数据结构
const data = [{
name: 'a',
children: [
{
name: 'a1',
children: [
{ name: 'a11' },
{ name: 'a12' },
]
},
{ name: 'a2' },
{ name: 'a3' },
],
},
{
name: 'b',
children: [
{ name: 'b1' },
{ name: 'b2' },
{ name: 'b3' }
],
}
]
图形化数据
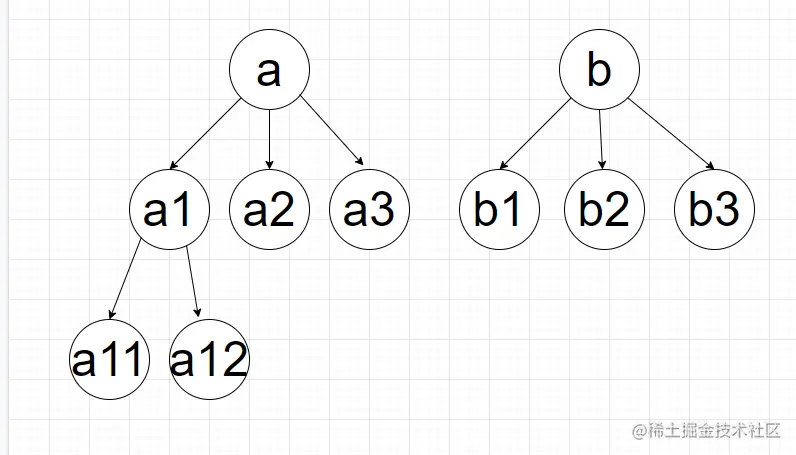
1、深度优先搜索 - depthFirstSearch
查找顺序

代码
const data = [...]
function depthFirstSearch(data, res = []) {
data.forEach(i=>{
res.push(i.name)
if(i.hasOwnProperty('children')){
depthFirstSearch(i.children, res)
}
})
return res
}
console.log('深度优先遍历顺序', depthFirstSearch(data))
2、广度优先搜索 - breadthFirstSearch
查找顺序
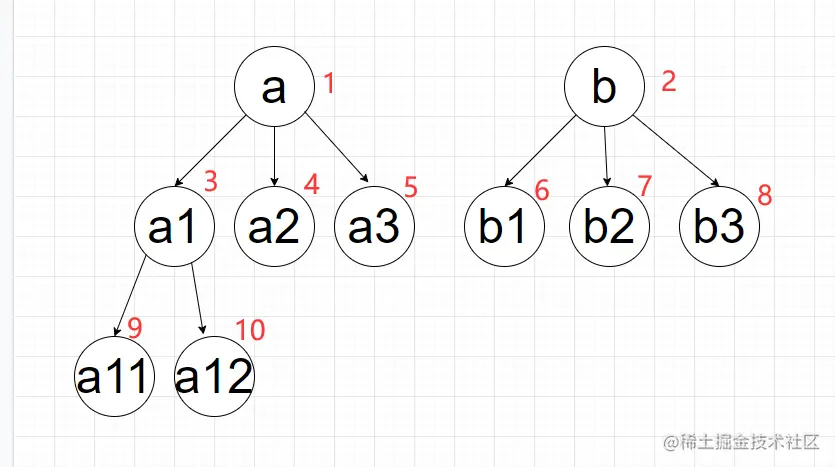
代码
function breadthFirstSearch(data) {
let queue = []
let res = []
queue = JSON.parse(JSON.stringify(data))
while (queue.length > 0) {
let item = queue.shift()
res.push(item.name)
if (item.hasOwnProperty('children')) {
queue.push(...item.children)
}
}
return res
}
console.log('广度优先',breadthFirstSearch(data))
代码解析
- 第一次,
队列 = [a, b]
- 第二次,把
a放入结果集, 结果集 = [a], 队列 = [b], 发现a有子节点, 存入队列, 队列 = [b, a1, a2, a3]
- 第三次,把
b放入结果集, 结果集 = [a, b], 队列 = [a1, a2, a3], 发现b有子节点,存入队列, 队列 = [a1, a2, a3, b1, b2,b3]
- 以此类推。。 我们发现是先进先出的,所以是队列。
使用场景
- 如果树很深,使用广度优先搜索。
- 如果树很宽,使用深度优先搜索。


