16 学习自动机和语言
本章介绍了学习语言的问题。
是自形式语言理论和计算机科学的早期以来探索的一个经典问题,有非常大的文献处理相关的数学问题。在本章中,我们将对这个问题进行简要的介绍,并特别关注有限自动机的学习问题,而有限自动机本身已经被成千上万的技术论文以多种形式研究过。我们将研究学习自动机的两大框架,并分别给出算法。特别地,我们描述了一种用于学习自动机的算法,其中学习者可以访问几种类型的查询,我们讨论了一种用于识别自动机族中的一个子类的算法极限。
16.1 介绍
语言学习是语言学和计算机科学中最早讨论的问题之一。它是由人类学习自然语言的非凡能力推动的。人类在很小的时候就能说出结构良好的新句子,尽管他们接触的句子数量有限。而且,即使在很小的时候,他们就能对新句子的语法性做出准确的判断。
在计算机科学中,学习语言的问题与学习生成语言的计算设备的表示方式直接相关。或者学习上下文无关的语言或上下文无关的语法就相当于学习下推式自动机。
有几个原因专门研究有限自主学习的问题。自动机在各种不同的领域提供自然建模表示,包括系统、网络、图像处理、文本和语音
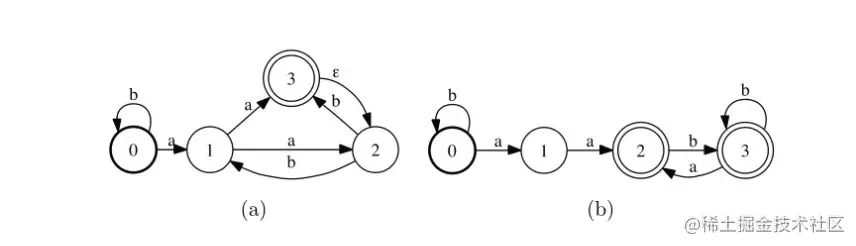
图16.1
(a) A 有限自动机的图形表示。(b)等效(最小)确定性自动机。
处理,逻辑和许多其他的。对于更复杂的设备,自动机也可以作为简单或有效的近似。例如,在自然语言处理中,它们可以用来近似上下文无关的语言。在可能的情况下,学习自动机通常是有效的,但正如我们将看到的,这个问题在许多自然情况下是困难的。因此,学习更复杂的设备或语言就更难了,
我们考虑了两种一般的学习框架:有效生成学习模型和极限识别模型。对于每一个模型,我们简要讨论了学习自动机的问题,并描述了一种算法。
本文首先简要回顾了自动机的基本定义和算法,然后讨论了自动机的有效精确学习问题和自动机的有效精确学习问题识别在极限。
我们将用Σ表示一个有限的字母表。x∈Σ∗在该字母表上的字符串长度用∣x∣表示。空字符串用ϵ,因此∣ϵ∣=0。对于任意string x=x1…xk∈Σ∗的长度k>0,我们通过x[j]=x1…xj其前缀长度 j<k 定义 x[0] 为 ϵ
有限自动机是具有初态和终态的有向图。下面给出这些设备的正式定义。
定义16.1 (有限自动机)
有限自动机A是一个5元组(Σ,Q,I,F,G),其中Σ为有限字母表,Q为有限状态集, I∈Q 为初始状态集,F∈Q 为最终状态集,以及 E∈Q×(Σ∪ϵ)×Q 为迁移集的有限集。图16.1a显示了一个有限自动机的简单示例。状态用圆圈表示。粗体圆表示初始状态,双圆表示最终状态。每个转换都是由一个箭头表示的,从原始状态到目标状态,其标签在 Σ∪ϵ 中。
从初始状态到最终状态的路径称为接受路径。如果一个自动机的所有状态都可以从初始状态访问,并允许一条通往最终状态的路径,那么这个自动机就被称为修剪。如果它的所有状态都在一个可接受的路径上
字符串x∈Σ*被机器人接受,一个当且仅当x标记接受路径。为了方便起见,我们会说,当x∈Σ∗不被A拒绝时,它会被A拒绝。A接受的所有字符串的集合定义了L(A)所表示的接受的语言。有限自动机接受的一类语言与正则语言家族相同,也就是说,可以用正则表达式来描述的语言。任何有限自动机都允许一个没有电子转换的等价自动机,也就是说,没有一个用空字符串标记的转换:存在一个通用的电子移除算法,它接受一个自动机作为输入,返回一个没有电子转换的等价自动机。
一个没有电子跃迁的自动机,如果它有一个唯一的初始状态,并且没有两个共享同一个标号的跃迁留下任何给定的状态,那么它就是确定性的。
确定性有限自动机通常用缩写DFA指代,而任意自动机则用缩写NFA指代,即非确定性有限自动机。任何NFA都允许一个等价的DFA:存在一个通用的(指数时间)确定算法,它接受一个没有电子转换的NFA作为输入,并返回一个等价的DFA。因此,dfa所接受的语言类别与ffa所接受的语言类别是一致的,即常规语言。
对于任何字符串X∈Σ*和DFA A,我们用A(x)表示从它唯一的初始状态读取时x达到A的状态。
如果DFA不允许具有更少状态数的等效确定性自动机,则称它是最小的。存在一种通用的最小化算法,以确定性自动机作为输入,返回运行在O(∣E∣log ∣Q∣)中的最小自动机。当输入DFA是无循环的,即当它不允许有路径形成一个循环时,它可以在线性时间O(∣E∣log ∣Q∣)中最小化。图16.1b显示了与图16.1a的NFA等效的最小DFA。
16.3 有效率的学习
