

小知识,大挑战!本文正在参与“程序员必备小知识”创作活动。
前天收到一个需求要优化报表的一条慢SQL,因为系统的自定义报表只支持SQL不支持接口,这就很烦。只能去优化又长又臭的SQL.还有昨天又接到一个视图,美化后几百行的查询,能快就有了鬼了,查了十几张表真的是离谱,硬着头皮优化了这两个SQL让其性能得到了一些提升。
1.优化前和优化后的对比。
报表SQL,优化前:
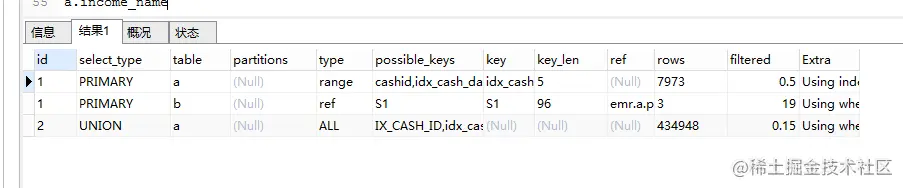 优化后:
优化后:

视图SQL,优化前:
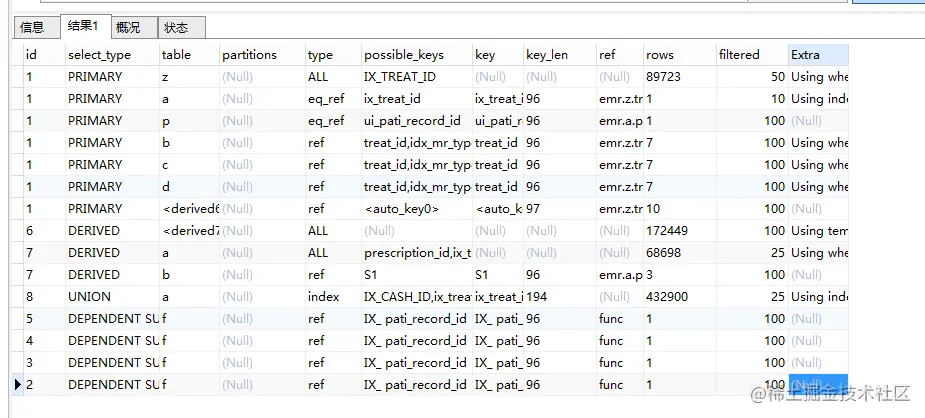 优化后:
优化后:
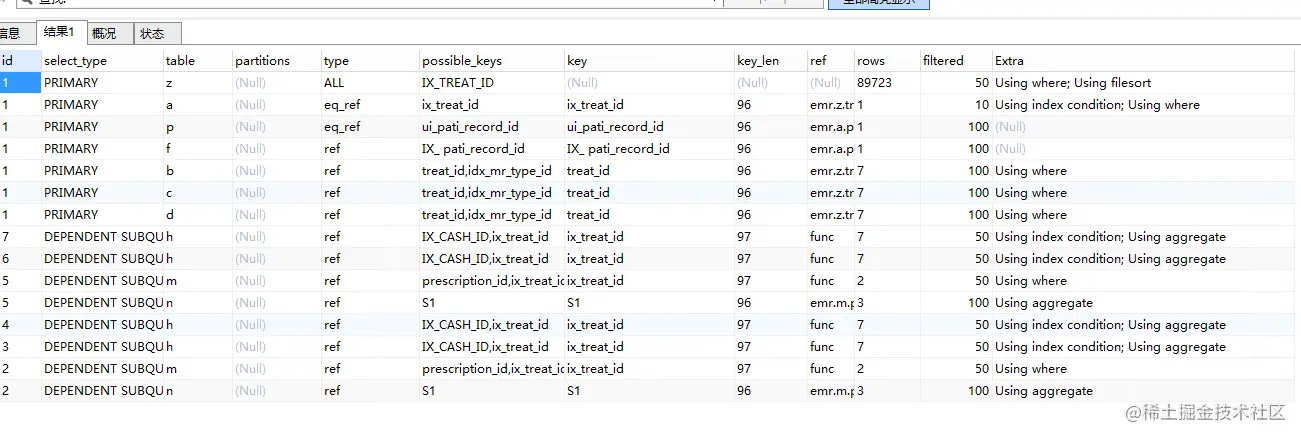
从这些SQL执行分析中可以明显看出,SQL性能得到了不小的提升,索引被更大化的利用,减少了大规模扫表,我们再看一下速度上的提升
报表SQL优化前17.522s
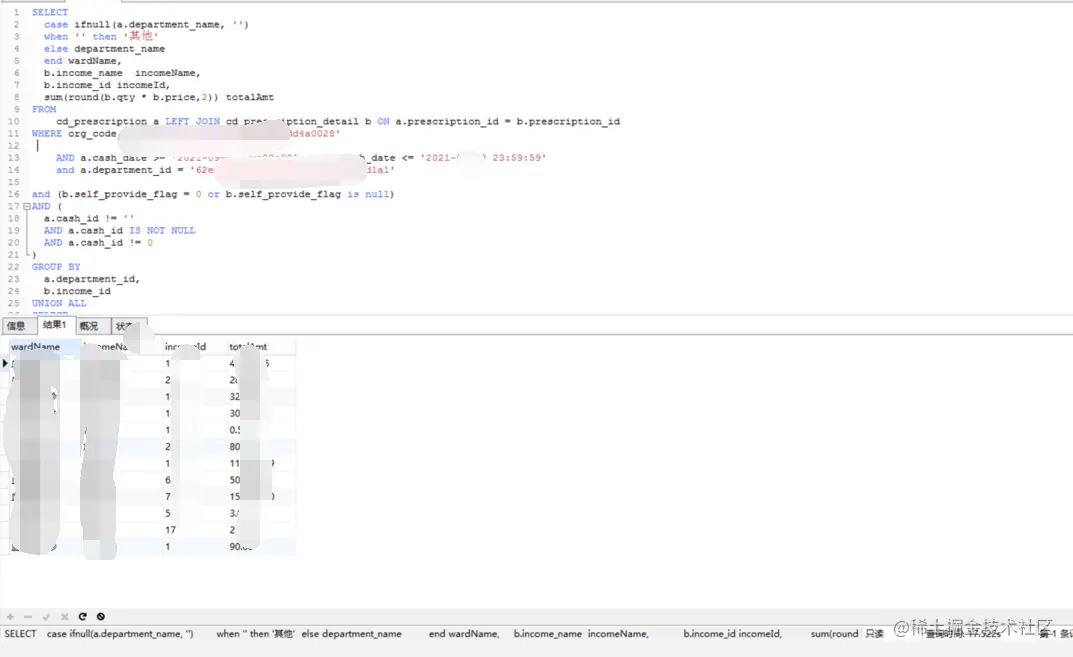 优化后0.303s
优化后0.303s
视图优化前28.936s
 优化后2.963s
优化后2.963s
2.分析改造过程
