

http协议
应用层
负责应用程序之间的数据沟通(我们程序员写的一个个解决我们实际问题, 满足我们日常需求的网络程序, 都是在应用层)
自定制协议
结构化数据的传输(通过结构体在内存中对数据对象进行组织,将二进制数据传输出去)
使用结构体进行数据对象的二进制结构化组织,进行数据传输/可持久化数据存储
- 序列化:将数据对象按照指定协议进行组织成可持久化存储/数据传输的二进制数据串
- 反序列化:将持久化存储/数据传输的二进制数据串按照指定协议解析出各个数据对象
网络版计算器
例如, 我们需要实现一个服务器版的加法器. 我们需要客户端把要计算的两个加数发过去, 然后由服务器进行计算, 最后再把结果返回给客户端.
约定方案一:
- 客户端发送一个形如"1+1"的字符串;
- 这个字符串中有两个操作数, 都是整形;
- 两个数字之间会有一个字符是运算符, 运算符只能是 + ;
- 数字和运算符之间没有空格;
- …
约定方案二:
- 定义结构体来表示我们需要交互的信息;
- 发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候按照相同的规则把字符串转化回结构体;
- 这个过程叫做 “序列化” 和 “反序列化”
// proto.h 定义通信的结构体
typedef struct Request {
int a;
int b;
} Request;
结构化数据传输好处:
- 用户感受不到数据对象按照指定协议组织以及解析的过程
- 并且通过结构成员变量指向内存各处的方式,可以更加快捷的获取到数据对象,反序列化非常快
二进制序列化优点:反序列化解析速度快
常见的数据序列化方式还有很多:json序列化;protobuf序列化
无论我们采用方案一, 还是方案二, 还是其他的方案, 只要保证, 一端发送时构造的数据, 在另一端能够正确的进行解析, 就是ok的. 这种约定, 就是应用层协议
HTTP协议
HTTP协议:超文本传输协议
优点:http协议给程序员留有一定的自定制空间
网址
统一资源定位符(定位网络中唯一的一份资源)- URL
统一资源定位符如何定位网络中唯一的资源? - URL的格式以及所包含的要素
网址的元素:
协议方案名称://用户名:密码@服务器IP地址:端口/资源路径?查询字符串#片段标识符
- 协议方案名称:http / https / ftp
- 服务器IP地址:域名 - 服务器地址解析的一种方式 - 以更容易记忆的字符串来表示服务器地址 - 最终还是要被解析得到服务器的IP地址
- 服务器端口:http默认使用80端口/https默认使用443端口
- /资源路径:请求的资源在服务器上的路径 - 这个路径是一个相对根目录 - 为了告诉服务器自己想要什么
- 查询字符串:一个个key = val 形式的键值对,键值对之间以&间隔; - 提交给服务器的数据
url编码、解码
用户提交给服务器的查询字符串中的val需要进行url编码 — 因为url中有很多的特殊字符具有特殊含义,若用户提交的数据中也包含有相同的特殊字符就会造成歧义,因此需要对val进行url编码操作
- url编码(urlencode)
将特殊字符的每一个字节,都转换成为16进制数字的字符,例如: + -> 2b ;万一要是用户本身提交的数据就有2b,也会造成歧义;因此对每一个字节进行转换之后,需要在前边加上%表示紧跟其后的两个字符经过了url编码 + -> %2b
- url解码(urldecode)
得到查询字符串后,在val中遇到%,则认为紧跟其后的两个字符需要解码 - 将两个字符转换为数字 %2b -> 2 11;
第一个数字左移4位或者第一个数字乘以16+后边的数字 :2*16 + 11
HTTP协议格式
http协议的实现(http协议的数据结构)
fiddler工具:浏览器的抓包工具,抓取浏览器与服务器之间的通信数据
首行:
- 请求首行:
包含三大信息,以空格进行间隔,并且以\r\n作为结尾; 请求方法 URL 协议版本
请求方法:
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
- GET:请求获取一个资源,并要求服务器返回实体数据
- POST:向服务器提交要被处理的数据
- HEAD:请求获取一个资源,但是并不要求服务器返回实体数据,只要相应头部信息
