

最近跟着视频学习了mustache的实现原理,简单记录下,方便以后捡起来
前言
mustache是一款前端模板解析引擎,例如可以将<p>{{name}}</p>解析为<p>张三</p>,这和vue的template语法是很相似的。那么它是如何实现的呢?
我一开始以为的是用正则表达式来实现,例如用下面的代码可以实现简单的替换
let str = `<p>我是{{name}},今年{{age}}岁</p>`;
let data = {
name: "张三",
age: 18,
};
// 使用非贪婪匹配
str = str.replace(/{{(.+?)}}/g, (_, key) => {
console.log(key, "key");
return data[key];
});
console.log(str, "str");
替换结果
但是这并不适用于复杂的情况,例如当出现数组和嵌套数组的时候,正则已经没法处理了。那么想要处理更加复杂的情况,就开始学习mustache的解析流程吧
mustache解析流程
1. 将模板字符串解析为多维数组
需要把<p>我是{{name}},今年{{age}}岁</p>这种模板字符串解析为这种多维数组。
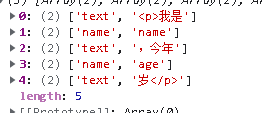
首先定义一个ScanUtil类,这个类的作用是对这个字符串进行逐个扫描解析,将{{之前的文字存成[text,文字]的数组,将{{ }}之间的文字存为[name,文字]的数组。代码如下:
export class ScanUtil {
// 初始化模板字符串和指针位置
constructor(templateStr) {
this.templateStr = templateStr;
this.pos = 0;
}
// 指针之后的字符串,表示还没遍历
get tail() {
return this.templateStr.substring(this.pos);
}
// 是否已经完成了遍历
get eos() {
return this.pos >= this.templateStr.length;
}
// tag字符串是否处于开始位
tagIsInBegin(tag) {
return this.tail.startsWith(tag);
}
// 跳过tag的位置
skip(tag) {
if (this.tagIsInBegin(tag)) {
this.pos += tag.length;
}
}
// 扫描截取目标文字
scanText(tag) {
const prePos = this.pos;
while (!this.tagIsInBegin(tag) && !this.eos) {
this.pos++;
}
let res = this.templateStr.substring(prePos, this.pos);
// 指针跳过tag
this.skip(tag);
return res;
}
// 循环遍历,返回tokens数组
compileStrToTokens() {
let res = [];
while (!this.eos) {
// 截取到{{前的文字
let text = this.scanText("{{");
// 把结果加入到数组里
res.push(["text", text]);
// 截取{{到}}中的文字
let name = this.scanText("}}");
// 把结果加入到数组里
res.push(["name", name]);
}
return res;
}
}
使用templateStr存储传入的字符串,用pos存储指针指向的位置,用scanText来扫描截取目标文字,用skip来掉过{{和}}的位置。现在已经可以处理简单的情况了,调用这个类来测试一下:
let str = `<p>我是{{name}},今年{{age}}岁</p>`;
let data = {
name: "张三",
age: 18,
};
let scanner = new ScanUtil(str);
console.log(scanner.compileStrToTokens(),"scanner.compileStrToTokens()")
输出结果如下:
但是现在如果需要处理数组的话,还差两步。
-
将数组存为
['#','arr']和['/','arr']的结构#表示数组的开始,/表示数组的结束。修改compileStrToTokens函数,使用正则判断name值是否包含了#或/
// 循环遍历,返回tokens数组 compileStrToTokens() { let res = []; while (!this.eos) { // 截取到{{前的文字 let text = this.scanText("{{"); // 把结果加入到数组里 res.push(["text", text]); // 截取{{到}}中的文字 let name = this.scanText("}}"); // 判断{{到}}的文字是变量还是数组 if (/[#/]/.test(name)) { res.push([name.substring(0, 1), name.substring(1)]); } else { // 如果到}}后没有变量了,这里的name不一定有值了, name && res.push(["name", name]); } } return res; }测试现在数组的解析情况