- 在报表的那个SQL中我分析出它的性能瓶颈在于查费用的时候,它的索引没用利用上,导致全表扫描,那个表的数据量超多直接40多万条数据,没用走索引。然后我就看他的查询条件,好多条件限制,然后又没法去掉这些条件,于是我决定用自增主键去查,我先通过日期查出自增主键,从而限制查询的数据量,然后再去加其他条件过滤,主键还是好使。
- 视图那个SQL太长了,整理就整理了好长时间,查了那么多表,首先我先将那些没用的子查询去掉,影响阅读,那个使用左连接效果一样的,没用必要去做子查询,然后有分析到他右连接了一个虚拟表,这个虚拟表还是用union all 连起来的,我仔细查出来之后还得分组,在聚合,搞的很复杂尽是些花拳绣腿,更本没用,还会导致索引失效,好巧不巧的又是上个报表的那个表,那个表的数据是真的多。然后我把这个东西在查询结果处做成子查询,直接用查询条件的一个id做查询条件,完美匹配索引,性能直接几何倍数提升。
3.总结
我认为SQL优化的重心就是分析SQL执行性能薄弱的那一块,如果都很薄弱,那要去看看是不是一个索引都没有建,就需要去加索引,如果关键字段上都加了索引,那么我们就需要将这些索引利用起来,不要让他们去全表扫描,一扫几十万条数据,那不可能快的,一查可能就得是分钟级的查询,我们想要将其调节为秒级的查询就要充分去利用索引,毕竟就像查字典一样,你通过目录检索和你去整本书翻阅效率上差的可不止一点半点。