在有效的精确学习框架中,问题包括从一组有限的例子中识别一个目标概念ϱ,在概念表示的大小和例子表示的大小的上界的时间多项式。与PAC-学习框架不同,在该模型中,没有随机假设,没有假设实例是根据某种未知分布绘制的。此外,目标是确定目标概念,准确地说,没有任何近似。如果存在有效精确学习任意c∈ϱ的算法,则称概念类C是有效精确可学习的。
我们将在有效准确学习的框架内考虑两种不同的情景:被动学习情景和主动学习情景。被动学习场景类似于前几章讨论的标准监督学习场景,但没有任何随机假设:学习算法像PAC模型一样被动地接收数据实例,并返回一个假设,但在这里,实例并不假设来自任何分布。在主动学习场景中,学习者通过使用我们将描述的各种类型的查询来主动参与训练样本的选择。在这两种情况下,我们将更具体地关注学习自动机的问题。
16.3.1 被动学习
在这种情况下学习有限自动机的问题被称为最小一致DFA学习问题。它可以表示为:学习者接收到有限样本S=((x1,y1), .., (xm, ym));对于任意xi∈Σ∗和yi∈{-1,+1},如果yi=+1,则;是已接受的字符串,否则将被拒绝。
这个问题包括使用这个样本学习与S一致的最小DFA A,即状态数最小的自动机,它接受标号为+1的S字符串,拒绝标号为-1的S字符串。请注意,寻找与S一致的最小DFA可视为遵循奥卡姆剃刀原理。刚才描述的问题不同于das的标准最小化。
一个最小的DFA接受正标记S的字符串可能不会有最小数量的状态:一般来说,可能有状态更少的DFA接受这些字符串的超集,拒绝负标记的样本字符串。例如,在S= ((a, +1), (b,-1))的简单情况下,接受唯一正标记字符串a或唯一负标记字符串b的最小确定性自动机有两种状态。然而,接受语言a*的确定性自动机接受a,拒绝b,并且只有一个状态。
有限自动机的被动学习是一个计算困难的问题。下面的定理给出了这个问题的几个已知的否定结果。
定理16.2
找到与一组接受或拒绝的字符串相一致的最小确定性自动机的问题是np -完备的。硬度结果即使是多项式近似也是已知的,如下定理所述,
定理16.3
如果PNP。那么,多项式时间算法不能保证找到与一组接受或拒绝的字符串相一致的DFA,这些字符串的大小小于最小一致DFA的多项式函数,即使当字母表被减少到只有两个元素时。在各种密码假设下,有限自动机的被动学习也得到了其他强有力的负面结果。
这些消极的学习结果促使我们考虑有限自动机的替代学习场景。下一节将描述一个场景,在该场景中,学习者可以使用各种类型的查询积极参与数据选择过程,从而获得更积极的结果。
16.3.2 通过查询学习
带查询的学习模式对应于(最小)教师或oracle和主动学习者的学习模式。在这个模型中,学习者可以提出以下两种类型的查询,oracle会回应这两种查询:
成员关系查询: 学习者请求实例a的目标标签f(x)∈ {-1,+1}并接收该标签。
等价查询: 学习者假设请求 h;如果 h= f,它会收到响应yes,否则就是反例。
我们会说,当一个概念类ϱ在这个模型中是有效地准确地学习时,它是有效地准确地学习成员和等价查询。这个模型是不现实的,因为在实践中通常没有这样的oracle。然而,它提供了一个自然的框架,正如我们将看到的那样,这将导致积极的结果。还要注意,要使这个模型具有意义,等价性必须是可计算的。对于一些概念类,例如无冲突语法,则不是这样,因为等价问题是不可确定的。事实上,等价性必须进一步有效地进行测试,否则在合理的时间内无法提供对学习者的响应。这种查询学习模型中的高效精确学习意味着PAC学习的以下变体:如果概念类ϱ可以通过访问多项式数量的成员查询的算法进行PAC学习,我们将说它可以通过成员查询进行PAC学习。
定理16.4
设是一个概念类ϱ,可以通过成员和等价查询有效地学习,那么ϱ是PAC-可学习的成员查询。
Proot:让A是一个使用成员和等价查询高效准确地学习ϱ的算法。修正ϱ > 0。我们用 A来代替学习
对于人类oracle,在某些情况下,当查询接近类边界时,回答成员查询也可能变得非常困难。这也使得模型难以采用在实践中。
目标 c∈ϱ ,每个等价性查询通过测试当前假设的多项式数标记的例子。设 D为点的分布。为了模拟第t个等价查询,我们绘制mt=ϵ1(log δ1 + tlog 2)点ii.d。如果ht与所有这些点都一致,则算法停止并返回ht。否则,其中一个点不属于ht,这提供了一个反例。
