数据,不能读取到其他事务未提交的数据,解决脏读问题,但是会出现不可重复读问题。
2.2.1.3 Repeatable Read(可重复读)
一个事务里面多次读取同一行数据的结果是一样的,解决脏读和不可重复读问题,没有定义解决幻读问题。
2.2.1.4 Serializable(串行化)
在这个隔离级别里面,所有的事务都是串行执行的,也就是对数据的操作需要排队,已经不存在事务的并发操作了,所以它解决所有问题。
2.3 InnoDB对四种事务隔离级别的支持
InnoDB支持的四个隔离级别和SQL92定义的级别一直,隔离级别越高,事务的并发就越低。唯一的区别就在于InnoDB在RR的级别就解决了幻读的问题。这个也是InnoDB默认使用RR作为事务隔离级别的原因,既保证数据一致性,又支持较高的并发度。
2.3.1 LBCC
读取数据时,锁定要操作的数据,不允许其他事务修改。这种方案叫做:基于锁的并发控制Lock Based Concurrency Control(LBCC)。
缺点:不支持并发读写操作,极大影响操作数据的效率。
2.3.2 MVCC
在修改数据的时候建立一个备份或者快照,后来的读取,使用快照数返回。这种方案叫做:多版本并发控制Multi Version Concurrency Control(MVCC)。
效果:建立一个快照,同一个事务无论查多少次都是相同的数据。
一个事务能看到的数据版本:
1. 第一次查询之前已经提交的事务的修改
2. 本事务的修改
一个事务不能看见的数据版本:
1. 在本事务第一次查询之后创建的事务(事务ID比当前事务大的事务ID)
2. 活跃的(未提交的)事务的修改
2.3.2.1 Read View(一致性视图)存储内容
- 从数据最早版本开始判断(undo log)
- 数据版本的trx_id=creator_trx_id,本事务修改,可以访问
- 数据版本的trx_id<min_trx_id(未提交事务的最小ID),说明这个版本在生成ReadView已经提交,可以访问。
- 数据版本的trx_id>max_trx_id(下一个事务ID),这个版本是深层ReadView之后才开启的事务建立的,不能访问
- 数据版本的trx_id在min_trx_id和max_trx_id之间,看看是否在m_ids中。如果在,不可以。如果不在,可以。
- 如果当前版本不可见,就找undo log链中的下一个版本。
RR的ReadView是事务第一次查询的时候建立的。(解决幻读)。RC的ReadView是事务每次查询的时候建立的。(未解决幻读)。
2.3.2.2 实现方式
InnoDB为每行记录都实现了两个隐藏字段:
- DB_TRX_ID,6字节:插入或更新行的最后一个事务ID事务编号是自动递增的。
- DB_ROLL_PTR,7字节:回滚指针
2.4 MySQL事务操作
无论在Navicat工具还是在java代码通过API操作,还是加上@Transaction注解或者AOP配置,其实最终都是发送一个指令到数据库去执行,Java的JDBC只不过是把这些命令封装起来了。
2.4.1 查看和设置MySQL数据库隔离级别
2.4.1.1 查看数据库版本
2.4.1.2 查看存储引擎
2.4.1.3 查看数据库事务隔离级别
2.4.1.4 设置数据库隔离级别
// 查看数据库隔离级别
show global variables like "tx_isolation";
// 设置数据库隔离级别
set global transaction isolation level read uncommitted;// 未提交读
set global transaction isolation level read committed;// 已提交读
set global transaction isolation level repeatable read;// 可重复读
set global transaction isolation level serializable;// 串行化
2.4.2 更新语句自动开启和提交事务
执行更新语句会自动开启一个事务,并且自动提交,所以最终写入了磁盘,这是开启事务的第一种方式。InnoDB里面有一个autocommit的参数(分成两个级别,session级别和global级别)默认值是ON。当它的值是true/on,在操作数据时,会自动开启和自动提交事务。否则,如把autocommit设置成false/off,数据库的事务就需要手动开启和手动结束。
2.4.3 手动开启事务的两种种方式
2.3.3.1 begin;
begin;
update student set sname = 'xxx' where id =1;
rollback;//commit;
2.4.3.2 start transaction;
start transaction;
update student set sname = 'xxx' where id =1;
rollback;//commit;
2.4.3.3 结束事务
事务结束,锁才会释放
- 提交
commit - 回滚
rollback - 连接断开
3. InnoDB锁
3.1 锁基本类型
