非常感谢中科大-郑烇老师的细心讲解,这边先粗略将老师讲授的内容做了一个记录,后面有时间进行详细的整理
名次解释:
RTT:(Round-Trip Time): 往返时延。在计算机网络中它是一个重要的性能指标,表示从发送端发送数据开始,到发送端收到来自接收端的确认(接收端收到数据后便立即发送确认),总共经历的时延。一般认为单向时延=传输时延t1+传播时延t2+排队时延t3
RTO:Retransmition Time Out 重传超时时间
SS:slow start 慢启动
CA:congestion avoid 冲突避免
FR:快速恢复
RACK:Recovery ACK
探知可用带宽的一种方式(阶梯式,波浪式):
反复拥塞降低窗口,带宽利用率不高。拥塞避免是探知网络可用带宽的一种方式。

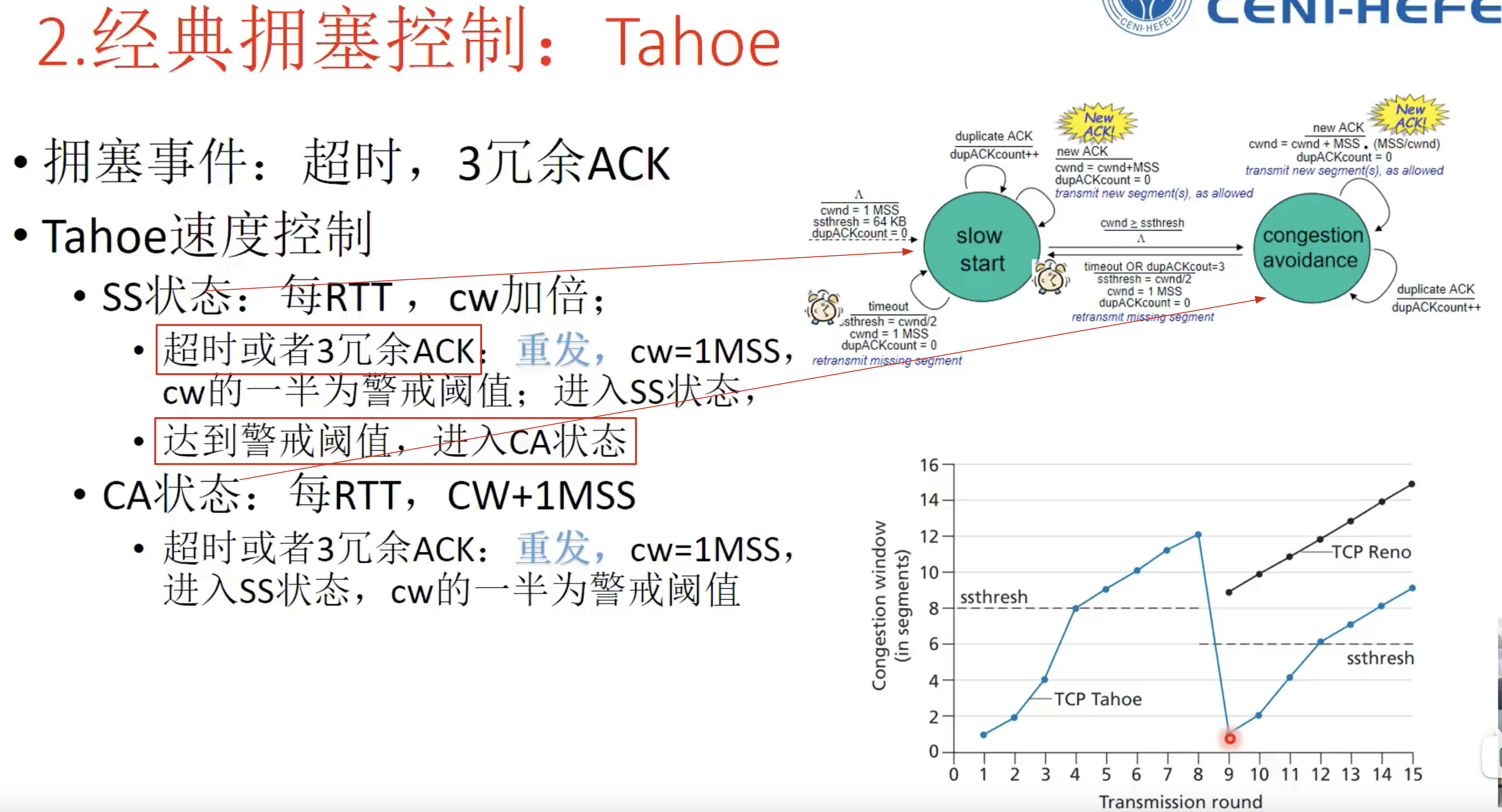
1. Tahoa
-
慢启动(指数增大)
-
拥塞避免(下一次指数增大超过阈值,从阈值开始加法增大)
- 出现三个冗余ACK(中间缺少某个ack,但是收到了后面三个ack)
- 出现超时重传
快速重传丢失数据包 并进入慢启动阶段
-
阈值减少到当前cw的一半,从1mss开始继续慢启动
注:Tahoa算法的问题是,三个冗余ack和超时重传的处理方式是一样的,但是出现三个冗余ACK并不代表网络出现很大的网络拥塞,网络还有一定的通信能力,因为还能收到冗余ack,直接从1mss开始慢启动,似乎惩罚过于严重。