因为 A准确地学习了c,所以它最多进行 T次等价查询。其中 T是一个多项式,是目标概念的表示大小和一个例子的表示大小的上界。因此,如果没有等价查询,则仿真会积极响应。算法将在 T等价查询后终止,并返回正确的概念c。否则,算法将在第一个等价查询得到仿真的积极响应时停止。只有当停止算法的等价查询没有得到正确的响应时,它返回的假设不是ϵ近似。由于对于任何固定tE [ T],P[ R(ht) >ϵ]⩽ (1−ϵ)emt,对于t∈[ T],[ R(ht)] >ϵ可以被限定为:
P[∃ t∈[ R]:[ R(ht)>ϵ]⩽t=1∑ TP[ R(ht)>ϵ]
⩽t=1∑ T(1−ϵ)emt⩽t=1∑ T−emtϵ⩽t=1∑ T2nδ⩽t=1∑+∞2nδ=δ
因此,在概率至少为1−δ的情况下,算法返回的假设是一个ϵ近似值。最后,绘制的最大点数为∑t=1 Tmt=ϵ1( T(log δ1+2 T( T+1)),是在多项式in 1/ϵ, 1/δ,和 T。由于 A的其余计算成本也假定是多项式,这证明了ℓ属于PAC-学习
16.3.3 使用查询自动机学习
\
在本节中,我们描述了一种具有成员资格和等价查询的DFA的有效精确学习算法。我们用 A表示目标DFA,用 A表示算法的当前假设DFA。用于讨论算法。在不失一般性的前提下,我们假定 A是一个最小的DFA。
该算法使用两组字符串。 U和 V, U是一组访问字符串:从a的初始状态读取一个访问字符串 u∈ U将导致状态 A(u)。该算法确保状态 A(u), u∈ U都是不同的。为此,它使用一组可区分的字符串 V。由于 A是最小值,对于两个不同的状态 q和 A中的 q',必须存在至少一条弦, q从而不是从 q'导致最终状态。反之亦然。这个字符串帮助区分 q和 q'。字符串V的集合如下
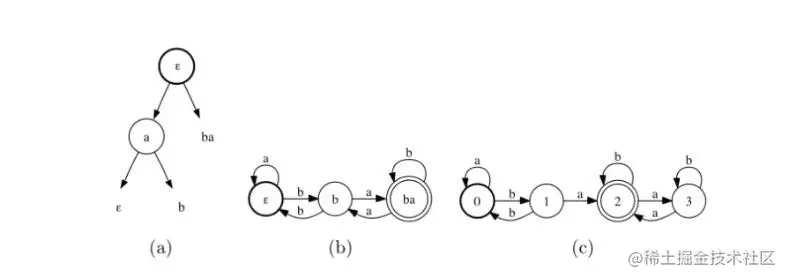 图16.2( a)分类树 T, U={ϵ, u, ba}和 V= { e, a}。
图16.2( a)分类树 T, U={ϵ, u, ba}和 V= { e, a}。
( b)使用 T构造的当前自动机A^。
( c)目标自动机 A
帮助区分 U中的任意一对访问字符串∑∗。
它们实际上定义了所有字符串的分区该算法的目标是在每次迭代时找到一个新的与之前所有的访问字符串不同的访问字符串∑∗,最终得到等于状态数4的访问字符串数量。它可以识别每个州(u)的访问字符串u。找到目的地的状态转换贴上E2离开状态u,它可以确定,使用分区由V访问字符串”,属于同一等价类ua。每个状态的最终结果可以用类似的方法确定。
这两个集合和变量都由算法通过一个类似于第9章所述的二进制决策树 T来维护。图16.2( a)显示了一个示例。 T定义由区分字符串 U引起的所有字符串的分区。每片叶子上都有一个明显的标记 u∈ U及其内部节点与 v∈ V.由 v∈ V定义的决策树问题, 给定一个 x∈Σ∗, 是指 A是否接受 xv,这是通过成员资格查询确定的。如果接受, x将分配给右子树,否则分配给左子树,并递归地应用于子树,直到到达叶子。我们用通过 T( x)表示到达的叶子的标签。例如,对于图16.2( a)的树梢和图16.2( c)的目标自动机 A。 T( abb)= b, abb不被 A(根本问题)和 abbb(节点问题)接受。在初始化步骤中,该算法确保根节点标记为ϵ,这便于检查字符串的终结性。
假设DFA A可以由 T构造如下。我们用 CONSTRUCTAUTOMATON()表示相应的函数。为每个叶子 u∈ U创建一个不同的状态A^(u)。状态A^(u)的终结是根据 u所属的根节点的子树来确定的:如果所属 u,则A^(u)成为最终状态
QUERY LEARN AUTOMATA()
1 t← MEMBERSHIP QUERY(ϵ)
2 T← T0
3 A^← A0
4 while( EQUIVALENCE QUERY(A^)=TRUE) do
5 x←COUNTER EXAMPLE()
6 if(T= T0) then
7 T← T1⊳(NEL replaced with x)
8 else j← argmink A( x[ k])≡ TA^( x[ k])
9 SPLIT(A^( x[ j−1]))
10 A^← CONSTRUCT AUTOMATON( T)
11 returnA^
图16.3
具有隶属度和等价查询的自动机学习算法。 A0是一个单状态自动机,其自循环全部标记为 a∈∑。这个状态是初始状态。它是最后随着ϵ的iff t= TRUE。 T0是一棵根节点标记为ϵ和两个叶子的树在右边的叶子是iff u=ϵ u。一个是ϵ,另一个是NIL。右边的叶子有ϵ标签iff t= TRUE. T1是 T0中 x代替NIL得到的树。转换的终点用 a∈∑标记离开状态A^( u)是状态A^( v),其中 v= T( ua)。图16.2 b显示了根据图16.2 a的决策树构造的 DFA A^。为了方便,对于任何 x∈∑∗,我们用 U(A^( x))表示标识的访问字符串状态A^( x)