| 方法 | 描述 |
|---|---|
| PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| DELETE | 请求服务器删除指定的页面。 |
| CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| OPTIONS | 允许客户端查看服务器的性能。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
GET / POST 的区别:
- get也能够向服务器提交数据,但是提交的数据是在url的查询字符串中(get是没有正文的)/而post提交的数据是在正文中
- get提交数据是不太安全的,并且url的长度是有限制的,早期1K,现在很多都是4K/8K,而post无限制
- get安全性非常低,post安全性较高。(get传输方式将在URL中显示参数;GET方法中不对数据进行修改,不传送一些保密的信息,而这些需要由POST来传输)
- 在做数据查询时,建议用Get方式;而在做数据添加、修改或删除时,建议用Post方式;
GET和POST还有一个重大区别,简单的说:
- GET产生一个TCP数据包;POST产生两个TCP数据包。
详细的说:
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
URL:
主要信息就是请求的资源路径以及提交的查询字符串
协议版本:
HTTP/1.1 0.9/1.0/1.1/2.0
- 0.9:默认只支持GET请求方法,并且仅能请求访问HTML格式的资源。
- 1.0:支持了GET/HEAD/POST请求方法,并且是 短连接 (http在传输层使用tcp协议,短连接指的是发送一个请求,得到相应后关闭连接)
- 1.1:支持了更多的请求方法,并且新增了更多的特性,比如默认支持 长连接 ,并且实现管线化传输
- 2.0:比如以前都是客户端主动向服务器发送请求,但是在2.0中支持服务端向客户端主动推送消息(多路IO复用,可以同时处理多个请求)
使用长连接的HTTP协议,会在响应头有加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的 TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接要客户端和服务端都支持长连接。
HTTP长连接与TCP长连接的区别:
HTTP的长连接和短连接本质上是TCP长连接和短连接。 HTTP属于应用层协议,在传输层使用TCP协议,在网络层使用IP协议。IP协议主要解决网络路由和寻址问题,TCP协议主要解决如何在IP层之上可靠的传递数据包,使在网络上的另一端收到发端发出的所有包,并且顺序与发出顺序一致。TCP有可靠,面向连接的特点。
管道机制:在同一个TCP连接里,允许多个请求同时发送,增加了并发性,进一步改善了HTTP协议的效率;举例来说,客户端需要请求两个资源。以前的做法是,在同一个TCP连接里面,先发送A请求,然后等待服务器做出回应,收到后再发出B请求。管道机制则是允许浏览器同时发出A请求和B请求,但是服务器还是按照顺序,先回应A请求,完成后再回应B请求。
HTTP/2.0:
为了解决1.1版本利用率不高的问题,提出了HTTP/2.0版本。增加双工模式,即不仅客户端能够同时发送多个请求,服务端也能同时处理多个请求,解决了队头堵塞的问题(HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级);HTTP请求和响应中,状态行和请求/响应头都是些信息字段,并没有真正的数据,因此在2.0版本中将所有的信息字段建立一张表,为表中的每个字段建立索引,客户端和服务端共同使用这个表,他们之间就以索引号来表示信息字段。这样就避免了1.0旧版本的重复繁琐的字段,并以压缩的方式传输,提高利用率。
另外也增加服务器推送的功能:不经请求服务端主动向客户端发送数据。
当前主流的协议版本还是HTTP/1.1版本。
HTTP 3.0 (QUIC):
QUIC (Quick UDP Internet Connections), 快速 UDP 互联网连接。(QUIC是基于UDP协议的)
两个主要特性:
- 线头阻塞(HOL)问题的解决更为彻底:
基于TCP的HTTP/2,尽管从逻辑上来说,不同的流之间相互独立,不会相互影响,但在实际传输方面,数据还是要一帧一帧的发送和接收,一旦某一个流的数据有丢包,则同样会阻塞在它之后传输的流数据传输。而基于UDP的QUIC协议则可以更为彻底地解决这样的问题,让不同的流之间真正的实现相互独立传输,互不干扰。
- 切换网络时的连接保持:
当前移动端的应用环境,用户的网络可能会经常切换,比如从办公室或家里出门,WiFi断开,网络切换为3G或4G。 基于TCP的协议,由于切换网络之后,IP会改变,因而之前的连接不可能继续保持。而基于UDP的QUIC协议,则可以内建与TCP中不同的连接标识方法,从而在网络完成切换之后,恢复之前与服务器的连接。
- 响应首行:
包含3大信息,以空格进行间隔,以\r\n作为结尾; 协议版本 响应状态码 状态码描述\r\n
-
协议版本:0.9/1.0/1.1/2.0
-
响应状态码:向客户端反应本次请求的处理结果状态 — 包含5大种类:1xx / 2xx / 3xx / 4xx / 5xx
- 1xx:一些描述信息
- 2xx:本次请求正确处理完毕 200 - 请求成功
- 3xx:重定向,本次请求的资源可能移动到其他位置,请客户端重新请求新的位置 301 - 永久重定向/ 302 - 临时重定向/ 303 - 查看其他
- 4xx:客户端错误;400 - 客户端请求的语法错误/404 - 客户端无法根据客户端请求找到资源
- 5xx:服务端错误;500 - 服务器内部错误,无法完成请求 / 502 - 代理给浏览器发送请求,连接失败 / 504 - 代理给浏览器发送请求,浏览器半天不响应
- 状态码描述:对于本次状态码的描述信息(描述也可以自定义)
头部:
一个个key: val形式的键值对,键值对之间以\r\n作为间隔
-
Connection:描述当前连接是否是长连接(close/keep-alive)
-
Content-Length:描述当前正文有多长(通过这个描述信息可以告诉对端本次请求应该接收多长的数据)
-
Content-Type:描述了正文的类型 - 告诉对方应该如何处理正文 test/html
-
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
-
User-Agent: 声明用户的操作系统和浏览器版本信息;
-
Accept:告诉对端自己能够接收什么样的数据
-
Referer:告诉服务器,本次请求是从哪个网页点击请求过来的
-
Transfer-Encoding:chunked 正文的分块传输 - 将正文分块传输,每块在发送前先告诉对方这块数据有多长; 0\r\n\r\n表示分块结束
常用于服务端本身不确定自己要响应的数据有多长的时候 -
Location: http://123.207.58.25/ 搭配3xx状态码使用;通过描述的地址信息告诉客户端资源重新去请求指定的这个地址
-
Cookie/Set-Cookie:http协议是一个无状态协议,
- 网上购物:http是一个短链接;买一个硬盘,需要登录一次;买个键盘,又要登录一次…
- 服务端为每一个登陆的客户端在服务端主机上创建一个session(会话);会话中描述了客户端的各种信息;将session保存在数据库中。然后通过Set-Cookie将session_id以及重要的信息返回给客户端;客户端会将其中的信息保存在cookie文件中;
- 下一次请求服务端的时候,会自动从cookie文件中读取出信息,通过Cookie传递给服务端,服务端收到Cookie之后取出信息-session_id,通过这个id在数据库中找到对应信息,就知道当前这个客户端是谁了
cookie与session有什么区别:
- session 是服务端为每一个客户端单独创建的会话,保存在服务端,其中有客户端的认证信息…
- cookie 是服务端通过Set-Cookie响应给客户端的信息,保存在客户端,下次请求服务器的时候会携带有cookie信息
长连接是如何实现的
在HTTP1.0和HTTP1.1协议中都有对长连接的支持。其中HTTP1.0需要在request(请求)中增加”Connection: keep-alive“ header(头部)才能够支持,而HTTP1.1默认支持.
