Mysql逻辑架构
总体概览
和其它数据库相比,MySQL有点与众不同,它的架构可以
在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的
架构上,
插件式的存储引擎架构将查询处理和其它的系统任务以及数据
的存储提取相分离。这种架构可以根据业务的需求和实际需要选
择合适的存储引擎。
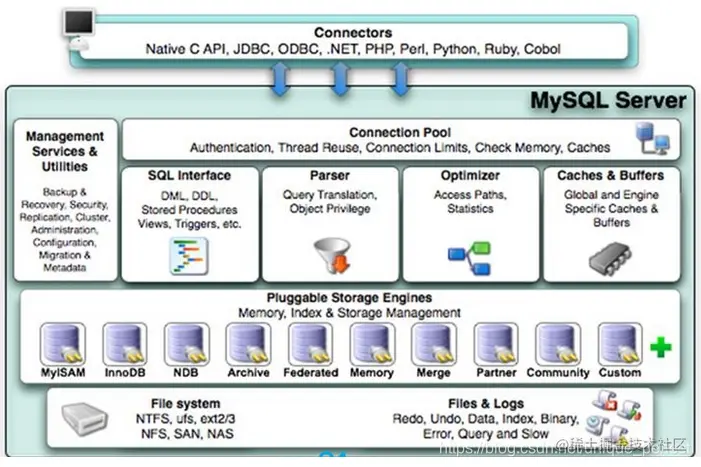
1.连接层
最上层是一些客户端和连接服务,包含本地sock通信和大多数基于
客户端/服务端工具实现的类似于tcp/ip的通信。主要完成一些类似
于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,
为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL
的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操
作权限。
2.服务层
2.1 Management Serveices & Utilities: 系统管理和控制工具
2.2 SQL Interface: SQL接口
接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就
是调用SQL Interface
2.3 Parser: 解析器
SQL命令传递到解析器的时候会被解析器验证和解析。
2.4 Optimizer: 查询优化器。
SQL语句在查询之前会使用查询优化器对查询进行优化。
用一个例子就可以理解: select uid,name from user where gender= 1;
优化器来决定先投影还是先过滤。
2.5 Cache和Buffer: 查询缓存。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,
key缓存,权限缓存等
缓存是负责读,缓冲负责写。
3.引擎层
存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服
务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,
这样我们可以根据自己的实际需要进行选取。
后面介绍MyISAM和InnoDB
4.存储层
数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,
并完成与存储引擎的交互。
Mysql存储引擎
查看命令
1 如何用命令查看
#看你的mysql现在已提供什么存储引擎:
mysql> show engines;
#看你的mysql当前默认的存储引擎:
mysql> show variables like '%storage_engine%';
各个引擎简介
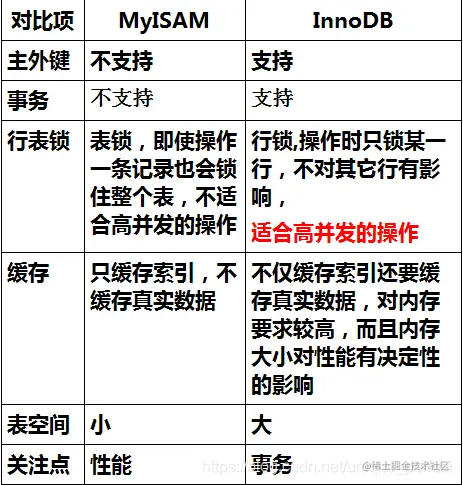
1、InnoDB存储引擎
InnoDB是MySQL的默认事务型引擎,它被设计用来处理大量的
短期(short-lived)事务。除非有非常特别的原因需要使用其他的存储
引擎,否则应该优先考虑InnoDB引擎。行级锁,适合高并发情况
2、MyISAM存储引擎
MyISAM提供了大量的特性,包括全文索引、压缩、空间函数(GIS)等,
但MyISAM不支持事务和行级锁(myisam改表时会将整个表全锁住),
有一个毫无疑问的缺陷就是崩溃后无法安全恢复。
3、Archive引擎
Archive存储引擎只支持INSERT和SELECT操作,在MySQL5.1之前不
支持索引。
Archive表适合日志和数据采集类应用。适合低访问量大数据等情况。
根据英文的测试结论来看,Archive表比MyISAM表要小大约75%,比支
持事务处理的InnoDB表小大约83%。
4、Blackhole引擎
Blackhole引擎没有实现任何存储机制,它会丢弃所有插入的数据,不
做任何保存。但服务器会记录Blackhole表的日志,所以可以用于复制
数据到备库,或者简单地记录到日志。但这种应用方式会碰到很多
问题,因此并不推荐。
5、CSV引擎
CSV引擎可以将普通的CSV文件作为MySQL的表来处理,但不支持索引。
CSV引擎可以作为一种数据交换的机制,非常有用。
CSV存储的数据直接可以在操作系统里,用文本编辑器,或者excel读取。
6、Memory引擎
如果需要快速地访问数据,并且这些数据不会被修改,重启
以后丢失也没有关系,那么使用Memory表是非常有用。Memory
表至少比MyISAM表要快一个数量级。(使用专业的内存数据库更
快,如redis)
7、Federated引擎
Federated引擎是访问其他MySQL服务器的一个代理,尽管该引
擎看起来提供了一种很好的跨服务器的灵活性,但也经常带来问
题,因此默认是禁用的。
MyISAM和InnoDB

innodb 索引 使用 B+TREE myisam 索引使用 b-tree
innodb 主键为聚簇索引,基于聚簇索引的增删改查效率非常高。
索引优化分析
性能下降SQL慢,执行时间长,等待时间长
查询数据过多
能不能拆,条件过滤尽量少
关联了太多的表,太多 Join
join 原理。用 A 表的每一条数据 扫描 B表的所有数据。所以尽量先过滤。
没有利用到索引
单值
复合
