

小知识,大挑战!本文正在参与“ 程序员必备小知识 ”创作活动
本文同时参与 「掘力星计划」 ,赢取创作大礼包,挑战创作激励金
ijcai 2018,Deep Attributed Network Embedding
拓扑结构和属性网络时 non-linear的,因此获得非线性的表示对于非常 潜在的模式关系很重要。因此本文提出了一个DANE(Deep Attributed Network Embedding)。
1.首先用深度网络学习非线性特征,于此同时保持了一阶和高阶相似性。
2.最后在属性和结构上综合考虑了consistent和complementary.
定义:
一阶近似:


2个节点i和j之间的一阶相似性代表是否右边,即Eij=1。换句话说有边相连的节点更相似。
2个节点i和j之间的高阶相似性代表共同邻居的数目。通过定义知道这里的“邻居”可能是二跳的邻居也可能是多跳的邻居。
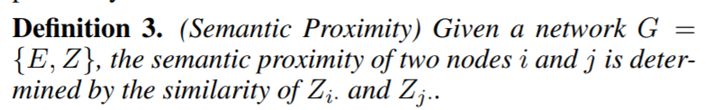
语义相似性表示如果两个节点具有相似的属性,那么这两个节点是相似的。 本文的动机 就是 针对最后的嵌入表示,使其具有一阶相似性,高阶相似性。
挑战:
1.非线性结构。
2.近似性保留:属性网络上的近似性 依赖于属性也依赖于结构。(这点应该算是挑战)。 3.consistent and complementary。 属性和结构的嵌入表示具有一致性(同一个节点),同时又互相补充特性。
模型:
模型架构如下。
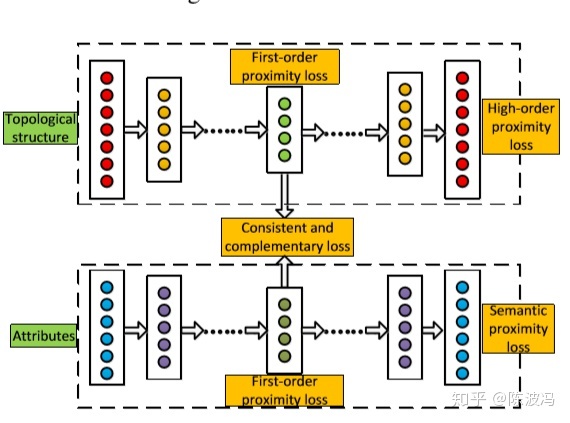
接下来分点介绍这篇文章是怎么解决 一阶近似,高阶近似,语义近似,信息的互补和一致性。
Highly Non-linear Structure 这块很好理解,就是用深度神经网络捕捉非线性结构,具体到论文里就是2个autoencoder。 Proximity Preservation
1.preserve semantic proximity
用重构损失保留语义信息。即针对属性的autoencoder去做重构损失。
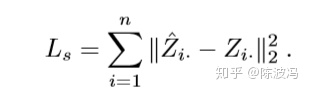
2. preserve high-order proximity
高阶近似性用了同样的方式。值得注意的是这里输入是M,不像大部分网络直接输入邻接矩阵A。 背后的动机:M是代表了高阶近似。如果2个节点的共同邻居越多,那么Mi和Mj就越像,那么学习学习到的隐层表示也有一样的特性。因此通过重构损失可以让Hi和Hj更相似。损失函数如下
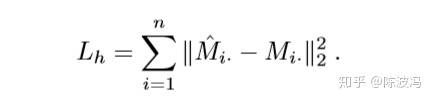
3. first-order proximity
一阶相似性的目的是为了保持一阶特性。(通常的论文关于结构的autoencoder实际输入的就是A,那么其实是利用了autoencoder)。 首先考虑结构上的一阶相似性。 最大化一阶近似就是最大化
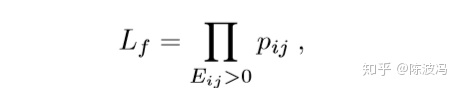
其中pij代表
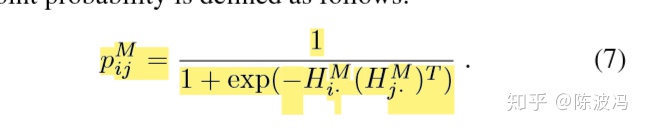
通俗解释就是,在初始的网络上,针对 一阶近似性矩阵M,如果两个节点i和j存在边,我们最大化pij的最大似然,同时观察pij的式子可以知道,越相似的节点pij越高。因此通过这种方式保留一阶近似性。 属性上的一阶相似性采用了类似的方法,Eij的选择利用了结构上的信息。
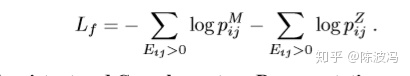
Consistent and Complementary Representation
这点很有趣:一个节点在结构上和属性上的表示是一个节点的表,应该具有一致性。其次,这两种信息描述了同一个节点不同方面的信息,也应该 互相提供补充信息。因此如何学习Consistent and Complementary Representation很重要。 一种方法是针对结构和属性上的隐向量做concate。利用了complementary但是没用consistent。 另一种方法是共用encoder网络,保持了consistent但是没有complementary。 作者的方法: 最大化似然:
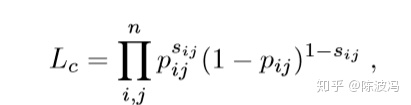
其中的概率pij的求法,利用了2个不同模态间的相似性。即最大化同一个节点在不同模态下的隐向量相似的可能性。
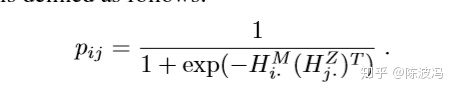
通过这种方式,目的是为了让同一个node在不同模态下的隐向量尽可能相似,从而具有consistent性。然后把2个向量拼接起来从而具有了complementary。 紧接着作者觉得
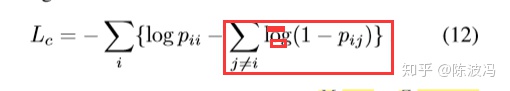
过于严格,从而不仅仅是同一个node节点具有consistent,让具有一阶相似性的节点也具有consistent。损失函数成了:
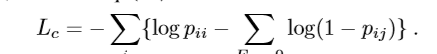
综上,最终的loss。