- 空行:
\r\n - 间隔头部与正文
头部中最后一个头部信息也是\r\n作为结尾的;空行的重要性在于判断是否接收了完整的http头部信息
first_line\r\nkey: val\r\nkey: val\r\n……key: val\r\n\r\ncontent
通常接受http数据的流程:
- 接收完整的http头部 - 接收数据直到遇到\r\n\r\n的时候,认为头部到此结束
- 解析头部,根据头部中的Content-Length决定,正文应该接收多长;接收相应长度的正文
正文:
客户端提交给服务端的数据 / 服务端响应给客户端的数据
编写一个简单的http服务器
http协议是应用层协议,在传输层使用的是tcp协议
-
搭建tcp服务器
-
等待连接到来,接收http数据(应用层数据)
- 接收http头部数据
- 解析头部(请求方法+url(资源路径+查询字符串) + 协议版本 + 各个头部键值对)
- 根据头部中的Content-Length接收正文
-
针对客户端的请求进行业务功能的处理,处理完毕之后组织http响应数据,发送给客户端
- 业务处理(跟具体的业务相关,不讨论)
- 根据http相应格式组织相应数据(首行(协议版本+状态码+描述)+ 头部 + 正文)
- 响应给客户端
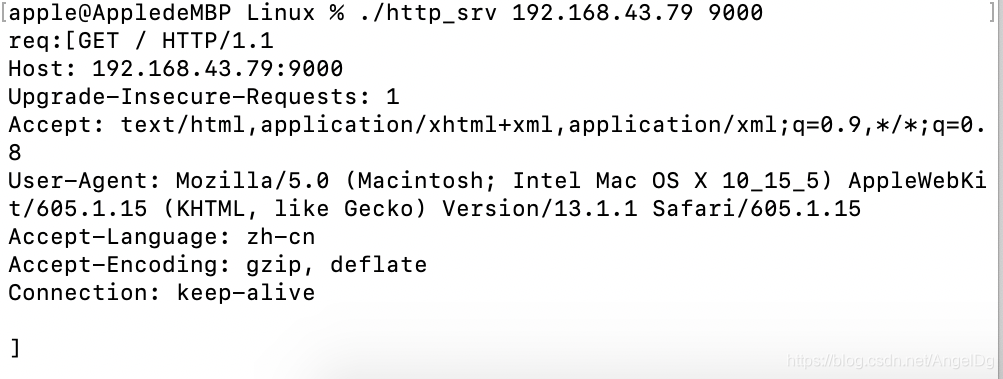
搭建一个http服务器,收到请求之后打印出来,然后组织一个响应hello world给客户端就行
// 使用封装的TcpSocket类实例化对象实现tcp服务端程序
#include <iostream>
#include <sstream>
#include <stdlib.h>
#include "tcpsocket.hpp"
int main(int argc, char *argv[]){
if(argc != 3){
printf("em:./tcp_srv 192.168.122.132 9000\n");
return -1;
}
std::string ip = argv[1];
uint16_t port = std::stoi(argv[2]); // stoi将字符串转换为数字
TcpSocket lst_sock;
CHECK_RET(lst_sock.Socket());
CHECK_RET(lst_sock.Bind(ip, port));
CHECK_RET(lst_sock.Listen());
while(1){
TcpSocket cli_sock;
bool ret = lst_sock.Accept(&cli_sock);
if(ret == false){
continue;
}
std::string http_req;
cli_sock.Recv(&http_req);
printf("req:[%s]\n", http_req.c_str());
// 响应-首行(版本/状态码/描述)-描述(Content-Length)-空行-正文
std::string body = "<html><body><h1>Hello, Miss Xia Yanxin! I Love you~~ </h1></body></html>";
std::string blank = "\r\n";
std::stringstream header;
header << "Content - Length: " << body.size() << "\r\n";
header << "Content-Type: text/html\r\n";
std::string first_line = "HTTP/1.1 200 OK\r\n";
cli_sock.Send(first_line);
cli_sock.Send(header.str());
cli_sock.Send(blank);
cli_sock.Send(body);
cli_sock.Close();
}
lst_sock.Close();
return 0;
}
// 封装实现一个tcpsocket类,向外提供简单接口:
// 使外部通过实例化一个tcpsocket对象就能完成tcp通信程序的建立
#include <cstdio>
#include <string>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <netinet/in.h>
#define BACKLOG 10
#define CHECK_RET(q) if((q)== false){return -1;}
class TcpSocket{
public:
TcpSocket():_sockfd(-1){
}
int GetFd(){
return _sockfd;
}
void SetFd(int fd){
_sockfd = fd;
}
// 创建套接字
bool Socket(){
// socket(地址域,套接字类型,协议类型)
_sockfd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
if(_sockfd < 0){
perror("socket error");
return false;
}
return true;
}
void Addr(struct sockaddr_in *addr, const std::string &ip, uint16_t port){
addr->sin_family = AF_INET;