图16.3给出了算法的伪代码。第1-3行初始化步骤构造了一个树 T,其中一个内部节点标记为ϵ,一个叶串标记为ϵ,另一个叶串未确定,标记为 NIL。他们还定义了一个试验性的 DFA A^,其中有一个用字母表的所有元素标记的自循环状态。这个状态就是初始状态。只有当ϵ被目标 DFA A接受时,它才会成为最终状态。目标 DFA A是通过第1行成员关系查询确定的。
在第4-11行循环的每次迭代中,都会使用一个等价查询。如果 A^不等于 A,则接收反例字符串 x(第5行)。如果 T是在初始化步骤中构造的树,则标记为 NIL的叶子被替换为 x(第6-7行)。否则,由于 x是反例,
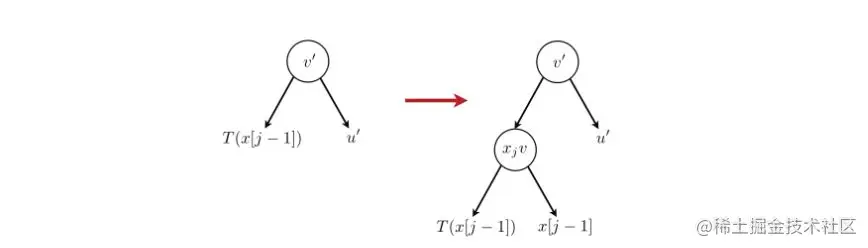 图16.4
图16.4
拆分程序的说明 SPLIT(A^( x[ j−1]))
则表示 A( x)和A^( x)有不同的结局;因此,定义一个字符串 A( x)和访问字符串 U(A^( x))被分配到不同的等价类 T .因此,存在一个最小的 j, 以致A^( x[ j])和 A( x[ k])并不相同,也就是说,这样前缀 x[ j]对于 x交流和访问字符串 U(A^( x[ j]))分配给不同的叶子通过 T. j可能为0自初始化确保A^(ϵ)是一种初始状态,初始状态相同的结尾 A(ϵ)的 A.等价 A( x[ j])和A^( x[ j])是测试通过检查 T的平等 T( x[ j])和 T( U(A^( x[ j])))既决定使用树 T和会员查询(第8行)。
现在,根据定义,( A( x[ j−1]))和(A^( x[ j−1]))是等价的,即 T将 x[ j−1]赋给以 U(A^( x[ j−1]))标记的叶子。但是,必须区分 x[ j−1]和 U(A^( x[ j−1])),因为(A^( x[ j−1]))和( A( x[ j−1]))用同一标签 x j允许转换为两个非等效态。设 v是A^( x[ j])和 A( x[ j])的区别字符串。 v是 x[ j]和(A^( x[ j]))标记叶的最小共同祖先。为了区分 x[ j−1])和 U(A^( x[ j−1])),只需将 T标记的( T( x[ j−1]))(叶片分裂,创建一个内部节点 x j u支配一个标记为 x[ j−1]的叶片和另一个标记为( T( x[ j−1]))的叶片(第9行)。图16.4说明了这种结构。因此,这提供了一个新的访问字符串 x[ j−1],通过构造,它区别于 U(A^( x[ j−1]))和所有其他访问字符串
因此,访问字符串的数量(或 A的状态)在循环的每次迭代中增加一个。当它达到 A的状态数时, A的所有状态都是 A(u)对于一个不同的 u∈ U, A和A^有相同数量的状态,实际上 A=A^。的确,设( A(u),a, A(u′))是 A的一个过渡,那么根据定义,等式 A( ua)= A(u′)成立。树T根据它们在a中的区别定义了所有字符串的划分,因为在 A中,当 A、 ua、和 u导致相同的状态,它们被 T分配到同一个叶子上,也就是说,叶子标记为u′。由 CONSTRUCT AUTOMATON()通过确定分配给 ua的 T中的叶子,即u′,来找到标号为 A的 A(u)转换的目的地。因此,通过构造,在 A′中创建了相同的转换 A( u), a,A^( u′)。
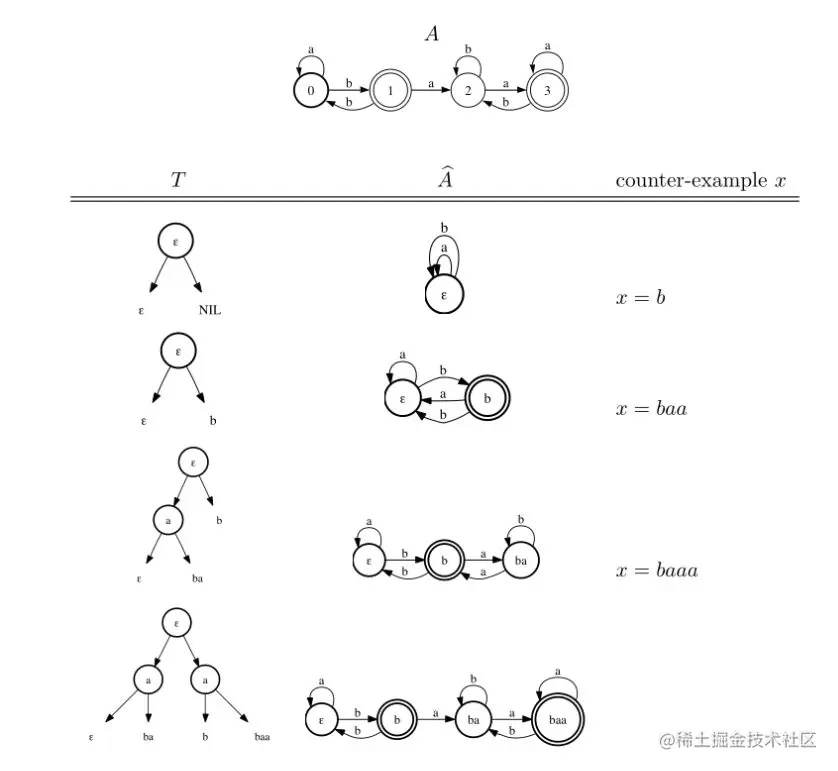
图16.5
算法 QUERY LEARN AUTOMATA()对目标自动机 A的执行说明。
每一行显示当前的决策树 T和使用 T构造的暂定 DFA A^。当A^不等于 A时,学习者会收到第三列所示的反例。同时, A的状态 A( u)是 A接受的最终状态,即 T将 u分配给根节点的右子树,这是决定A^( u)最终状态的判据。因此,自动机A^和 A重合。
下面对算法的运行时间复杂度进行分析。在每次迭代中,会发现一个新的区别访问字符串与 A的不同状态相关联,因此,最多创建∣ A∣状态。对于每个反例 x,最多执行∣ x∣树操作。建造A^需要 O(∣∑∣∣ A∣)树操作。树操作的成本是 O(∣ A∣),因为它最多由∣ A∣组成会员查询。因此,算法的总体复杂度是 O(∣∑∣∣ A∣2)+ n∥ A∣,其中 n是反例的最大长度。注意,此分析假设等价性和成员关系查询在常量时间内进行。
