参与11月更文挑战的第8天,活动详情查看:2021最后一次更文挑战
目前写几个我接触到的,以后遇到再补充。长期更文。
L2 loss
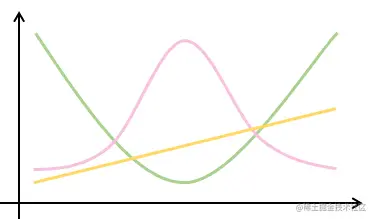
均方损失,就是l(y,y′)=21(y−y′)2
前边的21是让你在求导的时候抵消2。
-
绿色就是l(y,y′)=21(y−y′)2
-
粉色是四元函数,即e−(l(y,y′))
服从正态分布(高斯分布)
-
黄色是损失函数的梯度,是一次函数,穿过原点。
梯度下降时候沿着负梯度方向更新参数。
所以导数是决定梯度下降如何更新参数。
当预测值和真实值比较远的时候,梯度比较大,参数更新幅度也大,当随着梯度减小,参数更新的幅度也越来越小。
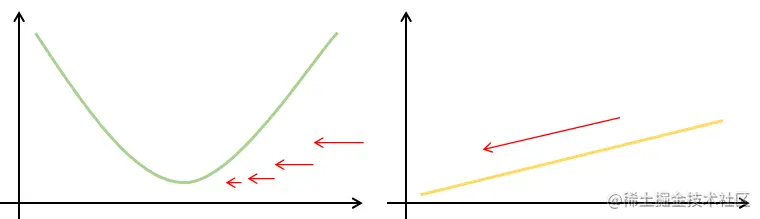 这并不是什么好事,当离远点比较远的时候也许我们并不想大幅度更新参数。
这并不是什么好事,当离远点比较远的时候也许我们并不想大幅度更新参数。
L1 loss
绝对值损失函数l(y,y′)=∣y−y′∣
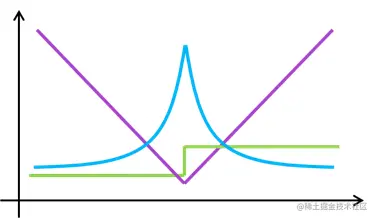
- 紫色就是l(y,y′)=∣y−y′∣
- 蓝色是其四元函数
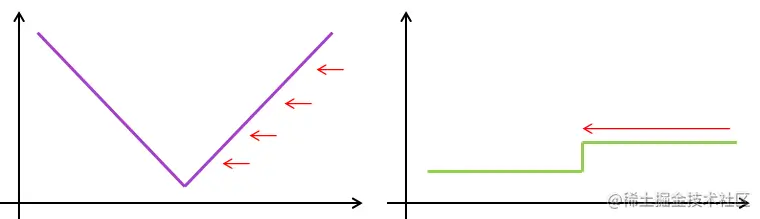
- 绿色是梯度,区间是±1。权重更新是稳定的,但是零点处不可导,在优化末期可能不稳定。
Huber's Robust loss
哈勃损失
l(y,y′)={∣y−y′∣−2121(y−y′)2 if ∣y−y′∣>1 otherwise
结合了前两者的优势。
预测值和真实值差的比较大的时候使用绝对值误差,减去21为了能让图像连起来。当预测值和真实值比较近的时候使用平方误差。
这样就可以在距离比较远的时候均匀地更新权重,在优化末期的时候梯度越来越小,优化更加平滑。