实验结果:分类,聚类,可视化。
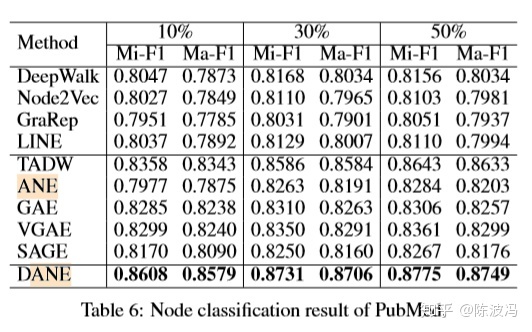
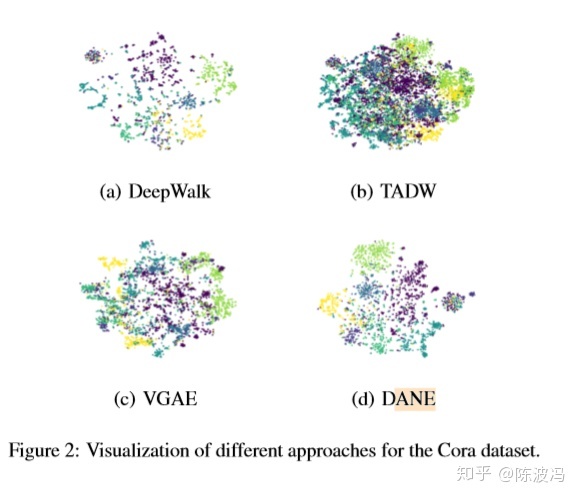
总结:
保留一阶近似和高阶近似。 consistent的方法。
Thanks for your reading~
参考文献:
【1】Gao H, Huang H. Deep Attributed Network Embedding[C]//IJCAI. 2018, 18: 3364-3370.
专注机器学习与风控算法前沿进展,分享数据挖掘比赛,机器学习,反作弊,推荐系统等技术文章。
快来关注我一起学习呀!