我们的分析显示了以下结果。
定理16.5 (通过查询学习 DFA)
使用成员资格和等价查询, DFAs所有的类都可以有效地准确地学习。图16.5说明了在特定情况下算法的完全执行。在下一节中,我们将研究自动机的不同学习场景。
16.4 极限识别
在极限框架中的识别中,问题包括在收到有限的示例集后准确地识别目标概念。如果有一种算法在检查了有限数量的示例后识别该 L类语言中的任何语言,并且该算法的假设此后保持不变,则称该类语言为可识别语言。
从计算的角度来看,这个框架可能不太现实,因为它不需要实例数量或算法效率的上限。然而,有人认为这与人类学习语言的情景相似。在这个框架中,消极的结果也适用于学习 DFA的一般问题。
定理16.6 确定性自动机在实证的限制下是不可识别的。
然而,有限自动机的某些子类可以在极限条件下成功识别。大多数自动机推理算法都是基于状态划分范式的。它们从一个初始的 DFA开始,通常是一个树,它接受有限的可用样本字符串集和平凡的分区:每个块被简化为树的一个状态。在每次迭代中,它们合并分区块,同时保留一些同余属性。当没有其他合并是可能的,并且最终分区定义了推断的自动机时,迭代结束。因此,同余的选择完全决定了算法,通过改变选择可以定义各种不同的算法。从接受∑∗的单状态自动机开始,可以类似地定义状态分裂范式∗. 在本节中,我们将介绍一种学习可逆自动机的算法,这是刚刚描述的一般状态划分算法范式的一个特殊实例。
让 A=(∑, Q, I, F, E)成为一个 DFA和让π是 Q的一个划分. 由分区π定义的 DFA称为与π的自动商。它由π A且定义如下:π A=(∑,π, Lπ, Fπ, Eπ)和:
Iπ=[( B∈π: I∩ B=∅)]
Fπ=[( B∈π: F∩ B=∅)]
Eπ=[( B, a, B′):∃( q, a, q′)∈ E∣ q∈ B, q′∈ B′, B∈π, B′∈π]
设 S为一组有限的字符串,设优先(S)表示所有字符串的前缀集。pref树自动机精确地接受一组字符串 S一个特定的 DFA,由 PT(S)=(∑,pref (S),ϵ, S, E S)表示,其中∑是使用的一组字母符号,定义如下:
S, E S=( x, a, xa): x∈.pref (S), xa∈.pref (S)
图16.7显示了一组特定字符串的前缀树自动机。
16.4.1 学习可逆自动机
在本节中,我们展示了可恢复自动机或可恢复语言的子类可以在极限内识别。特别是我们表明语言可以识别出一个积极的在本节中,我们展示了可恢复自动机或可恢复语言的子类可以在极限内识别。特别是,我们表明,语言可以识别出一个积极的介绍。
语言的正表示形式是无限序列( xn)n确保{ xn: n∈N}= L。因此,特别是对于任一 x∈ L存在 n∈N确定 x= xn。如果存在,则算法可从正表示中识别极限 N∈N那是什么意思 n≥ N假设它返回为 L。
给定一个 DFA A,我们将其反向 A R定义为通过使初始状态 A为最终状态,最终状态为初始状态,并反转每个转换的方向,从 A派生出的自动机。反向接受的语言正是 A接受的字符串的反向(或镜像)语言。
定义16.7 (可逆的自动机)
如果 A和 A R都是确定性的,则称有限自动机 A为不可逆的。如果语言 L是某种可逆自动机所接受的语言,则称其为不可逆语言。
这个定义的一些直接后果是可逆自动机 A有一个唯一的终态,其逆 A R也是可逆的。还要注意,修剪可逆自动机 A是最小的。事实上,如果 A中的状态 q和 q′是等价的,那么它们允许一个从 q和 q′到最终状态的公共字符串 x。但是,根据 A的反向决定论,从最终状态读取 x的反向必须导致唯一状态,这意味着 q= q′。
对于任何 u∈∑∗ 任何语言都可以 L⊆∑∗, 让 SuffL( u)表示 L中所有可能后缀的集合,表示 u:
SuffL( u)=[ v∈∑∗: uv∈ L]
SuffL( u)通常也用 u−1 L表示.注意,如果 L是可逆语言,则以下含义适用于任意两个字符串 u,u′∈∑∗:
SuffL( u)∩ SuffL( u′)=∅⟹ SuffL( u)= SuffL( u′)
事实上,设 A是一个接受 L的可逆自动机。设 q是 A在读取时从初始状态到达的状态, q′是读取 u时到达的状态。如果 v∈ SuffL(u)∩ SuffL( u′),则可以从 q和 q′读取 v以达到最终状态。由于 A R是确定性的,从最终状态读回 v的倒数必须导致唯一状态,因此 q= q′,即 SuffL( u)= SuffL( u′)。