官网把锁分成8类。吧前面两个行级别锁:共享锁和排它锁(Shared and Exclusive Lock),和两个表级别锁:共享意向锁和排他意向锁(Intention Locks)称为锁的基本模式。后面三个 Record Locks、Gap Locks、Next-Key Locks,我们把它们叫做锁的算法,表示分别在什么情况下锁定什么范围。 官网:dev.mysql.com/doc/refman/…
3.2 锁的粒度
InnoDB支持行锁和表锁。
3.2.1 加锁效率
- 表锁,锁住一张表。直接锁表。
- 行锁,锁住表里一行数据。检索需要需要加锁的行数据。
- 结论:表锁的加锁效率更高。
3.2.2 冲突概率
- 表锁,锁住一张表,其他任何事务不能操作此表。
- 行锁,锁住表里一行数据,不影响其他事务操作表里其他没有被锁定的行。
- 结论:表锁冲突概率更大,并发性能更低。
3.3 锁的类型
3.3.1 共享锁(Shared Locks)
官网第一个行级别锁Shared Locks(共享锁),获取一行数据的读锁,用来读取数据,称之为读锁。获取读锁后不能用于操作数据,不然可能会出现死锁。多个事务可以共享一把读锁。手动加上读锁命令:
select ... lock in share mode;。事务结束,锁自动释放。验证读锁是否共享:
3.3.2 排它锁(Exclusive Locks)
第二个行级别的锁Exclusive Locks(排他锁),用来操作数据,称之为写锁。只要有一个事务获取了一行数据的排他锁,其他事务就不能再获取这一行数据的共享锁和排它锁。手动加排他锁命令for update,在任意sql尾部都可增加排它锁命令。事务结束,锁自动释放。验证排他锁是否共享:
3.3.3 意向锁(共享/排他)
意向锁,是由数据库自己维护的。当某个事务给一行数据加上共享锁或排它锁之前,数据库会自动在这张表上面加一个意向共享锁或意向排他锁。意向锁相当于一个标记,加表锁时,判断是否有意向锁,没有,则可以加表锁。(如果没有意向锁,需要判断是否有行锁,得逐行数据判断,数据量大时,效率低下)
3.4 行锁的原理
加锁一定有带精确能命中的条件,不然会造成锁表。
3.4.1 没有索引的表(锁表)
当表没有索引的时候,给行数据加锁,实际是锁表,如下,给id=1的数据加锁,导致其他事务对此表的其他数据加锁都会阻塞(因为查询没有使用索引,会进行全表扫描,把每一个隐藏聚集索引都锁住了)。
3.4.2 有主键索引的表(锁聚集索引行)
有主键索引的表,根据主键加锁,锁住的是索引行。
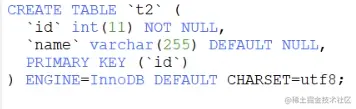
3.4.3 主键加唯一索引的表(锁聚集索引行)
有主键索引和二级索引,无论根据聚集索引或二级索引,都锁的所在行,因为二级索引,通过回表,最终也会关联到聚集索引。
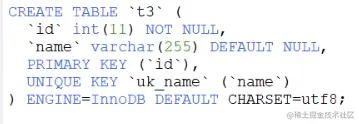
3.5 锁的算法
例子表结构和数据,id为主键,1、4、7、10四行记录。
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `t2`(`id`, `name`) VALUES (1, '1');
INSERT INTO `t2`(`id`, `name`) VALUES (4, '4');
INSERT INTO `t2`(`id`, `name`) VALUES (7, '7');
INSERT INTO `t2`(`id`, `name`) VALUES (10, '10');
3.5.1 区间划分
间隙:小括号,不包括临界值。N+1段。
临键:左开右闭。
3.5.2 Record Lock(记录锁)
对唯一索引(包括唯一索引和主键索引)使用等值查询,精准匹配到一条记录时,使用的是记录锁。比如where id = 1 4 7 10使用不同的key去加锁,不会冲突,只锁住这个record。
3.5.3 Gap Lok(间隙锁)
间隙锁的目的是为了阻塞插入语句。当查询的记录不存在,无论用等值还是范围查询,使用的都是间隙锁,如果没有命中索引,间隙锁锁住的范围是10(最大主键值),∞。间隙锁只在InnoDB默认隔离级别:可从复读(RR)中存在。
事务Transaction1获取id=6的锁,没有命中记录故给(4,7)加上间隙锁。在事务Transaction2中插入id=5或id=6记录阻塞,但是再次获取id=6的锁成功。结论:间隙锁时为了阻塞插入语句。
3.5.4 Next-key Lock(临键锁)
使用范围查询左开右闭,不仅仅命中Record记录,还包含Gap间隙,这种情况使用的就是临键锁,是MySQL默认的行锁算法,相当于记录锁+间隙锁。当唯一性索引等值匹配到一条记录时,转变成记录锁。如没有匹配到任何记录,转变成间隙锁。
当给id>5 and id < 9的记录加锁,锁住(4,10]左开右闭的区间,InnoDB在可重复读(Repeatable Read)解决了幻读问题,就是利用了间隙锁解决的。
4. InnoDB隔离级别基于锁的实现
4.6.1 Read Uncommited
RU 隔离级别:不加锁。
4.6.2 Serializable
Serializable 所有的 select 语句都会被隐式的转化为 select ... in share mode,会和 update、delete 互斥。 这两个很好理解,主要是 RR 和 RC 的区别?
