在机器学习领域,深度学习(Deep Learning)基本都被神经网络统治着,而浅层学习(Shallow Learning)目前任然属于树模型的领地。一方面,尽管深度学习在大规模学习上表现强大,但它在小规模学习上的表现差强人意;另一方面,集成树算法(RF、GBDT、XGBoost等)因其模型解释度高、调参难度小、运行速度快、几乎不需要特征工程等优点,在中小规模数据集上完全碾压深度学习,而且对于“异质类数据”(比如风控场景中的年龄、收入、城市这类数据),即便在大规模数据集上,集成树模型也比深度学习表现更好。在实际应用中,Facebook、阿里巴巴等大企业都在使用结合LR的GBDT作为点击率预估、广告推荐等重要业务的技术支撑,而XGBoost更是在近些年的Kaggle算法大赛中屡屡绽放异彩。
本文介绍集成学习中的Boosting方法,以及它的家族成员AdaBoost、GBDT,如果你对基础的决策树算法还不太了解,推荐参阅我另一篇博文:
决策树模型:ID3、C4.5、CART算法介绍
集成学习
-
传统机器学习的目标都是训练得到一个预测准确率尽可能高的“强学习器”(决策树、神经网络等),而实际情况中要找到一个最优的“强学习器”很难,于是“集成学习”被提出。“集成学习”认为,对多个预测准确率较低的“弱学习器”(只要求预测准确率略高于随机猜测),如果以某种恰当的方式将这多个“弱学习器”组合,那么就能提升为“强学习器”,获得更高的预测准确率。基于这种思想,1990年, Schapire最先构造出一种多项式级的算法,对该问题做了肯定的证明,这就是最初的 Boosting算法,后来发展到现在,“集成学习”已经成为一种非常成熟且应用广泛的机器学习方法,它的家族成员包括RF、GBDT、XGboost等众多优秀算法。
-
如今集成学习主要包括三种类型:Bagging(袋装法)、Boosting(提升法)、Stacking(堆叠法),本文讲解Boosting方法及相关算法(AdaBoost、GBDT)。
Boosting方法
-
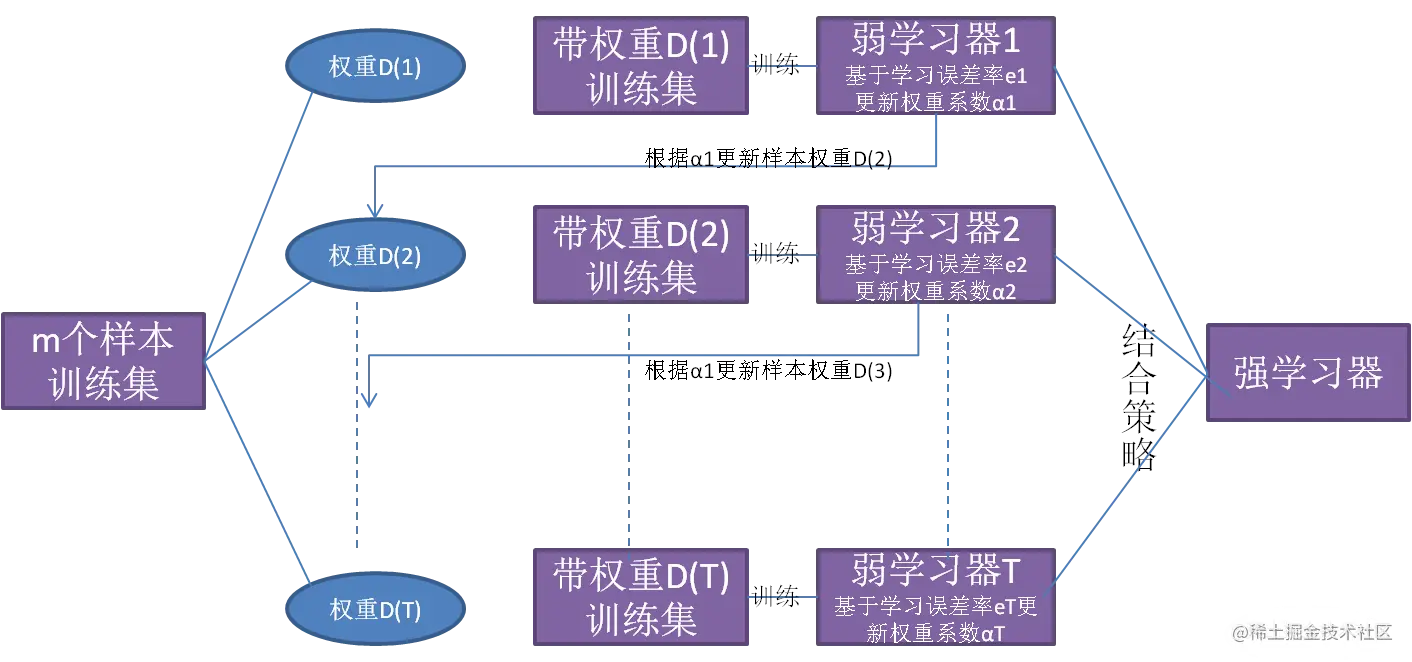
不同于Bagging的并行,Boosting是阶梯状的串行,它从第一个基学习器开始,后面每个基学习器都会根据上个基学习器对各个样本的预测正误而调整样本的权值分布,同时根据基学习器自身的预测准确率而调整自身的权重值,得到一系列权重值不同的基学习器,然后将这多个学习器进行加权组合,得到最终的学习器。具体步骤如下:
-
1、它首先令每个样本拥有相同的权重值(1/n,用来计算误差率或准确率,一些分类算法中这个权值不会改变),构建一个弱分类器。
-
2、改变样本的权值分布:增大该分类器分错误的样本的权值,减小该分类器分正确的样本的权值;改变该分类器的权重值:计算该分类器的正确率,正确率越高,越加大它的权重值;
-
3、根据改变权值分布后的样本数据构建一个新的弱分类器。
-
4、重复2、3步骤,直到到达预定的学习器数量或预定的预测精度。
-
直观理解:
- Boosting的每一步总是更关注于分类错误的样本,使它们再下一步更容易被分正确;