所以Reno算法在此基础上进行了改进,引入了快速恢复阶段。
2. Reno
- 慢启动
- 拥塞避免
- 出现三个冗余ACK(中间缺少某个ack,但是收到了后面三个ack) ,进入快速恢复阶段
- 出现超时重传,进入慢启动状态
- 快速恢复阶段
- 快速恢复阶段,在ss和ca阶段出现三个冗余ack时都会进入
- 在快速恢复阶段出现了超时重传的情况,转换进入ss慢启动阶段
- 在快速恢复阶段收到了新的ack后,进入ca拥塞避免阶段
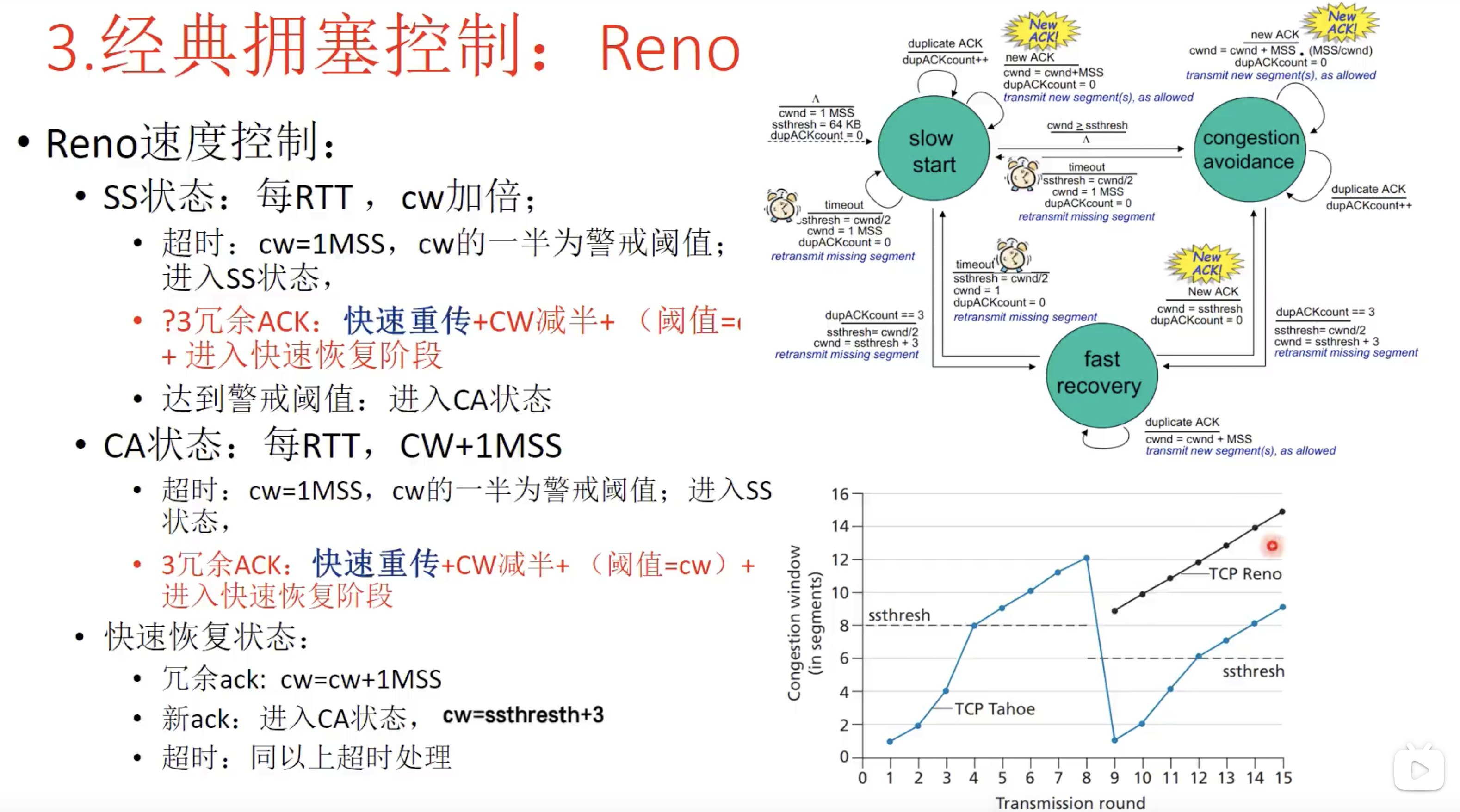