条件多时,可以建共同索引(混合索引)。混合索引一般会偶先使用。
有些情况下,就算有索引具体执行时也不会被使 用。
服务器调优及各个参数设置(缓冲、线程数等)
手写跟机读
手写

机读
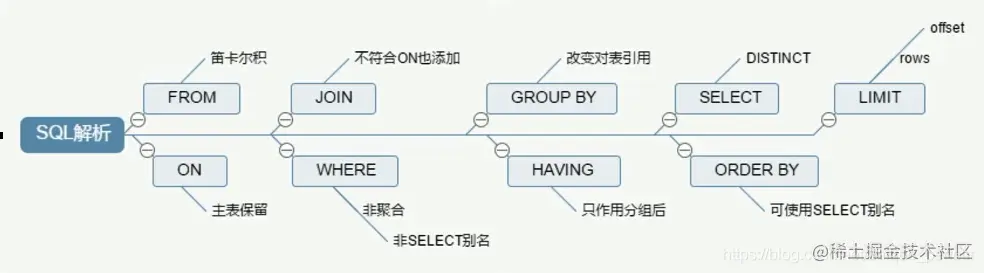
随着Mysql版本的更新换代,其优化器也在不断的升级,优化
器会分析不同执行顺序产生的性能消耗不同而动态调整执行顺序。
下面是经常出现的查询顺序:

七种join
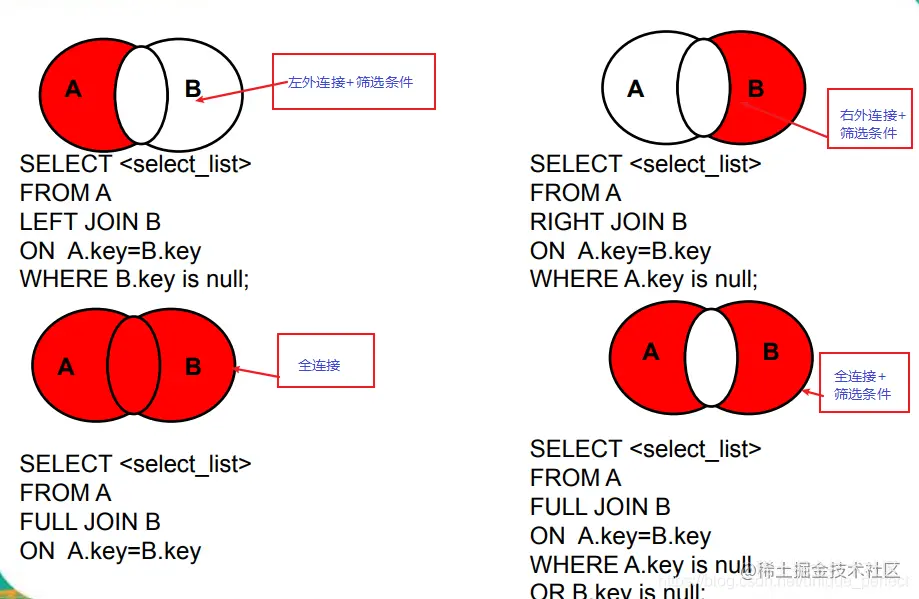
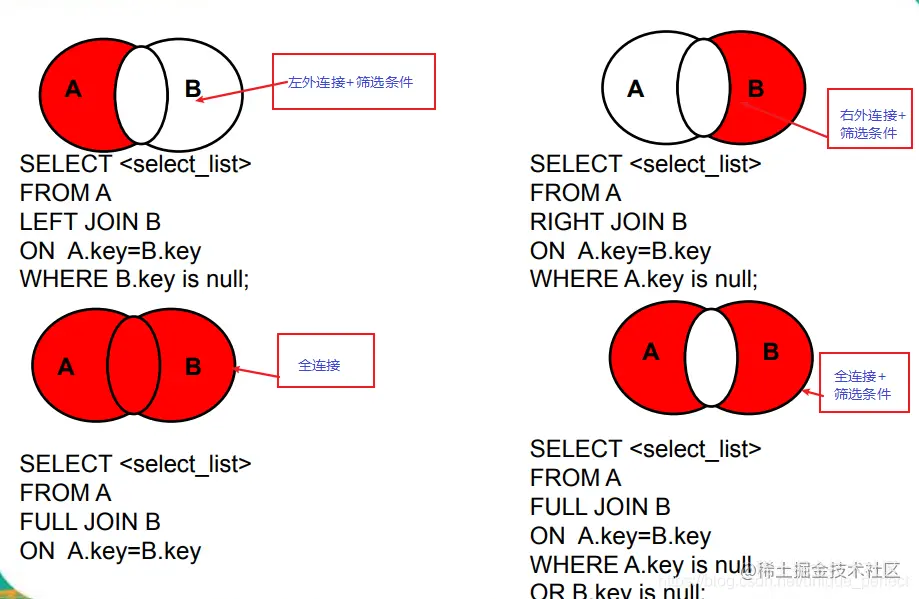
1 A、B两表共有
select * from t_emp a inner join t_dept b on a.deptId = b.id;
2 A、B两表共有+A的独有
select * from t_emp a left join t_dept b on a.deptId = b.id;
3 A、B两表共有+B的独有
select * from t_emp a right join t_dept b on a.deptId = b.id;
4 A的独有
select * from t_emp a left join t_dept b on a.deptId = b.id where b.id is null;
5 B的独有
select * from t_emp a right join t_dept b on a.deptId = b.id where a.deptId is null;
6 AB全有
#MySQL Full Join的实现 因为MySQL不支持FULL JOIN,下面是替代方法
#left join + union(可去除重复数据)+ right join
SELECT * FROM t_emp A LEFT JOIN t_dept B ON A.deptId = B.id
UNION
SELECT * FROM t_emp A RIGHT JOIN t_dept B ON A.deptId = B.id
这里因为要联合的缘故,不能考虑到小表驱动大表的情况。只能用right join。要保证查询出来的数字要一致。
7 A的独有+B的独有
* FROM t_emp A LEFT JOIN t_dept B ON A.deptId = B.id WHERE B.`id` IS NULL
UNION
SELECT * FROM t_emp A RIGHT JOIN t_dept B ON A.deptId = B.id WHERE A.`deptId` IS NULL;


