

「这是我参与11月更文挑战的第11天,活动详情查看:2021最后一次更文挑战」
最新弄到一本不错的书《中国妖怪故事(全集)》,忽然想到做一个收集整理中国妖怪的网站应该挺有意思的,故得此文。
写爬虫前的分析工作
对于编写爬虫,很多时候找到一个目标网站,然后对该站点进行分析,总会找到一种途径获取到你想要的数据;还有一种情况就是今天这种了,我们碰到一个想法,觉得这个想法还不错,然后尝试抓取一些基本数据,在结合一下 PHP,JAVA 这些语言编一个网站出来,没准能获得不错的流量。
今天要抓取的数据是 中国妖怪,除了自己整理以外,找到一个数据源网站就显得很重要了,所以我直接打开百度一顿搜索,果然,以橡皮擦(dream.blog.csdn.net/)的智力还是很难想到一…
虽然关于妖怪的网站不多,但还真有一个 知妖 。这个网站还真做了整理妖怪这么一个趣味性蛮强的工作,在这里为比我提前想到的 大佬,点个赞。

既然已经找到目标站点了,接下来的工作就比较简单了,分析走起。
先看数据量是否全,我经常在博客里面写的一句话是“只要人眼能看到的数据,爬虫都能抓取到”。这个网站由于是个人维护的,所以数据展示的比较全面,当然量也不是很大,合计 130 页左右,每次看到类似最后一页这样的描述,我就知道这网站爬取肯定有戏。

