敏感词|屏蔽字过滤器 DFA算法 升级版增加严格模式强力去除敏感词
该算法经测试在 13993 个敏感词中过滤 26 个字符的文字耗时为:0 ms
package test1;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
class WordNode {
public boolean isEnd;
public WordNode parentNode;
public Map<String, WordNode> children = new HashMap<String, WordNode>();
public String value = "";
public WordNode getChild(String name){
return this.children.get(name);
}
public WordNode addChild(String name) {
WordNode node = new WordNode();
node.parentNode = this;
this.children.put(name, node);
return node;
}
}
public class DFAWords {
public WordNode treeRoot = new WordNode();
public void addWords(String[] words) {
for(String word: words) {
int wordLength = word.length();
if(wordLength > 0) {
WordNode node = this.treeRoot;
for(String name: word.split("")) {
WordNode temp = node.getChild(name);
if(temp != null) {
node = temp;
}
else {
node = node.addChild(name);
}
}
node.isEnd = true;
}
}
}
public List<Integer> searchWords(String word, boolean strict){
List<Integer> words = new ArrayList<Integer>();
String[] chars = word.split(""); 过滤字符串数组
if(chars.length > 0 && this.treeRoot != null) {
WordNode node = this.treeRoot;
List<Integer> vwords = new ArrayList<Integer>();
List<Integer> alone = new ArrayList<Integer>();
String str = "";
WordNode chilhNode = null;
boolean complete = false;
for (int i = 0; i < chars.length; i++) {
str = chars[i];
chilhNode = node.getChild(str);
if(chilhNode == null) {
node = this.treeRoot;
vwords.clear();
}
chilhNode = node.getChild(str);
if(chilhNode != null) {
node = chilhNode;
vwords.add(i);
if(chilhNode.isEnd) {
words.addAll(vwords);
vwords.clear();
}
}
}
if(strict) do {
vwords.clear();
node = this.treeRoot;
for (int i = 0; i < chars.length; i++) {
if(words.contains(i) || alone.contains(i)) continue;
str = chars[i];
chilhNode = node.getChild(str);
if(chilhNode != null) {
node = chilhNode;
vwords.add(i);
if(chilhNode.isEnd) {
words.addAll(vwords);
node = this.treeRoot;
}
}
}
if(node.isEnd == false) {
alone.addAll(vwords);
}
complete = vwords.size() == 0;
} while (complete == false);
}
return words;
}
public String filter(String word) {
return this.filter(word, "*", true);
}
public String filter(String word, boolean strict) {
return this.filter(word, "*", strict);
}
public String filter(String word, String repStr, boolean strict) {
StringBuffer words = new StringBuffer(word);
for (int i : this.searchWords(word,strict)) {
words.replace(i, i + 1, repStr);
}
return words.toString();
}
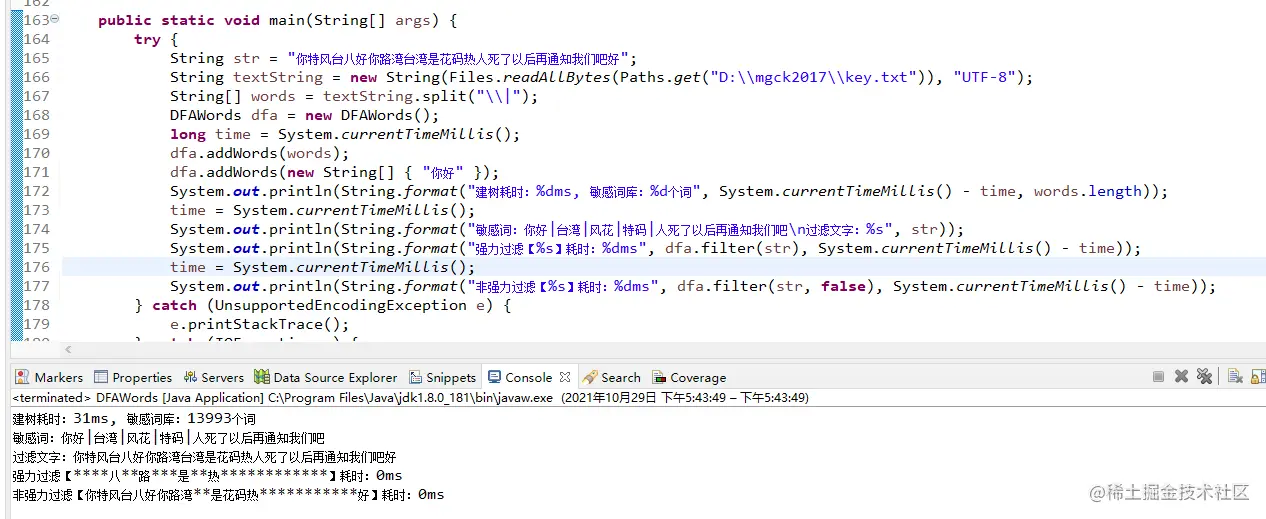
public static void main(String[] args) {
try {
String str = "你特风台八好你路湾台湾是花码热人死了以后再通知我们吧好";
String textString = new String(Files.readAllBytes(Paths.get("D:\\mgck2017\\key.txt")), "UTF-8");
String[] words = textString.split("\\|");
DFAWords dfa = new DFAWords();
long time = System.currentTimeMillis();
dfa.addWords(words);
dfa.addWords(new String[] { "你好" });
System.out.println(String.format("建树耗时:%dms, 敏感词库:%d个词", System.currentTimeMillis() - time, words.length));
time = System.currentTimeMillis();
System.out.println(String.format("敏感词:你好|台湾|风花|特码|人死了以后再通知我们吧\n过滤文字:%s", str));
System.out.println(String.format("强力过滤【%s】耗时:%dms", dfa.filter(str), System.currentTimeMillis() - time));
time = System.currentTimeMillis();
System.out.println(String.format("非强力过滤【%s】耗时:%dms", dfa.filter(str, false), System.currentTimeMillis() - time));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}