注意:Reno算法适合单个段丢失,如果多个段连续丢失,因为只收到了一个冗余确认,并没有收到下一个丢失的确认就进入拥塞避免阶段,很容易由于超时重传再次进入慢启动阶段。
所以New Reno在快速恢复阶段做了改进,加入了多个冗余ack的快速重传
3. New Reno

RACK 是指:当所有 拥塞时候的段 都得到确认后才能够叫做RACK

基于延迟的拥塞控制:Vegas
解决痛点:reno不敏感,调整粗暴(造成网络震荡,网络带宽利用率不高)

Vegas使用延迟的变化(细颗粒度,先超时,后三个冗余ack)来感知网络中的拥塞,可以更早感知,调节窗口的方式也更加的温和。
RTO:Retransmition Time Out 超时重传事件
是基于500ms计时颗粒度(粗粒度)计算的,平均往返时间,加上四倍的标准差就是超时时间。Reno先收到三个冗余ack,后超时。
减少1/8,波动性不大。

BaseRTT 维护的是最小RTT,

如果是协同的话,抢不到太多的带宽(调整温和),敏感且懂礼貌的人容易吃亏。
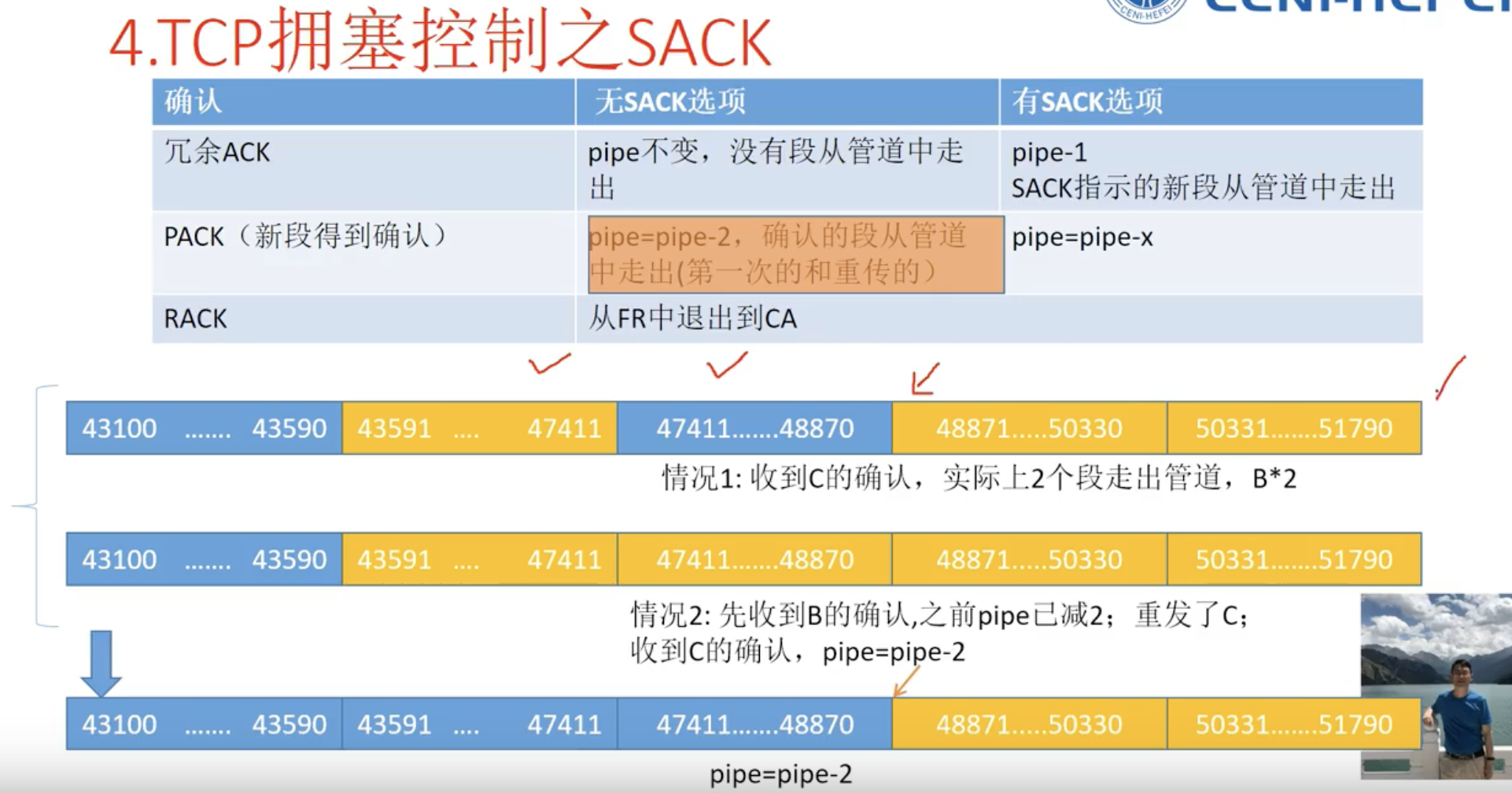
SACK
针对New Reno算法在连续段丢失情况下,一个RTT只能恢复一个丢失段效率不高的问题提出改进。 发送方收到SACK知道接收方收到段的情况,通过选项知道接收方缺失的段。将这些段维持在scoreboard中,只要pipe小于cwnd,发送方就可以先发计分板中的丢失段;在发送完毕老的丢失段后,pipe如仍小于cwnd,发送方发送新段,每发送一个段,pipe+1。 