让 A=(∑, Q,( i0),( f0), E))是接受可逆语言 L的可逆自动机。我们定义一组字符串 S L如下:
S L={ d[ q] f[ q]: q∈ Q}∪{ d[ q], a, f[ q′]: q, q′∈ Q, a∈∑}
其中 d[ q]是从 i0到 q的最小长度的字符串, f[ q]是从 q到 f0的最小长度的字符串。如下面的命题所示, SL描述了语言 L的特征,即任何包含 SL的可逆语言都必须包含 L。
提议16.8 让我们用一种可逆的语言。那么, L是包含 SL的最小可逆语言。
证明:设 L′为包含 SL的可逆语言,设 x= x1⋅⋅ x n为 L接受的字符串,带 x k∈ k的∑∈[ n]和mathcal n≥1.为了方便起见,我们还将 x0定义为ϵ。设( q0, x1, q1)⋅⋅⋅( q( n−1), x n, q n)是 A中标记有 x的接受路径。我们通过递归证明,对于所有 k, SuffL′( x0⋅⋅⋅ x n)= SuffL′( d[ q k]对于所有 k∈{0,⋅⋅⋅, n}。由于 d[ q0]= d[ i0]=ϵ,,这显然适用于 k=0。现在假设某些 k∈{0,⋅⋅⋅, n−1}的 SuffL′( k0= SuffL0(d[qk]). 这立即意味着 SuffL′( x0,⋅⋅⋅, x k x k+1)=SuffL0(d[qk]xk1)= SuffL′( d[ q k+1])。根据定义, S L同时包含 d[ q k+1] f[ q k+1]和 d[ x k+1] f[ q k+1]。由于 L′包括 S L,因此 L′也同样适用。因此, f[ qk+1]属于 SuffL′( d[ q k+1])∩ SuffL′( d[ qk] x k+1)。鉴于( 16.2),这意味着 SuffL′( d[ qk] x k+1)= SuffL′( d[ q k+1])。因此,我们有 SuffL′( x0,⋅⋅⋅, x k x k+1)= SuffL′( d[ q k+1])。这表明 SuffL′( x0,⋅⋅⋅, x k)= SuffL′( d[ qk])适用于所有 k∈{0,⋅⋅⋅, n},特别是对于 k= n。注意,由于 qn= fn,我们有 f[ qn]=ϵ,因此 d[ qn]= d[ qn] f[ qn]在 SL⊆ L′,这意味着 SuffL′( d[ qn])被包含。因此 SuffL′( x0⋅⋅⋅ x n)包含ϵ。这相当于 x= n0⋅⋅⋅ xn∈ L′。
图16.6显示了一个算法的伪代码,该算法用于从 m个字符串 x1,⋅⋅⋅, x m的样本 S推断可逆自动机 A。该算法首先为 S(第1行)创建前缀树自动机 a,然后迭代地定义 A状态的分区π,从每个状态一个块的平凡分区π0开始(第2行)。返回的自动机是 A和定义的最终分区π的商。
LEARN REVERSIBLE AUMATALEA( S=( x1,⋅⋅⋅, x m))
1 A=(Σ,Q,{ i0}, F, E)← PT(S)
2 π←π0⊳琐碎的划分
3 LIST←{( f, f′): f′∈ F}
4 然而 LIST=∅ do
5 REOVE( LIST,( q1, q2)
6 if B( q1,π)= B( q2,π) then
7 B1← B( q1,π)
8 B2← B( q2,π)
9 对于所有 a∈Σ do
10 如果( succ( B1, a)=∅)⋀( succ( B2, a)=∅) then
11 ADD( LIST,( succ( B1, a),( succ( B2, a)))
12 如果( pred( B1, a)=∅)⋀( pred( B2, a)=∅) then
13 ADD( LIST,(pred( B1, a),( pred( B2, a)))
14 UPDATE( succ, pred, B1, B2)
15 π← MERGE(π, B1, B2)
16 returnπ A
图16.6
从一组正字符串 S学习可逆自动机的算法。
该算法维护一个状态对列表,其中对应的块将被合并,从任意选择的最终状态 f的所有最终状态对( f, f′)开始 f∈ F(第3行)。我们用 B( q,π)表示基于划分π的包含 q的块。
对于每个块 B和字母符号 A∈Σ,该算法还保持后继成功( B, a),即通过从 B的状态读取 a可以达到的状态;成功( B, a)=∅如果不存在这种状态。它类似地维护前一个 pred( B, a),这是一个允许标记为 a的转换进入 B中的状态的状态; pred( B, a)如果不存在这种状态。
