「这是我参与11月更文挑战的第9天,活动详情查看:2021最后一次更文挑战」
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,经济预测等领域。 我们知道对于回归wTxi 输出取值范围是实数范围,对于分类问题我们希望输出预测某一个类别的概率。
我们在之前介绍最大似然估计和最大后验估计,他们分别基于频率学派的 MLE 和贝叶斯学派的 MAP,而且我们知道 MAP 是在 MLE 基础上添加先验。首先我们考虑如何把一个实数范围取值映射到一个概率空间也就是取值 0 到 1 范围,这里需要聊一聊 sigmoid 函数
σ(z)=1+e−z1
我们看看函数的图形
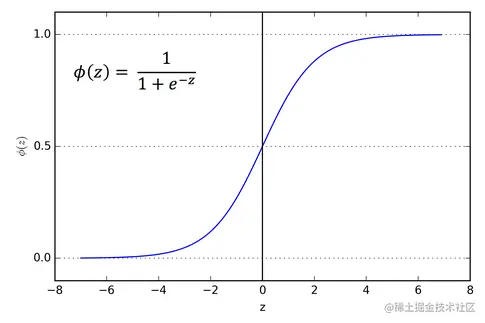
这个函数输入是实数范围,而输出为 0 到 1 之间,通过这个函数就能把转换一个概率。这里我们讨论是一个概率,假设是二分类问题,通过条件概率考虑问题,例如 y 取值为 1 和 0 分别表示两个类别,这是伯努利分布,也就是 0 1 问题。
P1(y=1∣x)=σ(wTx)=1+e−wTx1P0(y=0∣x)=1−p1=1−σ(wTx)=1+e−wTxe−wTx
这是二项分布
p(y∣x)=p1yp01−y
可以将数据理解为条件概率 P(Y∣X) X 样本的集合,Y 为标签,我们因为在给定 X 数据出现 Y 的条件概率。
w^=wargmaxlogP(Y∣X)wargmaxlogi=1∏NP(yi∣xi)
这联合概率,因为每一个概率事件都是相互独立所以可以写成g∏i=1NP(yi∣xi)
wargmax=i=1∑N(yilogp1+(1−yi)logp0)
f(xi;w)=1+e−wTx1
wargmax=i=1∑N(yilogf(xi;w)+(1−yi)log(1−f(xi;w)))
这样来看将其转换最求问题,添加负号就是交叉熵(cross entropy),这样我们可以 logistic regression 来做分类问题