获取分页地址规律
随便点击 1~2 页,就可以获取到分页的基本规律了。
https://www.cbaigui.com/page/4
https://www.cbaigui.com/page/3
https://www.cbaigui.com/page/130
可以看到上述地址中,页码就是一个单纯的数字。
编写正则表达式
本次的目标是获取到妖怪数据,爬虫爬取过程中允许出现一定的冗余数据,所以直接分析页面元素即可,看一下哪些数据有价值。
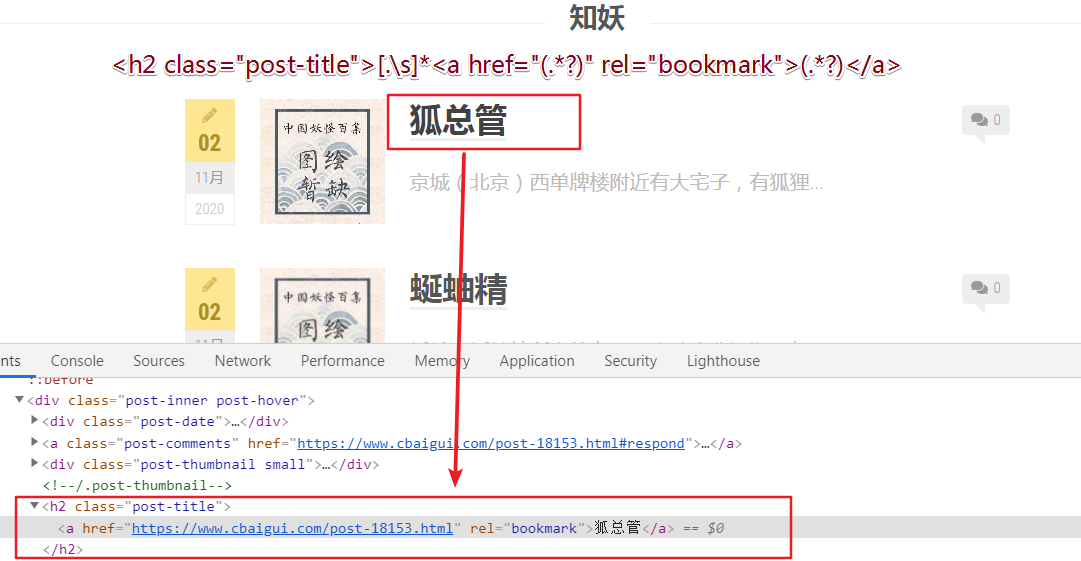
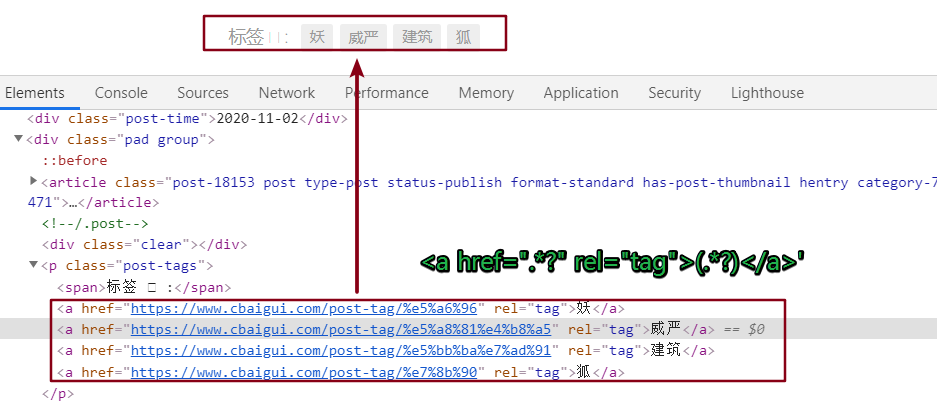
上图红框所示区域,为列表页面比较核心的数据,这里其实要抓取 2 个值,第一个是标题,第二个是标题点击之后的链接,抓取到链接,才可以获取到内页数据,即下面红框所示的 tag 标签区域。关于为何获取这个标签的原因,这里因人而异,我主要是为了获取标签之后进行相应的分类。
如果为了补全数据的完整性,你可以抓取头部的一些其他信息。里面包含一些朝代和妖怪的出处。
分析完毕,在橡皮擦看来,最难的工作就做完了,剩下的就是写代码抓取了。
爬虫编写工作
这里大家需要注意下,该网站应该属于个人开发者,所以我们在爬取的时候注意限制一下爬取速度,爬的太快对网站造成影响就不好了。
接下来编码正式开始。
首先你可以通过一些正则表达式工具,先把正则匹配写好,其实这部分写好了,代码也就编写一大部分了。
该页面中用到了 2 处正则,第一个用来匹配标题与链接,正则如下:
第一个正则表达式:
<h2 class="post-title">[.\s]*<a href="(.*?)" rel="bookmark">(.*?)</a>
第二个正则表达式:
<a href=".*?" rel="tag">(.*?)</a>'
对于正则表达式写的严谨性,在本系列专栏中不做要求,够用,好用即可。
下面展示一下部分代码,核心代码已经完成,剩下的就交给你来实现啦!~
import requests
import re
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}
def get_tags(url):
res = requests.get(url, headers=headers)
pattern = re.compile(
r'<a href=".*?" rel="tag">(.*?)</a>')
all = pattern.findall(res.text)
print(all)
def get_list(page):
url_format = "https://www.cbaigui.com/page/{page}"
url = url_format.format(page=page)
res = requests.get(url, headers=headers)
pattern = re.compile(
r'<h2 class="post-title">[.\s]*<a href="(.*?)" rel="bookmark">(.*?)</a>')
all = pattern.findall(res.text)
for item in all:
get_tags(item[0])
time.sleep(1)
if __name__ == "__main__":
total = int(input("请输入最大页码:"))
for i in range(1, total):
get_list(1)
# get_tags("https://www.cbaigui.com/post-18153.html")
运行之后,发现结果中有个色欲?什么鬼?

好奇心没忍住,找到链接点击了一下,好好的翻阅了一下相关信息,很有收获。

爬虫课后叨叨
完整的代码大家自行补齐即可,剩余部分都是数据存储相关内容了,你可以写到csv文件中即可。
爬虫爬取数据之后,会发现很多的趣味性,例如本案例就无形中给我补充了很多知识。
👯👯👯