addr->sin_port = htons(port);
inet_pton(AF_INET, ip.c_str(), &(addr->sin_addr.s_addr));
}
// 绑定地址信息
bool Bind(const std:: string &ip, const uint16_t port){
// 定义IPv4地址结构
struct sockaddr_in addr;
Addr(&addr, ip, port);
socklen_t len = sizeof(struct sockaddr_in);
int ret = bind(_sockfd, (struct sockaddr*)&addr, len);
if(ret < 0){
perror("bind error");
return false;
}
return true;
}
// 服务端开始监听
bool Listen(int backlog = BACKLOG){
// listen(描述符,同一时间的并发链接数)
int ret = listen(_sockfd, backlog);
if(ret < 0){
perror("listen error");
return false;
}
return true;
}
// 客户端发起连接请求
bool Connect(const std::string &ip, const uint16_t port){
// 1.定义IPv4地址结构,赋予服务端地址信息
struct sockaddr_in addr;
Addr(&addr, ip, port);
// 2.向服务端发起请求
// 3.connect(客户端描述符,服务端地址信息,地址长度)
socklen_t len = sizeof(struct sockaddr_in);
int ret = connect(_sockfd, (struct sockaddr*)&addr, len);
if(ret < 0){
perror("connect error");
return false;
}
return true;
}
// 服务端获取新建连接
bool Accept(TcpSocket *sock, std::string *ip = NULL, uint16_t *port = NULL){
// accept(监听套接字,对端地址信息,地址信息长度)返回新的描述符
struct sockaddr_in addr;
socklen_t len = sizeof(struct sockaddr_in);
// 获取新的套接字,以及这个套接字对应的对端地址信息
int clisockfd = accept(_sockfd, (struct sockaddr*)&addr, &len);
if(clisockfd < 0){
perror("accept error");
return false;
}
// 用户传入了一个Tcpsocket对象的指针
// 为这个对象的描述符进行赋值 --- 赋值为新建套接字的描述符
// 后续与客户端的通信通过这个对象就可以完成
sock->_sockfd = clisockfd;
if(ip != NULL){
*ip = inet_ntoa(addr.sin_addr); // 网络字节序ip->字符串IP
}
if(port != NULL){
*port = ntohs(addr.sin_port);
}
return true;
}
// 发送数据
bool Send(const std::string &data){
// send(描述符,数据,数据长度,选项参数)
int ret = send(_sockfd, data.c_str(), data.size(), 0);
if(ret < 0){
perror("send error");
return false;
}
return true;
}
// 接收数据
bool Recv(std::string *buf){
// recv(描述符,缓冲区,数据长度,选项参数)
char tmp[4096] = {0};
int ret = recv(_sockfd, tmp, 4096, 0);
if(ret < 0){
perror("recv error");
return false;
}
else if(ret == 0){
printf("connection break\n");
return false;
}
buf->assign(tmp, ret); // 从tmp中拷贝ret大小的数据到buf中
return true;
}
// 关闭套接字
bool Close(){
close(_sockfd);
_sockfd = -1;
return true;
}
private:
int _sockfd;
};
注意:
云服务器:服务器绑定ifconfig看到的内网地址;但是在浏览器上访问的时候,要访问外网地址;尤其要注意的是要在云服务器的控制台去设置安全做,开启防火墙端口
虚拟机:记住要先关闭防火墙,否则主机无法访问进来
su root 切换管理员
systemctl stop firlwalld 关闭防火墙(虚拟机重启后,又回打开,若要一直关闭可以采用下边的命令禁用防火墙)
systemctl disable firlwalld 禁用防火墙
HTTPS协议
其实就是加密后的HTTP协议(https设置的端口号为 443 / http: 80) (相会HTTP协议慢了也就0.1秒)
https到底是如何进行加密传输的?