4.6.3 Repeatable Read
RR 隔离级别下,普通的 select 使用快照读(snapshot read),底层使用 MVCC 来实现(第一次查询建立快照后面不会变)。加锁的 select(select ... in share mode / select ... for update)以及更新操作update, delete 等语句使用当前读(current read),底层使用记录锁、或者间隙锁、临键锁。
4.6.4 Read Commited
RC 隔离级别下,普通的 select 都是快照读,使用 MVCC 实现(查一次建立一次快照,可以看到其他事务已提交的修改)。加锁的 select 都使用记录锁,因为没有 Gap Lock。除了两种特殊情况——外键约束检查(foreign-key constraint checking)以及重复键检查(duplicate-key checking)时会使用间隙锁封锁区间。所以 RC 会出现幻读的问题。
4.6.5 事务隔离级别的选择
实际上,如果能够正确地使用锁(避免不使用索引去枷锁),只锁定需要的数据,用默认的 RR 级别就可以了。
RU 和 Serializable 肯定不能用。 RC 和 RR 主要有几个区别:
- RR 的间隙锁会导致锁定范围的扩大。
- 条件列未使用到索引,RR 锁表,RC 锁行。
- RC 的“半一致性”(semi-consistent)读可以增加 update 操作的并发性。
在 RC 中,一个 update 语句,如果读到一行已经加锁的记录,此时 InnoDB 返回记录最近提交的版本,由 MySQL 上层判断此版本是否满足 update 的 where 条件。若满足(需要更新),则 MySQL 会重新发起一次读操作,此时会读取行的最新版本(并加锁)。
5. 死锁
5.1 锁的释放与阻塞
锁的释放:commit、rollback、客户端连接断开。
如果一个事务一直未释放锁,其他事务会阻塞多长时间,MySQL有个参数控制默认默认50秒。
5.2 死锁的发生和检测
5.2.1 死锁的条件
- 互斥
- 不可剥夺
- 形成等待环路
5.2.2 死锁例子
排它锁有互斥的特性。一个事务或者说一个线程持有锁的时候,会阻止其他的线程获取锁,这个时候会造成阻塞等待,如果循环等待,会有可能造成死锁。
5.2.3 死锁的检测
在第一个事务中,检测到了死锁,马上退出了,第二个事务获得了锁,不需要等待50 秒。是因为死锁的发生需要满足一定的条件,所以在发生死锁时,InnoDB 一般都能通过算法(wait-for graph)自动检测到。
5.3 查看锁信息(日志)
5.3.1 行锁的信息(非实时)
Innodb_row_lock_current_waits:当前正在等待锁定的数量;
Innodb_row_lock_time :从系统启动到现在锁定的总时间长度,单位 ms;
Innodb_row_lock_time_avg :每次等待所花平均时间;
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间;
Innodb_row_lock_waits :从系统启动到现在总共等待的次数。
InnoDB 还提供了三张表来分析事务与锁的情况:
5.3.2 当前运行的所有事务和具体的语句
select * from information_schema.innodb_trx \G
5.3.3 当前出现的锁
select * from information_schema.INNODB_LOCKS;
5.3.4 锁等待的对应关系
select * from information_schema.innodb_lock_waits;
5.3.5 kill线程
如果事务长时间持有锁不释放,有kill事务对应的线程ID,也就是innodb_trx表中的trx_mysql_thread_id,kill <trx_mysql_thread_id>
5.4 死锁的避免
- 顺序访问
- 数据排序
- 申请足够级别的锁
- 避免没有where条件(不命中索引)的操作
- 大失误分解成小事务
- 使用等值查询而不是范围查询
