

MapReduce
wordcount原理
wordcount类
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;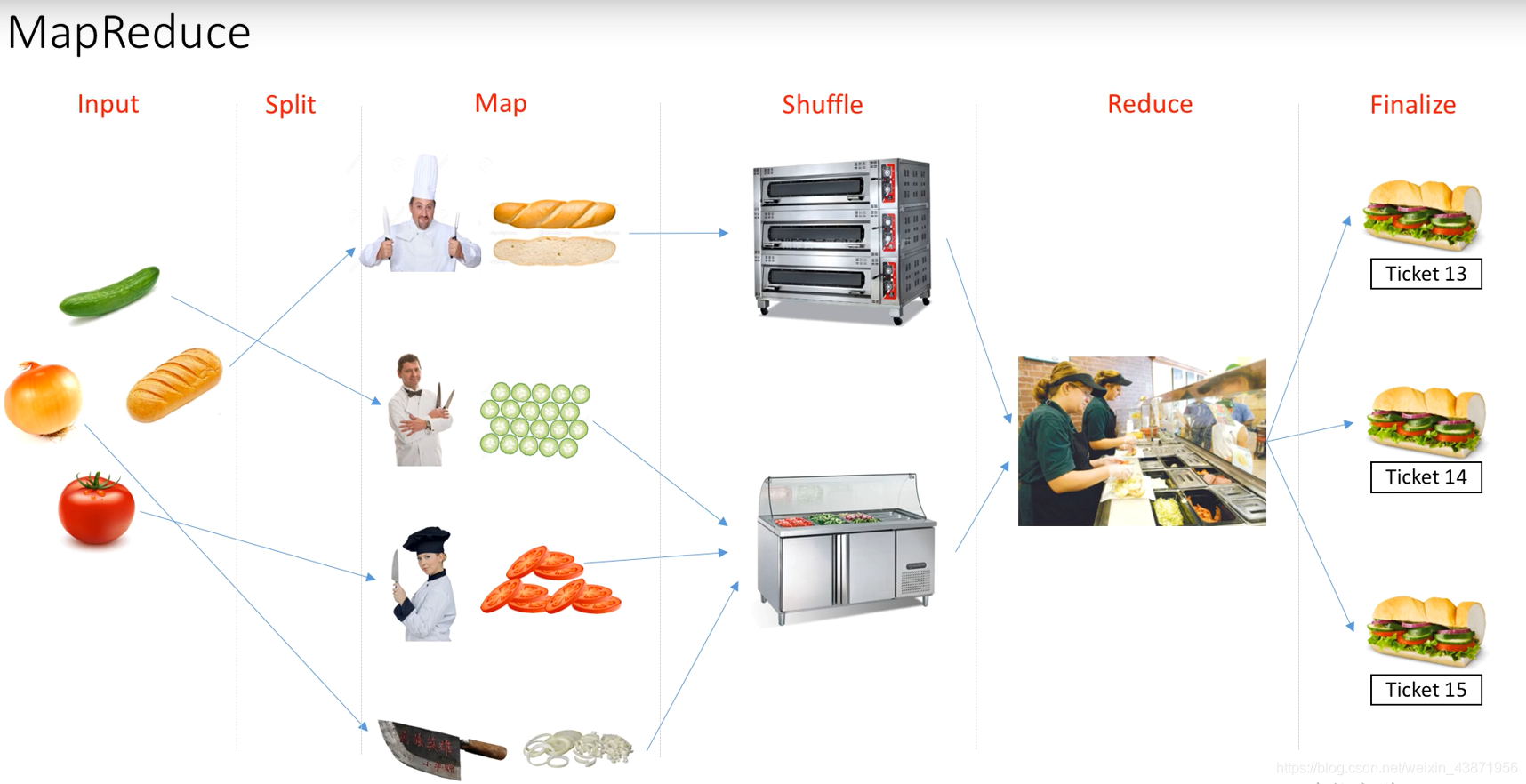
import java.io.IOException;
public class wordcount {
// KEYIN,VALUEIN,KEYOUT,VALUEOUT
//map和reduce 的数据输入输出都是以key-value对的形式封装
public static class WCMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
// 每读一行数据就调用一次方法
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// key 是这一行的起始偏移量 value 是这一行的文本内容
String line = value.toString();
String[] words = line.split(" ");
for(String word : words){
context.write(new Text(word),new LongWritable(1));
}
}
}
public static class WCReducer extends Reducer<Text, LongWritable,Text,LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values){
count+= value.get();
}
//输出这一个单词的统计结果
context.write(key,new LongWritable(count));
}
}
}
WCrun类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WCRun {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job WCjob = Job.getInstance(conf);
WCjob.setJarByClass(WCRun.class);
WCjob.setMapperClass(wordcount.WCMapper.class);
WCjob.setReducerClass(wordcount.WCReducer.class);
//指定reduce的输出数据kv类型
WCjob.setOutputKeyClass(Text.class);
WCjob.setOutputValueClass(LongWritable.class);
WCjob.setMapOutputKeyClass(Text.class);
WCjob.setMapOutputValueClass(LongWritable.class);
//指定原始数据存放位置
FileInputFormat.setInputPaths(WCjob,new Path("/wc/srcdata/"));
FileOutputFormat.setOutputPath(WCjob,new Path("/wc/output/"));
WCjob.waitForCompletion(true);
}
}