然后,当 LIST不为空时,将从 LIST中删除一对,并按如下方式处理。如果该对( q1, q1′)尚未合并,则将由 B1= B( q1,π)和B2=B(q2,π)的后继和前辈组成的对添加到 LIST中
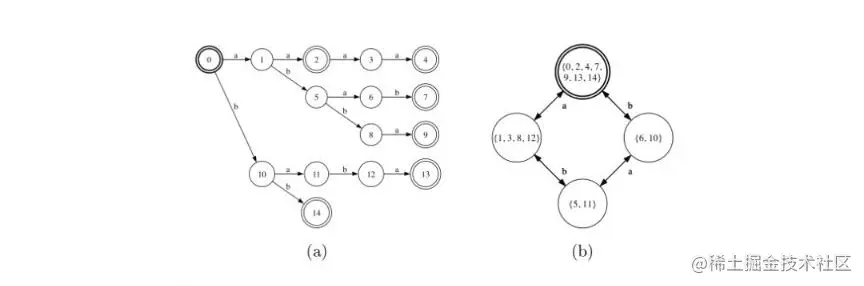 图16.7
图16.7
可逆自动机的推理示例。( a)表示 S=(ϵ, aa, bb, aaaa, abab, abba, baba)的前缀树PT(S)。(b) 由输入S的LEARNREVERSIBABLEAUTOMATA()返回的自动机A^。双向箭头表示具有相同标签且方向相反的两个过渡。A^所接受的语言是带有偶数个as和bs的字符串。
(第10-13行)在将块 B1和 B2合并为定义新分区π的新块 B′(第15行)之前,新块 B′的后续值和前置值定义如下(第14行)。对于每个符号的新块 a∈Σ,succ( B′, a)=∅,如果 succ( B1,a)= succ( B2, a)=∅, 否则,如果 succ( B′,a)为非空,则将其设置为 succ( B1,a)中的一个,否则设置为 succ( B2,a)。前置值的定义方式类似。图16。7说明了算法在 m=7字符串的示例中的应用。
提议16.9
设S是一组有限的字符串,设a=PT(S)是从S定义的前缀树自动机。然后,由LEARNREVERSIBLEAUTOMATA()定义的用于输入S的最终分区是πA可逆的最细分区π
证明
设T为输入样本S的算法迭代次数。我们用πt表示算法在T≥1之后定义的分区循环的迭代,πT为最终分区。
πTA是一个可逆自动机,因为所有最终状态都保证由于第3行的初始化步骤而合并到同一个块中,对于任何块B,根据算法的定义,A可达到的状态a∈Σ来自B的Σ包含在同一个块中,对于那些允许标记为a的过渡到B状态的情况也是如此。
设π′是a的状态的一个分区,其中π′A是可逆的。我们通过递推证明πT细化了π′。显然,平凡的划分π0细化了π′。假设πs精炼π′为所有s≤t由πt=1通过合并两个块B(q1,πt)和B(q2,πt)得到。由于πt细化了π′,我们必须有B(q1,πt)⊆B(q1,π′)。
定理16.10
设S是一组有限的字符串,设a是LEARNREVERSIBABLEAUTOMATA()在与输入S一起使用时返回的自动机。那么,L(a)是包含S的最小可逆语言。
证明
设L是包含S的可逆语言,设A′是L(A′=L的可逆自动机ϵ可以从A′的初始状态读取Pref(S),以达到A′的某些状态q(u)。考虑仅通过保持形式Q(u)的状态和这些状态之间的转换从A′导出的自动机A′′。A′′具有唯一的最终状态A′,因为q(u)是最终状态u∈S、,它的初始状态是A′,因为ϵ是S字符串的前缀。此外,A′′直接继承了A′的确定性和反向确定性。因此,A′′是可逆的。
A′′的状态定义了Pref(S)的分区:u,v∈Pref(S)当q(u)=q(v)时,Pref(S)在同一块中。由于根据前缀树\mathcal PT(S)的定义,其状态可以用\mathcal Pref(S)标识,因此A′′的状态也定义了pT(S)状态的分区π′,因此A′′=π′pT(S)。根据第16.9号提案。由算法LEARNREVERSIBABLEAUTOMATA()定义的分区π是最精细的,因此πPT(S)是可逆的。因此,我们必须有πL(PT(S)⊆π′L(PT(S)=L(A′′)。由于A′′是A′的子自动机,L包含\mathcal L(\mathcal A^{''}),因此πPT(S)=L(a),从而得出结论。
定理16.11(可逆语言极限下的识别)假设L是一种可逆语言,那么算法LEARNREVERSIBABLEAUTOMATA()将L从一个正表示中识别出极限。
证明:让我们用一种可逆的语言。根据第16.8号提案。L允许有限特征样本SL。让(xn)n∈N表示L的正表示,让Xn表示序列中第一个元素的并集。因为是有限的,所以存在N≥1这样的话SL⊆XN。根据定理16.10,对于任何n≥N,在有限样本上运行的LEARNREVERSIBABLEAUTOMATA()返回包含xn更进一步到SL的最小可能语言L′,根据SL的定义,这意味着L′=L
实现学习可逆自动机算法所需的主要操作是标准的查找和合并,以确定状态所属的块,并将两个块合并为一个块。对于这些操作,使用不相交的集合数据结构,算法的时间复杂度可以显示为O(nα(n)),其中n表示输入样本S中所有字符串的长度之和,α(n)表示阿克曼函数的倒数,这基本上是常数(α(n)≤4代表n≤1080).