通过 ssl加密( 非对称加密算法 / 对称加密算法) + 签名证书 保证数据的隐私安全传输
数据直接在网络中传输,很容易被劫持修改,有很大的安全隐患 — 所以要对传输过程进行加密
对称加密算法
如何加密就如何解密(加密算法和解密算法是一样的)
对称加密算法的优缺点
- 优点:加密解密效率比较高
- 缺点:容易被破解,使用时间稍长就会被中间劫持,根据数据规律破解出加密算法。
解决方案:最好能够每次通信都动态协商一个新的对称加密算法 — 有可能被劫持
非对称加密算法
加密和解密的方法不同 — 服务端生成一个公钥和私钥,将公钥传递给客户端,客户端使用公钥加密,服务端使用私钥揭秘。
公钥和私钥
通过加密算法-RAS算法,得到的一对密钥(就是两串数据),公钥用于对数据加密,私钥用于对加密后的数据进行解密;
因为加密方式和解密方式不同,因此很难被破解。就算中间公钥被人劫持,客户端使用公钥加密后的数据只能用私钥进行解密。
非对称加密算法的优缺点
- 优点:安全性高,不容易被破解
- 缺点:解密效率比较低
将非对称加密和对称加密结合起来加密
将客户端与服务端进行动态协商对称加密算法过程使用非对称加密;然后使用协商后的对称加密算法对数据通信过程进行加密;这样就即保证了安全,也保证了效率。
- 在通信前,服务器将公钥传递给对方
- 客户端使用公钥对自己支持的对称加密算法以及一个随机数进行加密,传递给服务器
- 服务器收到这个加密后的数据,使用私钥进行解密,得到客户端支持的对称加密算法和一个随机数,也给客户端响应一个随机数
- 双方通过这两个随机数和支持的加密算法计算得到一个对称加密算法
- 后续通信使用这个协商的对称加密算法完成
但是若中间黑客,劫持了公钥数据,然后将自己的公钥发送给客户端
因此公钥的传输也是存在安全隐患:对方的身份问题
如何确定发送公钥的这个服务端就是我心目中的那个服务端?
签名证书(CA):进行身份验证,并且传输公钥信息
注意:
公司生成一对密钥之后,拿着密钥去权威机构掏钱颁发生成一个签名证书,
证书中包含:公钥信息,权威机构信息,当前公司机构信息,有效时间…
ssl加密过程:
- 在通信的时候,连接建立成功之后,服务端就会先将证书发送给客户端,客户端根据证书中的机构信息,进行身份验证
- 若身份验证不通过,则可以直接断开连接(当然也可以设置是否信任这个机构)
- 若身份验证通过,然后使用证书中的公钥加密对称加密算法的协商过程,最终使用协商成功的对称加密算法对通信进行加密。
知识点习题
- 请描述http请求get和post的区别,下面描述正确的有:
A. GET用于信息获取,而且应该是安全的和幂等的,POST表示可能修改变服务器上的资源的请求
B. POST比GET安全,因为采用了SSL加密
C. GET方式提交的数据最多只能是1024字节,理论上POST没有限制,可传较大量的数据
D. POST提交,把提交的数据放置在是HTTP包的包体中,GET提交的数据会在地址栏中显示出来
正确答案:A,C,D
答案解析
GET与POST方法有以下区别:
- 在客户端, Get 方式在通过 URL 提交数据,数据在URL中可以看到;POST方式,数据放置在HTML HEADER内提交。
- GET方式提交的数据最多只能有1024字节,而POST则没有此限制。
- 安全性问题。正如在( 1 )中提到,使用 Get 的时候,参数会显示在地址栏上,而 Post 不会。所以,如果这些数据是中文数据而且是非敏感数据,那么使用 get没什么影响 ;如果用户输入的数据不是中文字符而且包含敏感数据,那么还是使用 post 为好。
