

TiDB
New-sql 型的数据库
架构
TiKV
- 使用 key-value 模型
- 有巨大的 Map,存储 Key-value pairs(键值对)
- 按照 key 的二进制顺序有序,也就可以 seek 到某个 key 位置
- 不断调用 next()获取比 key 大的 key-value
- 存储上借助 RocksDB 负责数据的落地
Facebook 开源的单机 KV 存储引擎
Raft
选用 Raft 一致性协议算法,和 Multi-Paxos 实现一样的分布式事务功能
- 功能
- Leader(主副本)选举
- 成员变更(eg:增删副本,转移 leader 等操作)
- 日志复制
在按照数据分散存储时,按照 key 分 Range,某一段1连续的 key 保存在存储节点上。有 PD 组件负责将 Region 散布到所有的节点上面去,此外 Region 会有多个副本 Replica,通过 Raft 保持一致,其中有个 replica 作为 leader,负责所有的的读写。
原理
MVCC 多版本控制协议
TiKV 通过在 key 后面加版本号实现
用户通过 RocksDB 的 SeekPrefix(key_version)API,找到第一个大于等于 key_version 的位置
事务
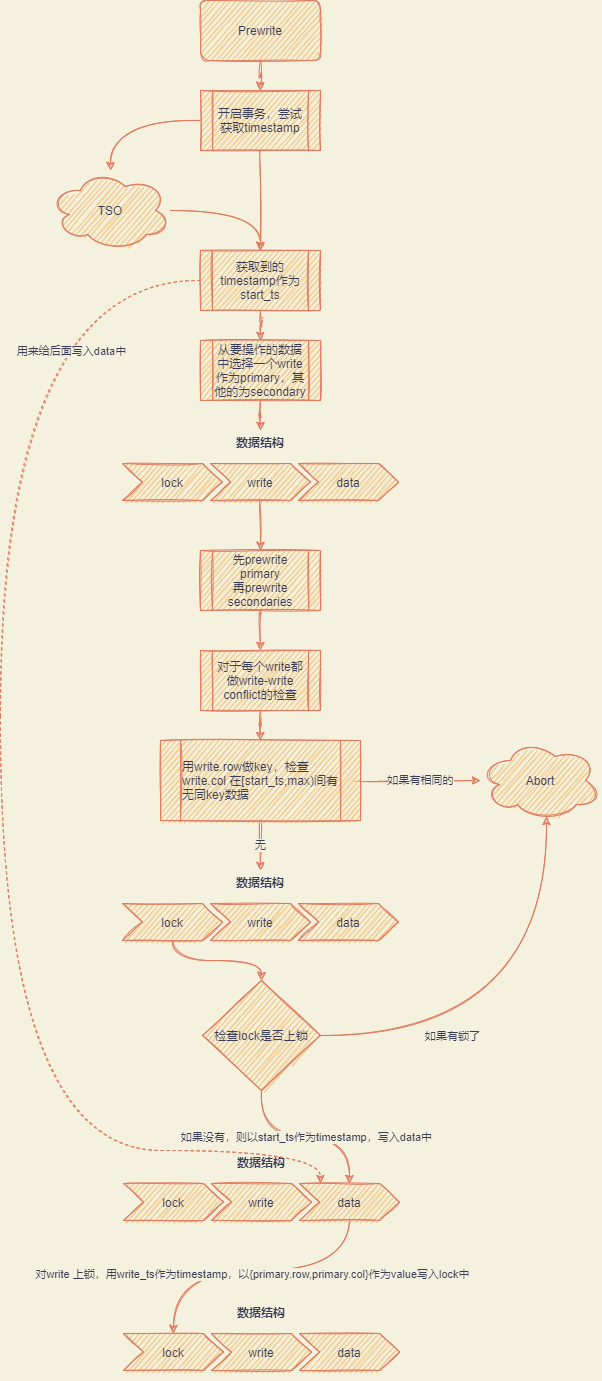
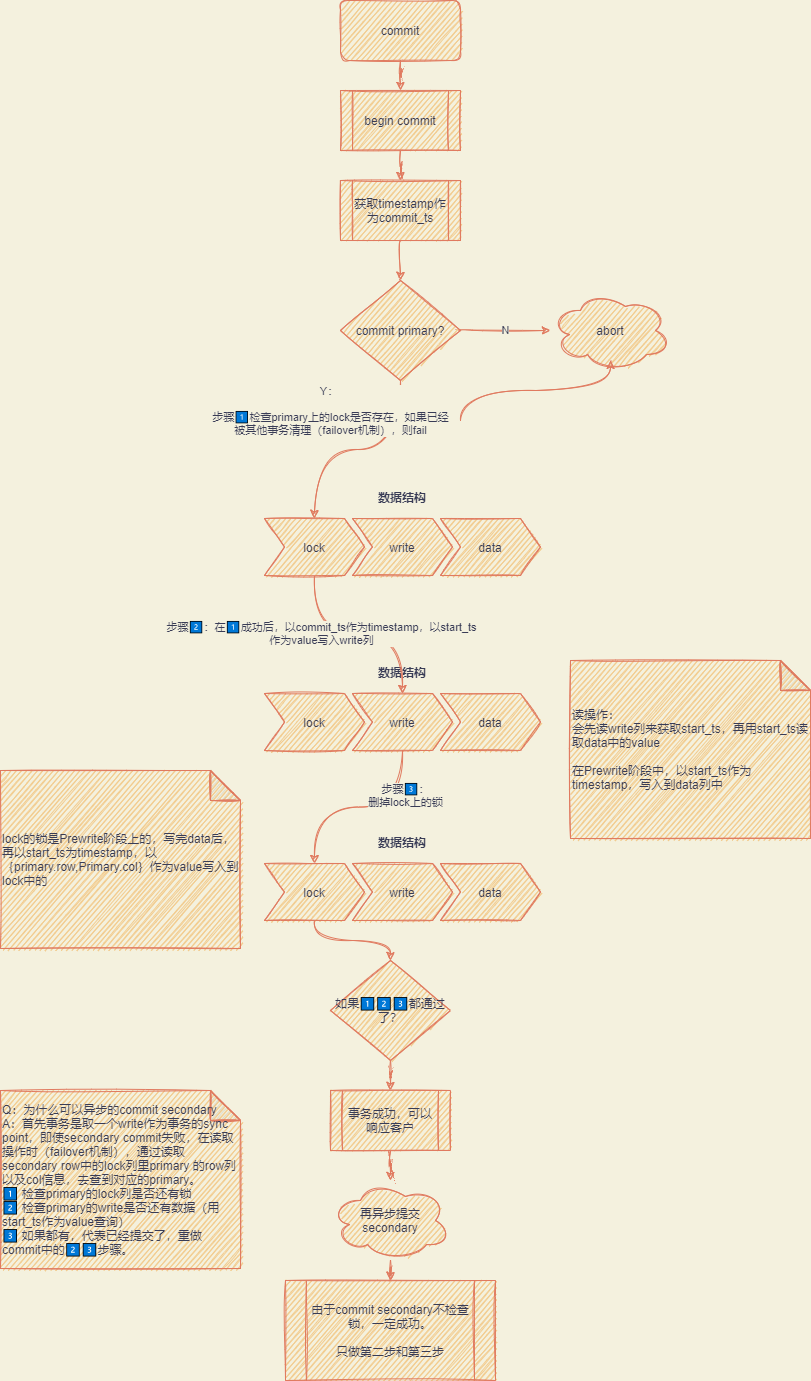