- Boosting中正确率越高的分类器的权值越大,使得最后线性组合以后更优的分类器拥有更大的发言权,而不像Bagging方法中每个分类器是相同的权重。
AdaBoost(自适应增强)
- AdaBoost(Adaptive Boosting)是Boosting方法中的入门级算法。原始的 Adaboost 算法用于解决二分类问题,因此对于一个训练集
T={(x1,y1),(x2,y2),…,(xn,yn)}
- 其中 xi∈X⊆Rn,yi∈Y={−1,+1}, 首先初始化训练集的权重
D1w1i=(w11,w12,…,w1n)=n1,i=1,2,…,n
- 根据每一轮训练集的权重 Dm, 对训练集数据进行抽样得到 Tm, 再根据 Tm 训练得到每 一轮的基学习器 hm 。通过计算可以得出基学习器 hm 的误差为 ϵm, 根据基学习器的误 差计算得出该基学习器在最终学习器中的权重系数
αm=21lnϵm1−ϵm
Dm+1wm+1,i=(wm+1,1,wm+1,2,…,wm+1,n)=Zmwm,iexp(−αmyihm(xi))
Zm=i=1∑nwm,iexp(−αmyihm(xi))
- 从而保证 Dm+1 为一个概率分布。最终根据构建的 M 个基学习器得到最终的学习器:
hf(x)=sign(m=1∑Mαmhm(x))
-
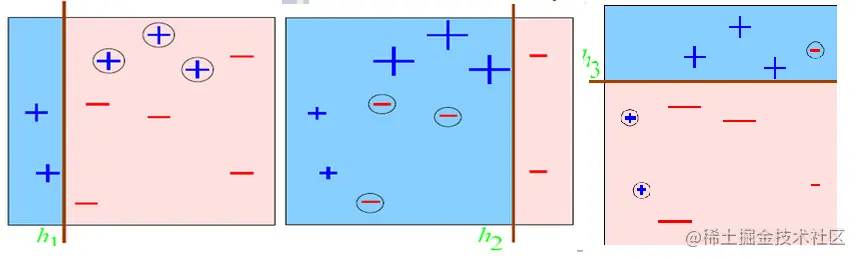
下面以图例来直观理解AdaBoost:
-
1、左图,一开始,所有的数据点有相同的权重(正号、负号的大小都一样),第一个基学习器将数据样本分成了两部分。可以看出,三个正号标记的数据点分类错误,因此我们将这三个点赋予更大的权重。同时,根据分类正确率的高低来给这个学习器赋予一个权重值。
-
2、中间图,第二个基学习器,可以看到上个学习器未正确分类的3个(+)号的点的权重已经增大,此时第二个基学习器根据改变权值分布后的数据进行训练,得到第二个分类模型,由于它的分类将三个(-)号标记的点识别错误,因此在下一次分类中,这三个(-)号标记的点被赋予更大的权重。同时,根据分类正确率的高低来给这个学习器赋予一个权重值。
-
3、右图,第三个基学习器,重复相同步骤。
-
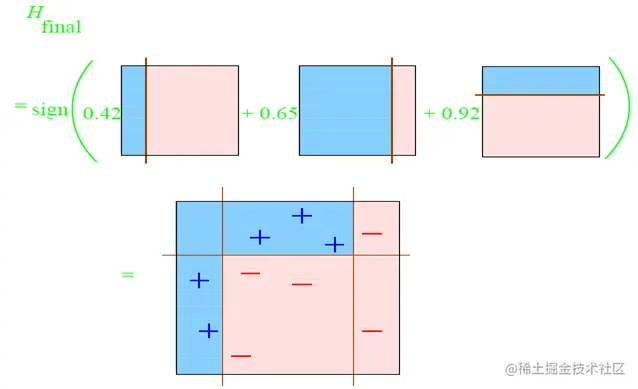
4、最终,将前面三个基学习器进行加权线性组合,作为最终的强学习器,它将会比前面任何一个弱分类器表现的都要好。
GBDT(梯度提升树)
前向分步算法与梯度提升
-
GBDT(Gradient Boosting Decision Tree)以及其他类型的提升树模型都是基于“前向分步算法”。 而前向分步算法可以这样来理解:假设我们要使用决策树来预测一个人的年龄, 刚开始的时候模型初始化会直接给出一个预测值 f0(x), 注意这个预测值不需要训练决策树来得到, 而且不一定精确(比如刚开始模型初始预测为0岁,或者根据人群年龄分布给出一个相对合理的值)。接着在模型上一步所给出的预测基础上来训练第一棵决策树, 此时模型的输出便是模型初始化的预测值加上第一棵决策树的输出值, 然后我们继续添加第二棵决策树, 使得第二棵决策树能够在前面所构造的模型基础之上, 让总体损失最小, 不断的进行这一过程直到构建的决策树棵数满足要求或者总体损失小于一个阈值。