- 安全的和幂等的。所谓 安全的 意味着该操作用于获取信息而非修改信息。幂等的意味着对同一 URL 的多个请求应该返回同样的结果。完整的定义并不像看起来那样严格。换句话说, GET 请求一般不应产生副作用。从根本上讲,其目标是当用户打开一个链接时,她可以确信从自身的角度来看没有改变资源。比如,新闻站点的头版不断更新。虽然第二次请求会返回不同的一批新闻,该操作仍然被认为是安全的和幂等的,因为它总是返回当前的新闻。反之亦然。 POST 请求就不那么轻松了。 POST 表示可能改变服务器上的资源的请求。仍然以新闻站点为例,读者对文章的注解应该通过 POST 请求实现,因为在注解提交之后站点已经不同了(比方说文章下面出现一条注解)。
https采用了SSL加密
- HTTP 的会话有四个过程,请选出不是的一个。( )
A. 建立连接
B. 发出请求信息
C. 发出响应信息
D. 传输数据
正确答案:D
答案解析:
- 建立TCP连接
- 发出请求文档
- 发出响应文档
- 释放tcp连接
- 以下 http 状态码描述错误的是?()
A. 200 正常响应
B. 304 重定向
C. 403 无权限
D. 505 服务端错误
正确答案: B
答案解析:
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用***。所请求的资源必须通过***访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求的身份认证,与401类似,但请求者应当使用进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的PUT请求是可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 充当网关或***的服务器,从远端服务器接收到了一个无效的请求 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或***的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
- 下列关于HTTP协议,描述正确的是
A.HTTP协议工作在应用层
B.HTTP只能使用80端口,HTTPS只能使用443端口
C.HTTP是有状态协议
D.HTTP协议支持一定时间内的TCP连接保持,这个连接可以用于发送/接收多次请求
正确答案: A,D
答案解析:
- HTTP是应用层协议。
- HTTP常用端口80/8080/3128/8081/9098,HTTPS默认端口TCP/443,UDP/443。
- HTTP是无状态协议。
协议的状态是指下一次连接而维护这次连接所传输的信息,比如客户获得一张网页之后关闭浏览器,然后再一次启动浏览器,再登陆该网站,但是服务器并不知道客户关闭了一次浏览器。由于Web服务器要面对很多浏览器的并发访问,为了提高Web服务器对并发访问的处理能力,在设计HTTP协议时规定Web服务器发送HTTP应答报文和文档时,不保存发出请求的Web浏览器进程的任何状态信息。这有可能出现一个浏览器在短短几秒之内两次访问同一对象时,服务器进程不会因为已经给它发过应答报文而不接受第二期服务请求。由于Web服务器不保存发送请求的Web浏览器进程的任何信息,因此HTTP协议属于无状态协议,可以通过Cookie和Session将状态分别保存在客户端和服务器端,
- HTTP是建立在TCP协议之上的,建立和释放连接的时间都很短,所以HTTP是一种短连接,为了解决每次连接释放效率低的问题,提出keep-alive保持连接特性,可以在一段时间内多次发送、接收,
- 在公钥密码体系中,不可以公开的是
A.公钥
B.公钥和加密算法
C.私钥
D.私钥和加密算法
正确答案: C
答案解析
公钥加密体制有两个不同的密钥,它可将加密功能和解密功能分开。一个密钥称为私钥,它被秘密保存。另一个密钥称为公钥,不需要保密。公钥加密的加密算法和公钥都是公开的。
如果本篇博文有帮助到您,请留赞激励一下博主呐~~