采用 Google 在 BigTable 中使用的事务模型 Percolator 协议实现。
把一条逻辑 sql 拆为多个 KV 的 set 语句进行执行
tx= tiKV.Begin();
tx.set(Key1,Value1);
tx.set(Key2,Value2);
tx.set(Key3,Value3);
tx.commit();
Percolator
| 优点 | 缺点 |
|---|---|
| 为 BigTable 的单行事务提供多行事务功能 | 需持久化 lock 列+列数据拆为 write 和 data (导致读写吞吐受到影响) |
| 并发控制+failover 简洁优雅 | 提交操作=>到具体的返回客户成功需要三次 IO 操作(IO+RPC)1️⃣prewrite primary 2️⃣prewrite secondaries 3️⃣commit primary |
| Snapshot Isolation+failover 的安全保障 |
Prewrite阶段
commit阶段
Failover 机制
采用 lazzy 形式,一个事务的 failover 由另外一个事务读触发,如果一个事务读 key 时,发现上锁了,按 Snapshot-Read 要求等锁删除才能读取。 等一段时间后,会认为事务可能因为 client clash or 网络分区 hang 住,尝试用 rollback or 提交锁事务来清理锁。
Footnotes
-
Region 默认 96MB,按照[startKey,endKey)分布 ↩