-
当前向分步算法进行到第 m 步时, 预测函数可以表示为:
fm(x)=fm−1(x)+βmT(x;Θm)
-
其中 fm−1(x) 是第 m−1 步的预测函数, 而 T(x;Θm) 是我们当前需要构造的第 m 棵决策树, βm 表示学习率(也称步长)。由于前面的 m−1 棵决策树已经训练好了, 参数都已经固定了, 对于固定的 βm , 那么在第 m 步, 我们仅需要训练第 m 棵树的参数 Θm 来最小化当前总体损失:
Θ^m=Θmargmini=1∑NL(yi,fm−1(xi)+βmT(xi;Θm))
- 其中 N 代表样本的总个数, L 代表损失函数。在前向分步算法搞清楚之后, 我们再来回顾一下机器学习中是如何最小化损失函数的。
- 假设现有一损失函数 J(θ), 当我们需要对这个参数为 θ 的损失函数求最小值时, 只要按照损失函数的负梯度方向调整参数 θ 即可, 因为梯度方向是使得函数增长最快的方向, 沿着梯度的反方向也就是负梯度方向会使得函数减小最快, 当学习率为 ρ 时, θ 的更新方法如下:
θi:=θi−ρ∂θi∂J
- 那么同理, 前向分步算法中要使得损失总体损失 J=∑iL(yi,fm−1(xi)) 更小, 需要对 fm−1(x) 求导, 而 fm−1(x) 是针对 N 个样本的, 所以对每个样本预测值求偏导数:
fm(xi):=−ρ∂fm−1(xi)∂J
- 这里的 ρ 和刚才所提到的 βm 的作用是相同的,次数令 ρ=1 。对于第 m 棵决策树而言, 其拟合的不再是原有数据 (xi,yi) 的结果值 yi, 而是负梯度, 因为这样就能使得总体损失函数下降最快。于是对于第m棵决策树,它要拟合的样本数据集更新为:
{(x1,−∂fm−1(x1)∂J),(x2,−∂fm−1(x2)∂J),⋯,(xn,−∂fm−1(xn)∂J)},m=1,2,⋯,M
- 这样迭代到一定步骤,损失函数达到足够小,最后GBDT输出的预测值就是前面所有树的和,它会非常接近y值。
GBDT回归算法
- 对于回归问题来说, 我们以平方误差损失函数为例, 来介绍GBDT的处理方法。平方误差损失函数:
L(y,f(x))=21⋅(y−f(x))2
- 对于第m−1棵决策树,每个样本i的损失函数为: J=L(yi,fm−1(xi)),其关于预测值fm−1(xi)的梯度(偏导数)为:
∂fm−1(xi)∂J=∂fm−1(xi)∂∑iL(yi,fm−1(xi))=∂fm−1(xi)∂L(yi,fm−1(xi))=fm−1(xi)−yi
−∂fm−1(xi)∂J=yi−fm−1(xi)
yi−fm−1(xi) 便是当前一棵决策树需要拟合的残差(Residual),因此对于回归问题的提升树模型而言,每棵决策树只需要去拟合前面遗留的残差即可。
注意:fm−1(x)并不是第m−1棵决策树,而是在第m−1棵决策树这一步的预测函数,同理fm−1(xi)表示预测函数在样本xi上的预测值。第m−1棵决策树仅仅拟合负梯度,而预测函数fm−1(x)是拟合的负梯度加上前面树的预测值。
-
回归问题的GBDT方法流程:
-