let str = ` {{#arr}} <span>{{name}}</span> {{/arr}} `; let data = { arr:[ {name:"测试1"}, {name:"测试2"}, ] }; let scanner = new ScanUtil(str); console.log(scanner.compileStrToTokens(),"scanner.compileStrToTokens()")输出结果
-
将需要循环的项全部存在数组的第三个元素里
['#','arr',[]]将上面图中序号为2,3,4项存在数组的第三个元素里,这里的算法会稍微复杂一些了。
考虑到模板字符串中可能存在多层嵌套的结构,所以这里使用递归进行判断,并模拟了一个栈结果的数组来存放当前元素应该插入到第几层的数组里。
// [1,1,1,#,1,1,#,1,1,/,/] =>[1,1,1,[#,[1,1,[#,1,1]]]] export function nestTokens(tokens) { // 获取数组的最后一个元素,而不修改原数组 const _getLastEle = (arr) => [...arr].pop(); // 结果数组,存储返回结果 let resTokens = []; // 栈数组 let sections = [resTokens]; //除了/以外的每个元素都需要被push进入结果数组进行保存,但是不能直接push到结果数组中,而是push到收集器中,收集器引用结果数组或者结果数组的某个元素 let collector = _getLastEle(sections); tokens.forEach((token) => { switch (token[0]) { // 遇到数组时,先存储该结点,然后修改收集器的指向,并存储该收集器 case "#": collector.push(token); collector = token[2] = []; // 入栈,用于给下次收集器赋值 sections.push(collector); break; // 数组结束,将当前收集器出栈,并取栈顶的收集器 case "/": sections.pop(); collector = _getLastEle(sections); break; // 收集器收集该元素 default: collector.push(token); break; } }); return resTokens; }修改一下刚刚的
compileStrToTokens的函数// 循环遍历,返回tokens数组 compileStrToTokens() { let res = []; while (!this.eos) { // 截取到{{前的文字 let text = this.scanText("{{"); // 把结果加入到数组里 res.push(["text", text]); // 截取{{到}}中的文字 let name = this.scanText("}}"); // 判断{{到}}的文字是变量还是数组 if (/[#/]/.test(name)) { res.push([name.substring(0, 1), name.substring(1)]); } else { // 如果到}}后没有变量了,这里的name不一定有值了, name && res.push(["name", name]); } } return this.nestTokens(res); }那么结果就变为了
目前为止将模板字符串解析为多维数组已经完成了,已经支持模板字符串的多级嵌套了。
2.将多维数组编译为目标字符串
将多维数组编译为目标字符串要简单一些了。只需要把多维数组的每一项数组的第二个元素转化为值相加即可,如果是数组的情况,就遍历数组,递归调用该函数。
export function compileTokensToStr(tokens, data) {
return tokens.reduce((res, token) => {
let type = token[0];
let value = token[1];
// 如果是文本节点,直接加上
if (type === "text") {
res += value;
}
// 如果是数组,递归调用
else if (type === "#") {
res += data[value].map(item => compileTokensToStr(token[2], item)).join("");
}
// 如果是变量, 从data里取值加上,如果有{{.}}表示当前元素
else {
res += _isDot(value) ? data : data[value];
}
return res;
}, "");
}
最后的测试代码
let str = `
{{#arr}}
<span>{{name}}</span>
{{/arr}}
`;
let data = {
arr: [
{name: "测试1"},
{name: "测试2"},
],
};
let scanner = new ScanUtil(str);
let tokens = scanner.compileStrToTokens();
console.log(tokens, "scanner.compileStrToTokens()");
let aimStr = compileTokensToStr(tokens,data);
console.log(aimStr, "aimStr");
测试结果
最后
mustache库是很强大的,不仅处理了数组的形式,还支持布尔型还有函数等。这里虽然只处理了数组的形式,但是整体逻辑是完整的。学习mustache,学到了一种处理字符串的思路,使用指针这种思路来遍历字符串,使用栈这种思路来合并处理数组。