发送方收到确认 从pipe当中减去1或者2,将管道中丢失的走出去的段从pipe中减去。 将(pipe小于cwnd)发送条件和发什么解耦。


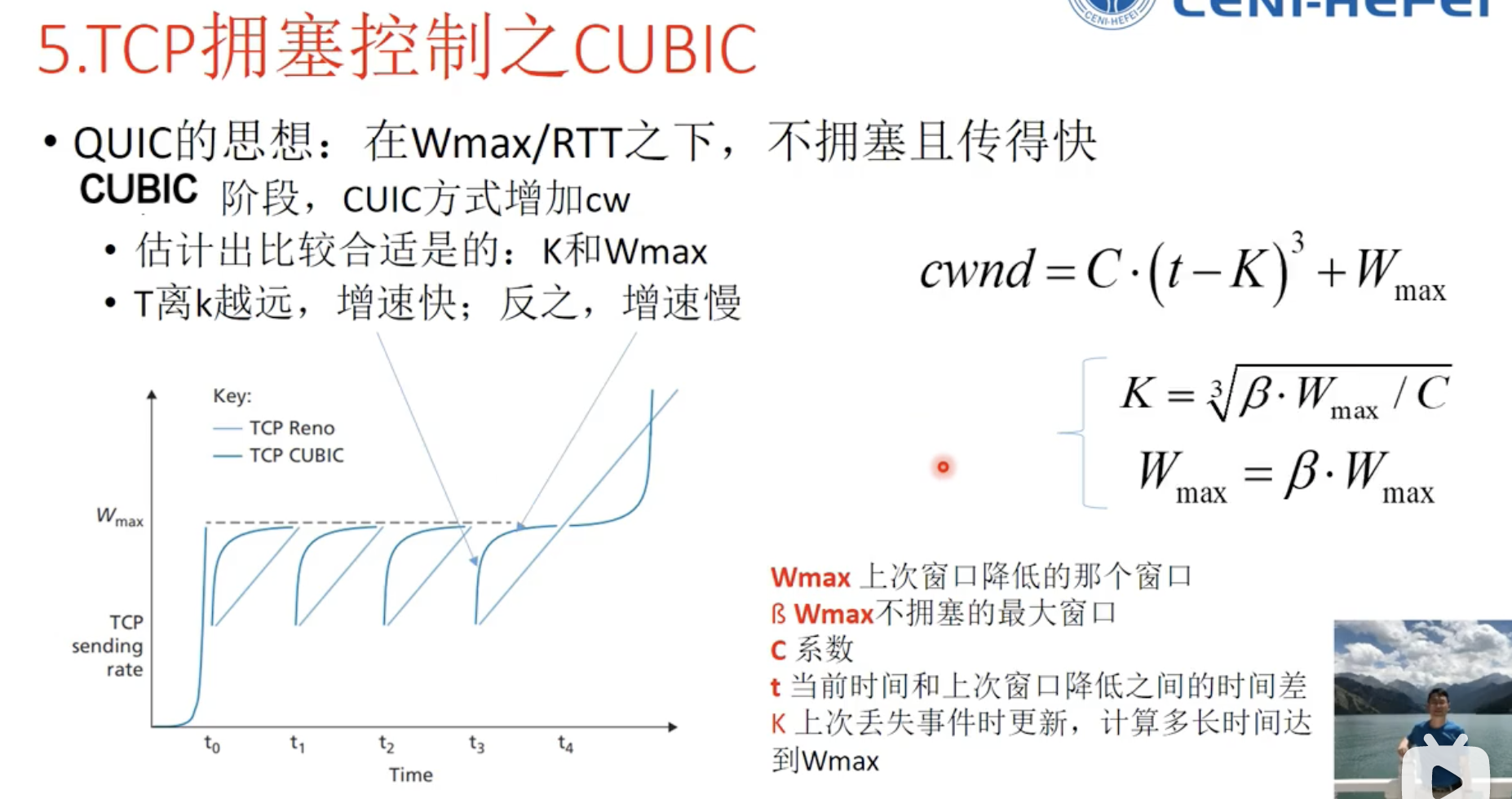
CUBIC算法(CA阶段使用立方体的方式,之前加法增大过于保守)

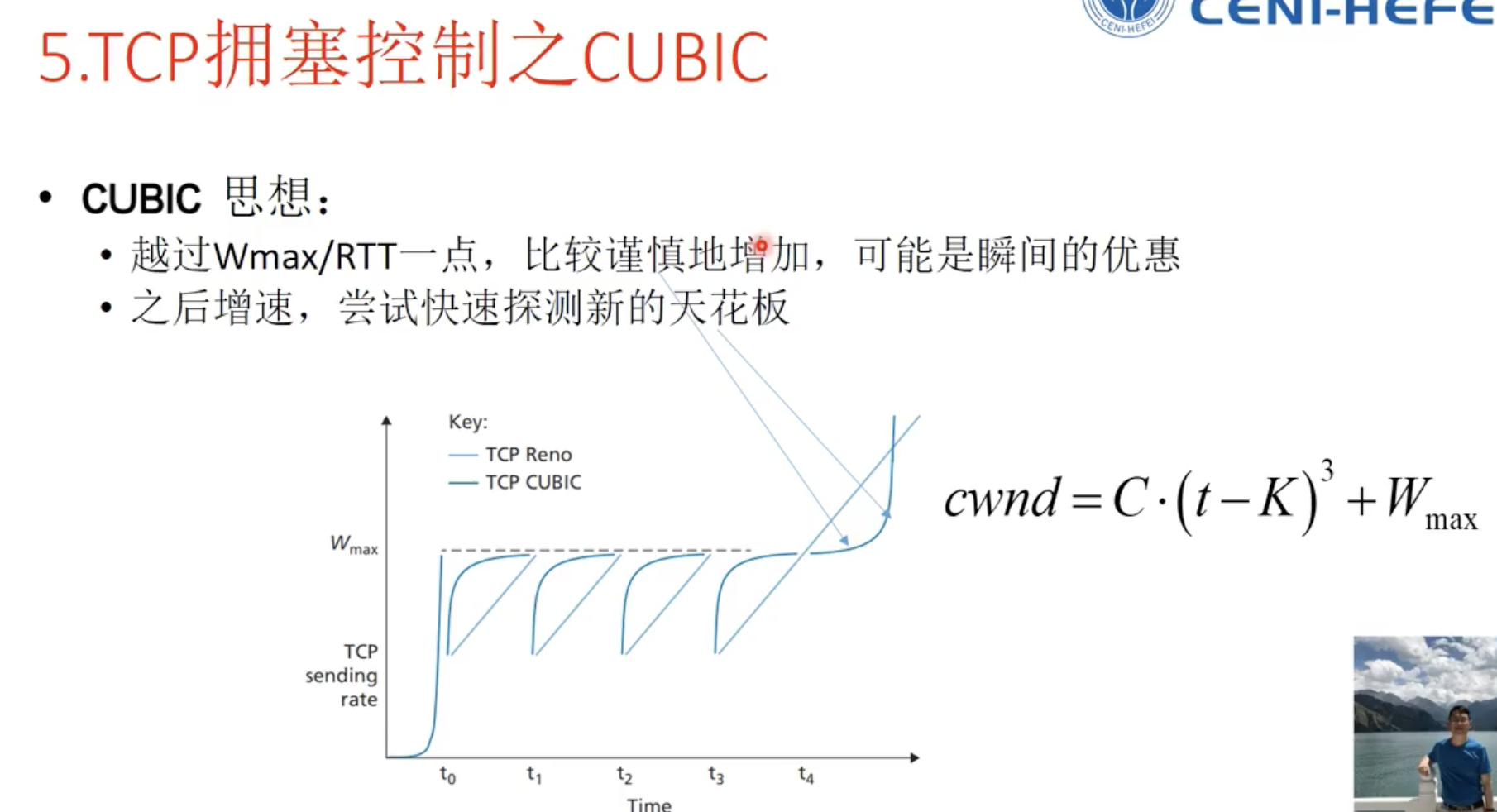
BBR拥塞控制算法
解决痛点:


BBR是基于模型的。把其他主机对的通信看成是带宽的变化和往返延迟的变化。
往返延迟RTT * 瓶颈链路的带宽 = BDP