输入:训练数据集 T={(x1,y1),(x2,y2),⋯,(xN,yN)},xi∈X⊆Rn,yi∈Y⊆R, 以及学习率 βm(也称步长)
-
输出:提升树 fM(x)
-
初始化 f0(x)=N1∑iNyi
-
对决策树 m=1,2,⋯,M
(a) 计算每个样本i的残差:
rmi=yi−fm−1(xi),i=1,2,⋯,N
(b) 拟合残差 r_{m i} 学习一个回归树, 得到第 m 棵树的叶结点区域 Rmj,j=1,2,⋯,J 。注意:决策树(CART回归树)内部也是以平方误差作为损失函数进行分裂的。
(c) 对叶结点 j=1,2,⋯,J, 计算最优输出值:
cmj=argcminxi∈Rmj∑L(yi,fm−1(xi)+c)
这一步是为了计算怎么对叶结点区域内的样本进行赋值, 使得模型损失最小, 因此这一步是需要根据当前决策树的损失函数来计算的, 而\text {CART}回归树的损失函数是平方误差损失,所以这一步计算结果为:
cmj=Nmj1xi∈Rmj∑rmi
即每个叶结点区域残差的均值。
(d) 更新决策树 fm(x)=fm−1(x)+βm∑j=1JcmjI(x∈Rmj) 。
-
最终得到针对回归问题的梯度提升树:
fM(x)=m=1∑Mβmj=1∑JcmjI(x∈Rmj)
注意:\beta_{m} 的范围是(0,1),它的作用和梯度下降算法中的学习率(也称步长)是一样的, 能够使得损失函数收敛到更小的值, 因此可以调小 \beta_{m}, 而一个较小的学习率会使得模型趋向于训练更多的决策树, 使得模型更加稳定, 不至于过拟合,因此在GBDT中\beta_{m}也可以作为正则化参数。
GBDT二分类算法
L(y,f(x))=−ylogy^−(1−y)log(1−y^)y^=1+e−f(x)1
-
其中 y^ 是一个Sigmoid函数,我们用它来表示决策树将样本类别预测为1的概率 P(y=1∣x) ;y为样本类别的实际值(0和1)。
-
那么对于第m−1棵决策树,损失函数 J=∑iL(yi,fm−1(xi)),其关于样本预测值的梯度计算为 :
∂fm−1(xi)∂J=∂fm−1(xi)∂L(yi,fm−1(xi))=∂fm−1(xi)∂[−yilog1+e−fm−1(xi)1−(1−yi)log(1−1+e−fm−1(xi))1)=∂fm−1(xi)∂[yilog(1+e−fm−1(xi))+(1−yi)[fm−1(xi)+log(1+e−fm−1(xi))]]=∂fm−1(xi)∂[(1−yi)fm−1(xi)+log(1+e−fm−1(xi))]=1+e−fm−1(xi)1−yi=yi^−yi
-
计算得到的结果就是该决策树的类别预测概率值与类别实际值之间的差值, 那么负梯度为:
−∂fm−1(xi)∂J=yi−y^i
GBDT多分类算法
-
GBDT在二分类问题上采用了对原始回归树模型嵌套一个“逻辑回归函数”的方法,而GBDT在多分类问题上采用的是“多项逻辑回归”(Softmax Regression)的方法,下面先简单介绍一下多项逻辑回归。
-