16.5 章节注释
有关有限自动机和一些相关结果的概述,请参见Hopcroft和Ullman[1979]或Perrin[1990]最近的手册章节,以及M.Lothaire的系列书籍[Lothaire,1982,1990,2005]和De la Higuera[2010]最近的书籍。
定理16.2指出寻找最小一致DFA的问题是NP困难的,这是由于Gold[1978]。这一结果后来被Angluin[1978]扩展。Pitt和Warmuth[1993]进一步加强了这些结果,表明即使是最小自动机大小的多项式函数中的近似也是NP难的(定理16.3)。其硬度结果也适用于使用NFAs进行预测的情况。Kearns和Valiant[1994]根据密码假设给出了不同性质的结果。他们的结果表明,如果普遍接受的任何密码假设成立,则没有多项式时间算法可以从接受和拒绝字符串的有限样本中学习最小DFA大小的一致NFAs多项式:如果分解Blum整数是困难的;或者RSA公钥密码系统是否安全;或者如果确定二次剩余很难。最近,Chalermsook等人[2014]将Pitt和Warmuth[1993]的非近似保证提高到一个严格的界限。
在积极的一面,Trakhtenbrot和Barzdin[1973]表明,与输入数据一致的最小有限自动机可以从一个统一的完全样本中准确学习,其大小与自动机的大小成指数关系。他们算法的最坏情况复杂度是指数型的,但假设拓扑和标签是随机选择的[Trakhtenbrot和Barzdin,1973],甚至拓扑是逆向选择的[Freund等人,1993],则可以获得更好的平均情况复杂度。
Cortes、Kontorovich和Mohri[2007a]研究了在适当的高维特征空间中基于线性分离学习自动机的方法;另见Kontorovich等人[2006年、2008年]。字符串到该特征空间的映射可以使用第6章中介绍的有理核隐式定义,有理核本身通过加权自动机和传感器定义。
Angluin[1978]引入了查询学习模型,他还证明了有限自动机可以在最小自动机和最长反例大小的时间多项式中学习。Bergadano和Varrichio[1995]进一步将这一结果推广到任何领域上定义的学习加权自动机的问题(另见Bisht等人[2006]的优化算法)。使用域上最小加权自动机的大小与相应Hankel矩阵的秩之间的关系,可以显示许多其他概念类(如不相交DFA)的可学习性[Beimel et al.,2000]。我们对使用决策树的Angluin[1982]算法的有效实现的描述改编自Kearns和Vazirani[1994]。
Gold[1967]介绍并分析了自动机极限下的辨识模型。确定性有限自动机被证明在正面例子的极限下不可识别[Gold,1967]。但是,在一些子类的限制下,例如本章中考虑的可转换语言Angluin[1982]家族,对识别给出了积极的结果。积极的结果也适用于学习后续传感器Oncina等人[1993]。Ron等人[1995]也证明了一些有限类的概率自动机(如非循环概率自动机)是可有效学习的。
有大量的文献涉及学习自动机的问题。特别是,在使用查询进行学习的场景中,有限自动机的各种子族已显示出积极的结果,并且针对该问题介绍和分析了不同类型的学习场景。因此,本章中介绍的结果仅应视为对该材料的介绍。
16.6 练习
16.1 最小DFA。证明一个最小DFAA在所有其他DFA中也具有与a等价的最小转换数。证明一个语言L是正则的iff Q={SuffL(u)u∈Σ∗} 证明了L(a)=L的最小DFAA的状态数正是Q的基数。
16.2 二维的有限自动机。
(a) 所有有限自动机族的VC维数是多少?这对有限自动机的PAC学习意味着什么?如果我们局限于学习非循环自动机(没有循环的自动机),这个结果会改变吗?
(b) 结果表明,最多有(b)个态的\mathcal DFA族的\mathcal VC维数以O(∣Σ∣nlog n)为界。
16.3 会员查询的PAC学习。给出一个概念类C的示例,该概念类可以通过成员资格查询有效地进行PAC学习,但不能有效地准确地进行学习。
16.4 通过查询学习单调DNF公式。证明了n个变量上的单调DNF公式类可以通过成员关系和等价查询有效地精确学习。(提示:公式的素蕴涵t是一个文本的乘积,这样t意味着f,但t的适当子项并不意味着f。使用这样一个事实:对于单调DNF,素蕴涵的数量最多是公式的项数。)
16.5 使用不可靠的查询响应进行学习。考虑学习者必须在[n]内找到Oracle所选择的整数的问题。≥给出了1。为此,学员可以提出以下形式的问题(x≤m?)或(x>m?)形式m∈[n]。oracle会回答这些问题,但可能会对k个问题给出错误的回答。学习者应该问多少问题来确定x?(提示:请注意,学员可以将每个问题重复2k+1次,并使用多数票。)
16.6 学习可逆语言的算法。当应用于样本S={ab,aaabb,aabbb,aabbb}时,学习可逆语言的算法返回的DFAA是什么?假设我们向示例中添加一个新字符串,例如x=abab。应如何更新A以计算S∪{x}的算法结果?更一般地,描述一种增量更新算法结果的方法。
16.7 k可逆语言。一个有限自动机A′被称为k-确定的,如果它是一个前瞻k的确定模:如果两个不同的状态p和q都是初始状态,或者都是通过读取A从另一个状态r到达的a∈Σ,则在A′中不能从p和q读取长度为k的字符串u。如果有限自动机A是确定性的,如果AR是k-可逆的。语言L是k可逆的,如果它被某个k可逆自动机接受。
(a) 证明L是任意字符串u,u′,v∈Σ的k-可逆iff 当∣v∣=k时,
(b) 证明一个k-可逆语言允许一个特征语言。
(c) 显示以下定义了学习可逆自动机的算法。按照学习可逆自动机的算法进行,但使用以下合并规则:合并块B1和B2,如果它们可以由其他块中长度为k的相同字符串u到达,并且如果B1和B2都是最终的或有一个共同的后继对象。