1. 通信模型(拥塞变化的点)
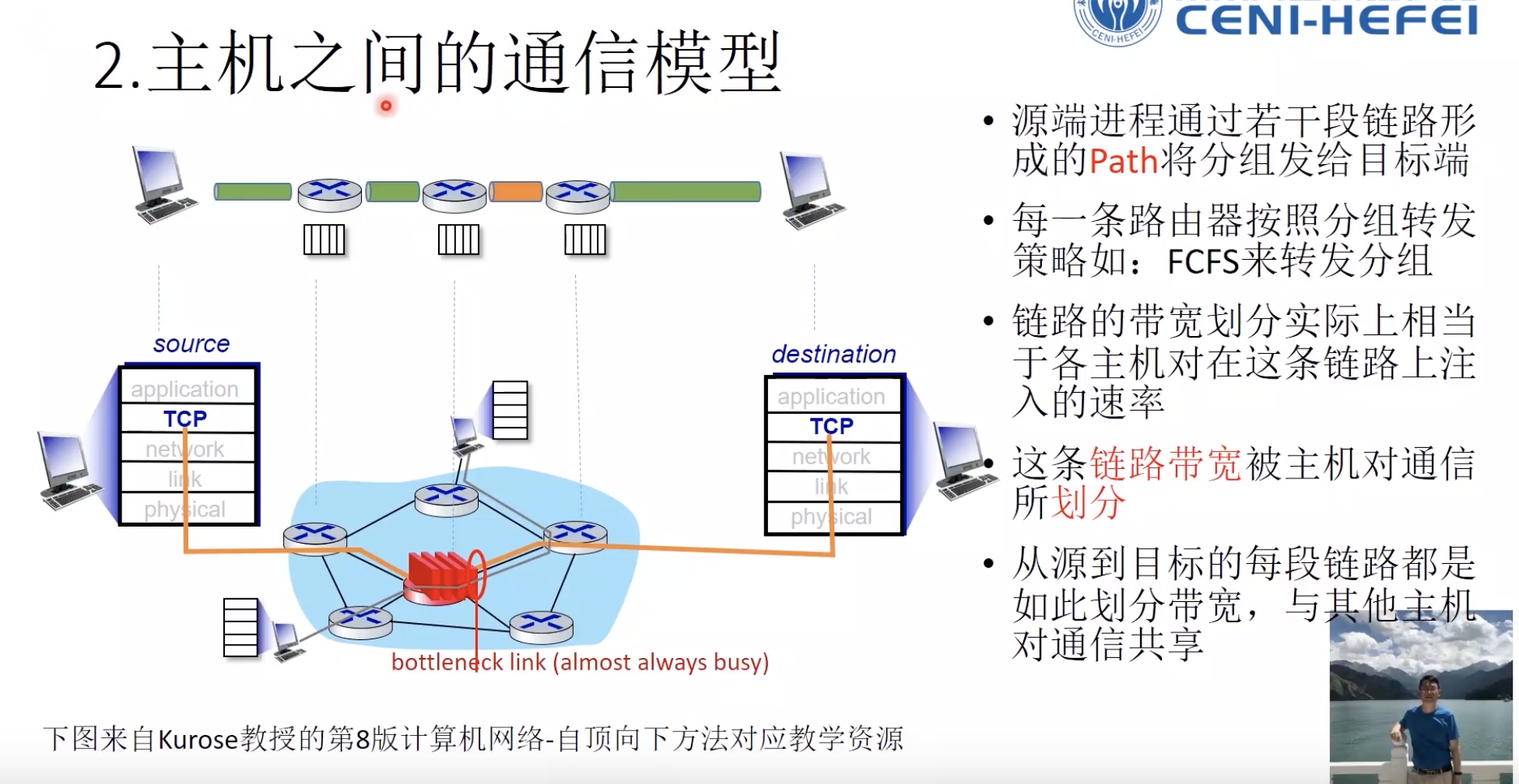
- 瓶颈链路的带宽
- 往返延迟
排队会造成排队延迟,增加延迟。
BBR思路:摸清瓶颈链路,摸清往返延迟,算出带宽延迟级,
使得发送速率不要超过瓶颈流量带宽,
inflight的不要超过带宽延迟积
由于主机对会改变,瓶颈链路的带宽会发生变化,水管变粗变细
一般路由不变,往返延迟不变发生变化。但是有些环境中设计到路由的变化,也需要监测,走不同的水管
长期来看动态,短期是静态。需要经常测量上面两个量
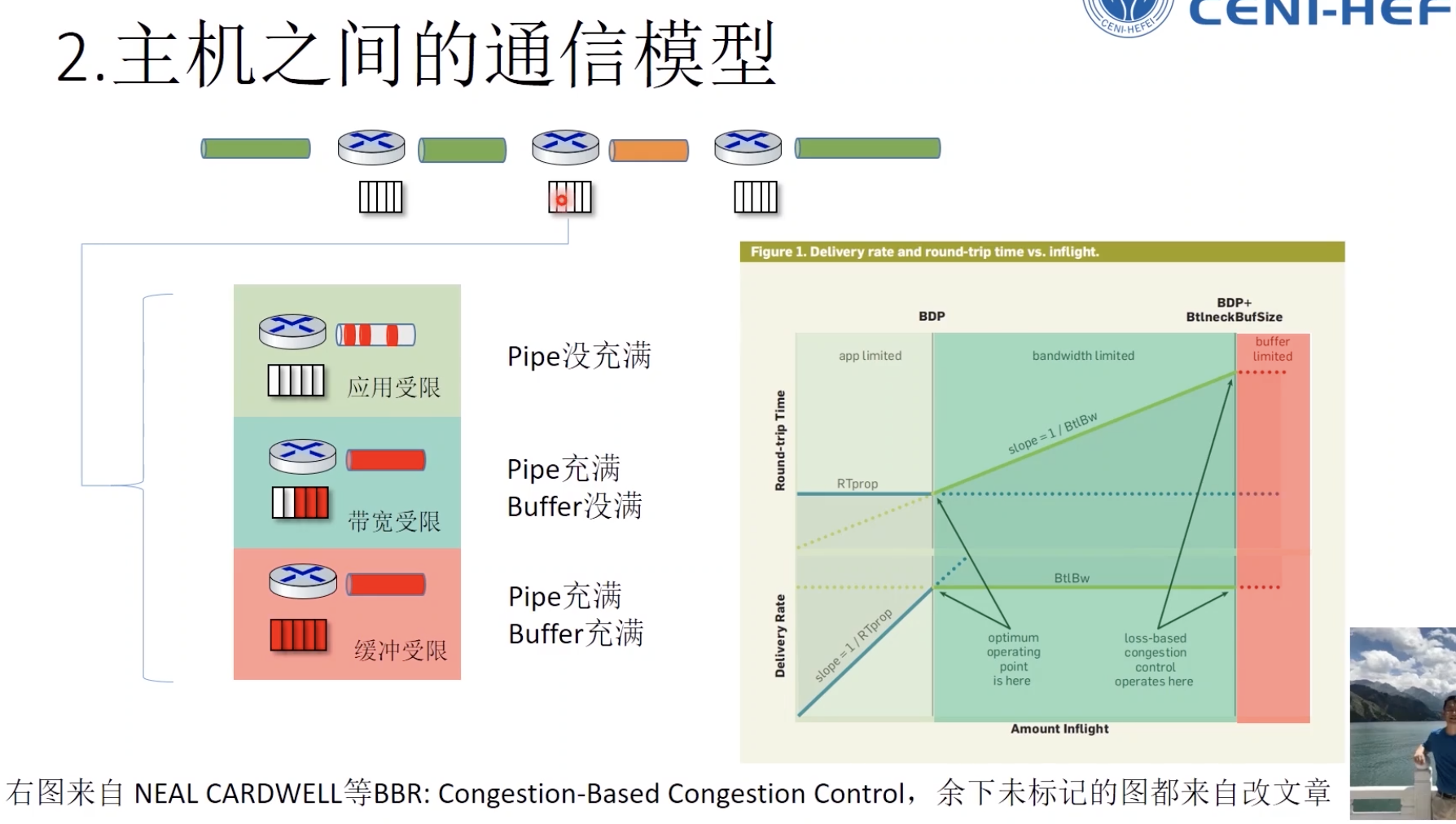
