

![]() 1.为什么要使用配置项
1.为什么要使用配置项
参数化配置可以优化代码性能
- 调整超时时间请求快速失败,防止系统的雪崩,提升系统可用性
- 调整HTTP客户端连接池的大小,提升第三方HTTP服务的并行处理能力,提升系统性能
- 数据库地址、http服务的域名、本地内存最大缓存数量
2.如何进行配置管理
-
Linux中的参数变量
-
dirty_writeback_centisecs调整脏数据到磁盘的频率\
-
tcp_max_syn_backlog 建立连接队列的长度\
-
-
Linux生效方式
- 重启服务器
- sysctl 动态调整\
-
管理配置的方式
-
使用单独的配置文件 properties xml yaml
- 缺点:即使修改配置,也需要重新打包
-
配置文件进行管理
-
单独的目录中,不需要重新打包了
-
缺点:仍然需要重启服务,重新载入配置文件
-
Tomcat、Nginx、tcp_max_syn_backlog\
-
进阶:在固定目录下例如/data/confs,然后通过git拉取配置文件
-
进阶:不同机房读取的配置不同,优先读取本地机房,再读取其他机房
-
-
配置中心进行管理
-
微服务架构的标准组件
-
携程开源的 Apollo\
-
Apollo 支持不同环境,不同集群的配置,有完善的管理功能,支持灰度发布、更改热发布等功能,在所有配置中心中功能比较齐全\
-
-
百度开源的 Disconf\
-
360 开源的 QConf\
-
Spring Cloud 的组件 Spring Cloud Config\
-
......
-
-
2.1配置中心
功能:配置项的存储和读取
存储:
Disconf、Apollo 使用的是 MySQL
QConf 使用的是 ZooKeeper
微博的配置中心使用 Redis 来存储信息,而美图用的是 Etcd
按照机房维度进行存储
| ``` /confs/global/{env}/{project}/{service}/{version}/{module}/{key} //全局配置 /confs/regions/{env}/{project}/{service}/{version}/{region}/{module}/{key} //机房配置 /confs/nodes/{env}/{project}/{service}/{version}/{region}/{node}/{module}/{key} //节点配置
| ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
### 2.1.1变更推送如何实现
目标:将配置的变更推送给服务端,这样就可以实现配置的动态变更,也就是说不需要重启服务器就能让配置生效了
实现方式:
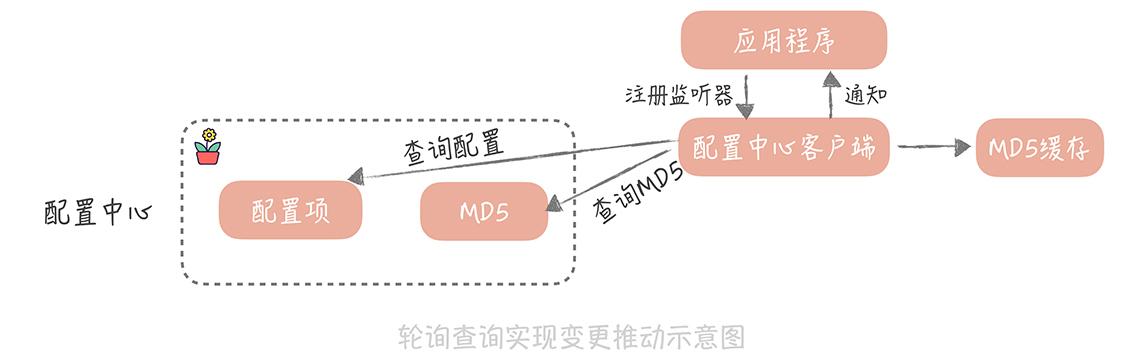
1.轮训查询
客户端定时轮训配置中心,如果有变化则通知触发器,让应用程序得到变更通知
进阶:手动比较文件是否一致会造成带宽瓶颈,可以比较MD5值。当MD5值不一致时才拉取最新配置
建议优先使用轮训的方式
\
2.长链接推送
服务端保存每个连接关注的配置列表(不是所有机器订阅所有配置)
难点:
1.保持长链接,失败重试
2.需要保证配置的订阅关系
### 2.1.2保证配置中心高可用
配置中心的可用性远远大于性能
保证即使配置中心宕机,应用程序可以启动
抓手:
- 增加多级缓存
- 内存缓存(实际使用,需要高效)
- 文件缓存(兜底、降级方案)
- 每次更新配置文件,则更新内存,异步写入文件中
# 3.总结
- 配置存储是分级的,有公共配置,有个性的配置,一般个性配置会覆盖公共配置,这样可以减少存储配置项的数量\
- 配置中心可以提供配置变更通知的功能,可以实现配置的热更新\
- 置中心关注的性能指标中,可用性的优先级是高于性能的\
- 演进过程
- 项目中的配置文件
- 服务器维度的配置文件
- 配置文件管理中心
\