“多项逻辑回归”(Softmax Regression)可以看作是逻辑回归(Logistic Regression)的一般形式,反之,也可以将逻辑回归看作是多项逻辑回归的一个特例。在Logistic Regression中需要求解的是两个概率: P(y=1∣x;θ) 和 P(y=0∣x;θ);而在Softmax Regression中将不再是两个概率,而是 k 个概率, k 表示类别数。Softmax Regression的预测函数:
hθ(x)=P(Y=yi∣x)=⎣⎡P(Y=1∣x;θ)P(Y=2∣x;θ)⋅⋅⋅P(Y=k∣x;θ)⎦⎤=∑j=1keθjTx1⎣⎡eθ1Txeθ2Tx⋅⋅⋅eθkTx⎦⎤
-
其中, θ1T,θ2T,…,θkT 为k个模型分别的参数(向量),最后乘以 ∑j=1keθjTxi1 是为了让每个类别的概率处于 [0,1]区间并且概率之和为1。Softmax Regression将输入数据 xi 归属于类别 j 的概率为:
p(yi=j∣xi;θ)=∑l=1keθlTxieθjTxi
-
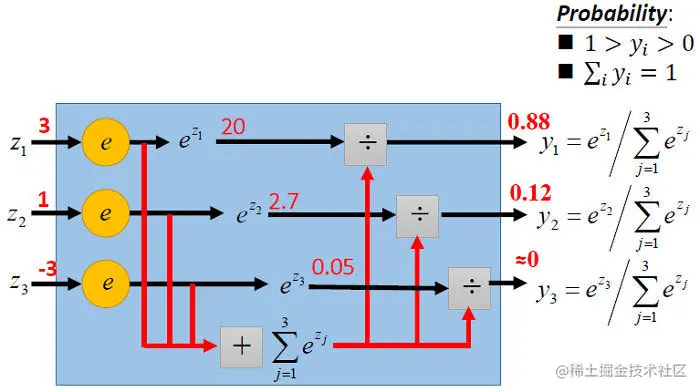
上面公式可以用下图来形象化地解析:
-
一般来说, Softmax Regression具有参数冗余的特点, 即将θ1T,θ2T,…,θkT 同时加减一个向量后预测结果不变, 因为 P(Y=1∣x)+P(Y=2∣x)+…+P(Y=k∣x)=1 ,所以 P(Y=1∣x)=1−P(Y=2∣x)−…−P(Y=k∣x)。假设从参数向量 θjT 中减去向量 ψ, 这时每一个θjT 都变成了 θjT−ψ(j=1,2,…,k) 。此时预测函数变成了:
P(Y=yj∣x;θ)=∑i=1keiTixeθjTx=∑i=1ke(θiT−ψ)xe(θjT−ψ)x=∑i=1keθiTx×e−ψxeθjTx×e−ψx=∑i=1keθiTxeθjTx
-
从上式可以看出, 从 θjT 中减去 ψ 完全不影响假设函数的预测结果。特别地,当类别数k为2时:
hθ(x)=eθ1Tx+eθ2Tx1[eθ1Txeθ2Tx]
-
利用参数冗余的特点, 我们将上式所有的参数减去 θ1,上式变为:
hθ(x)=e0⋅x+e(θ2T−θ1T)x1[e0⋅xe(θ2T−θ1T)x]=[1+eTTx11−1+eθTx1]
GBDT与BDT
-
BDT(Boosting Decision Tree),提升树,尽管梯度提升树是提升树的改进版,但我们也可以把提升树看作是令梯度提升树中的损失函数取平方误差损失时的一个特例,因此提升树每次训练决策树只需要拟合上一步的残差即可。
-
但是以残差作为损失函数其实有很大的劣势,一个比较明显的缺点就是对异常值过于敏感。我们来看一个例子:

-
很明显后续的模型会对第4个值关注过多,这不是一种好的现象,所以一般回归类的损失函数会用绝对损失或者huber损失函数来代替平方损失函数:

-
可以看出huber损失对于异常值的鲁棒性强很多。Huber损失是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心附近的点采用均方差。
有问题欢迎留言交流。
最后,如果你对Python、数据挖掘、机器学习等内容感兴趣,欢迎关注我的博客。