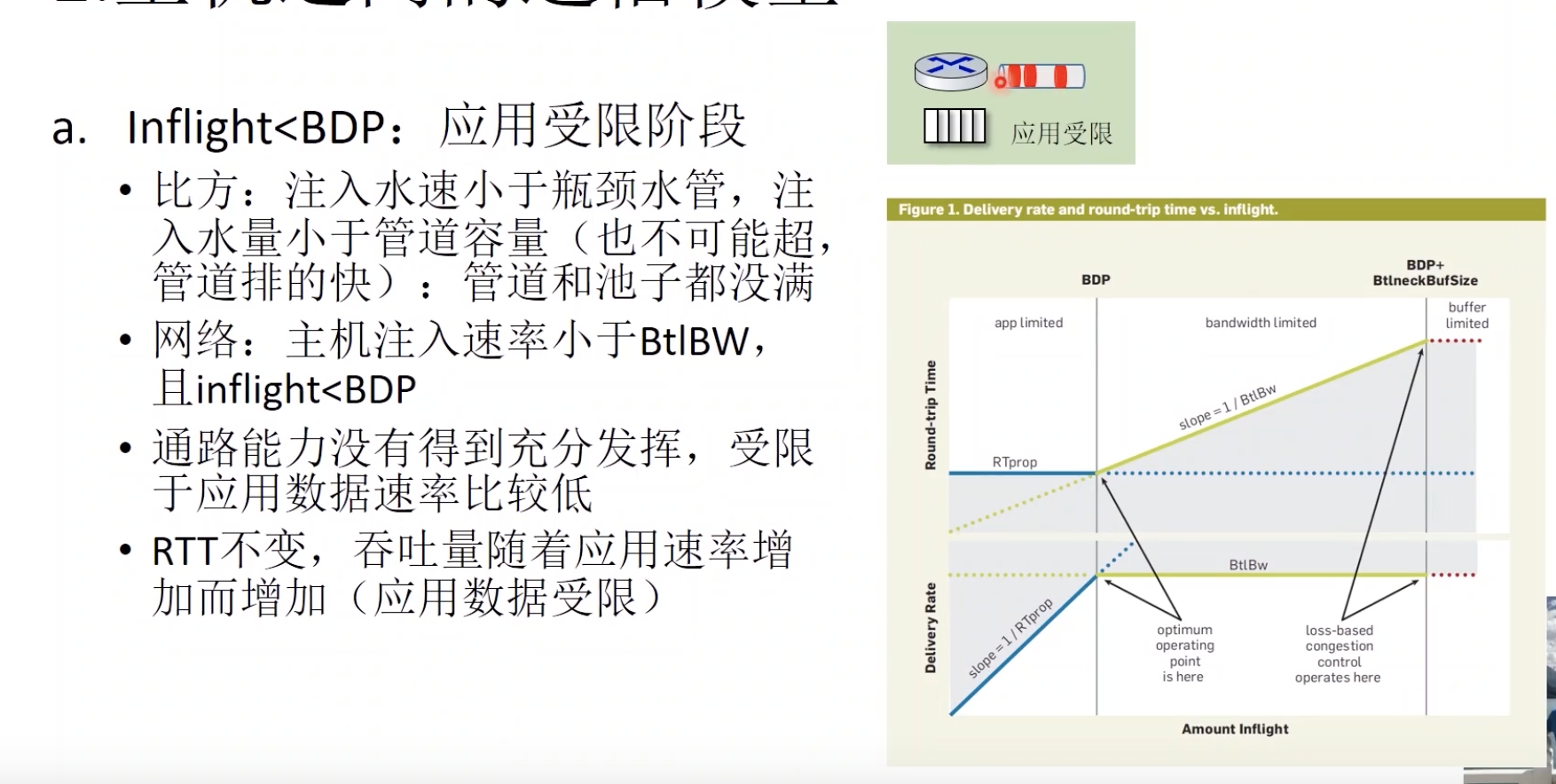
- 应用受限
- 带宽受限
-
缓冲buffer受限

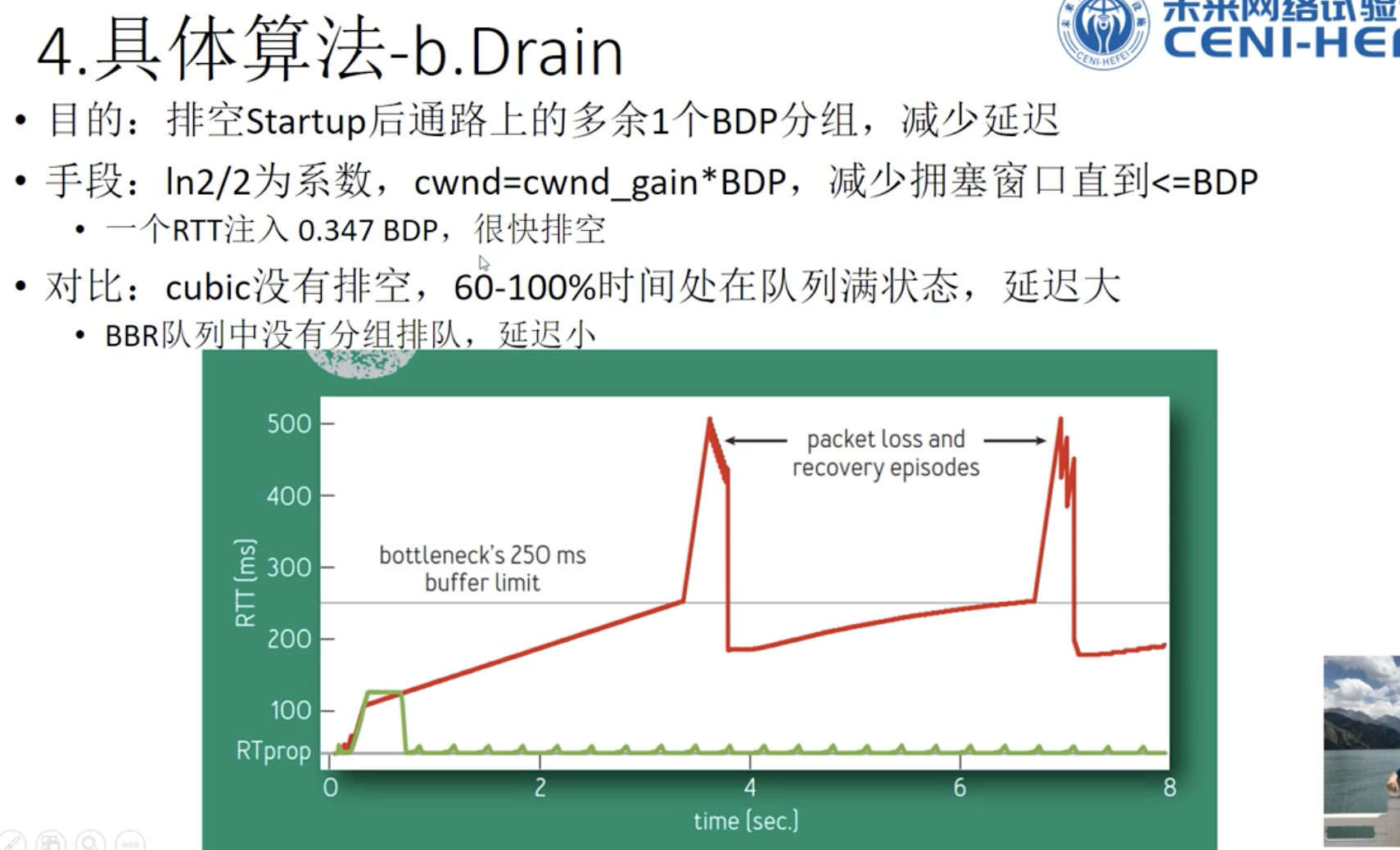
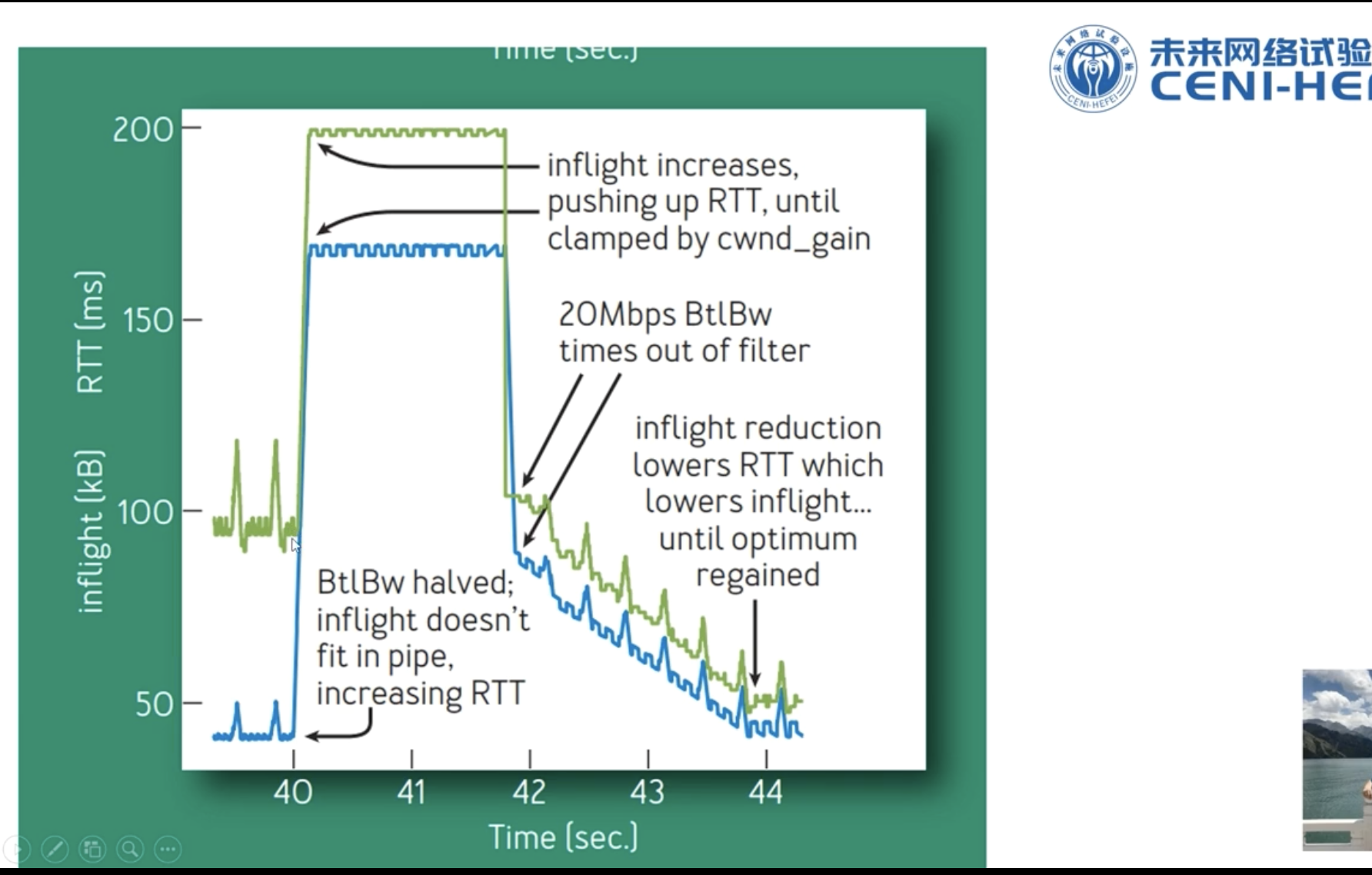
超过带宽延迟积,进入第二个阶段,延迟会增加,但是不会造成传输吞吐量变小。
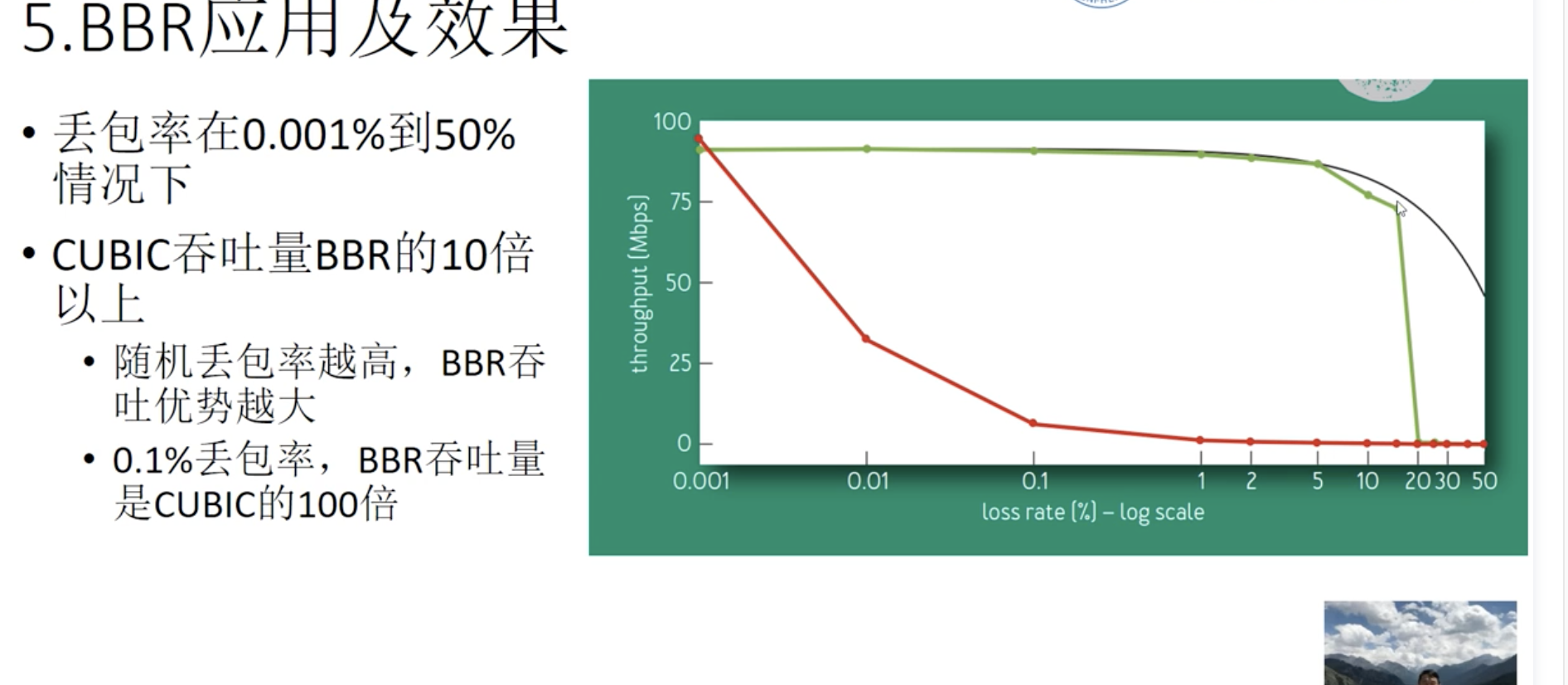
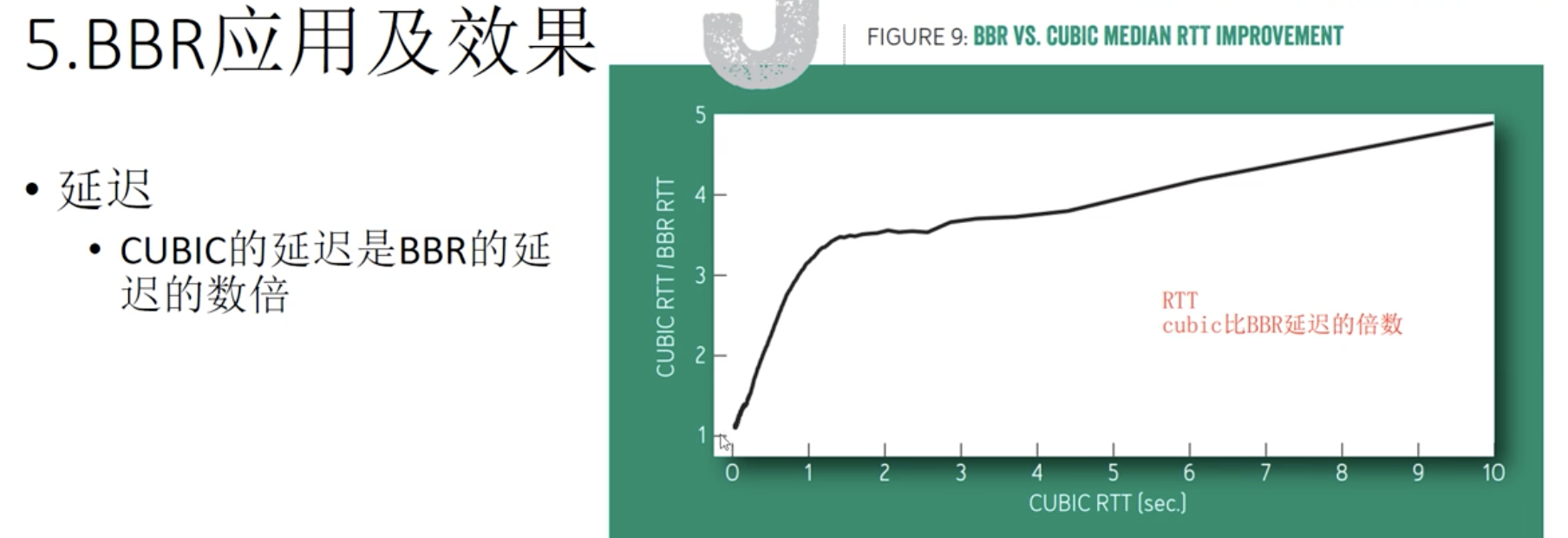
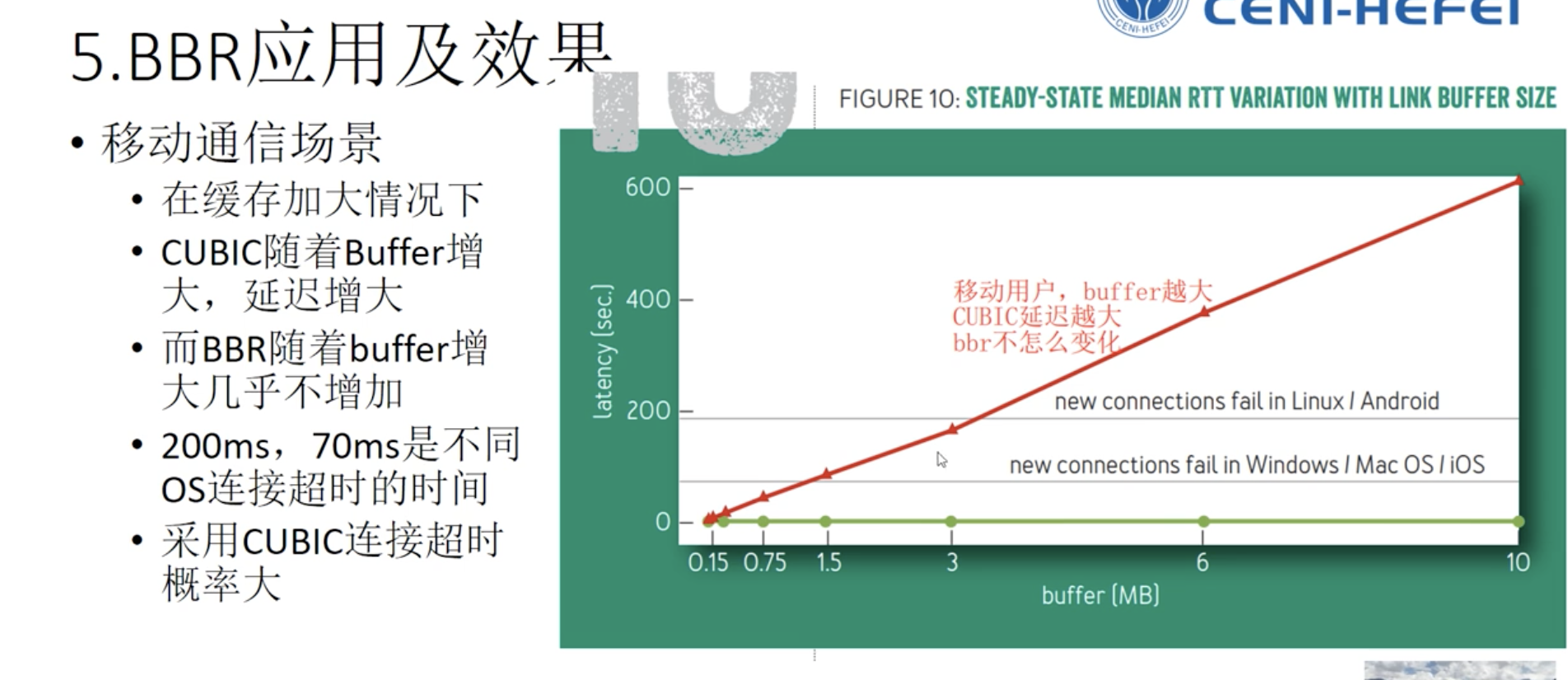
丢失因为buffer扩大,时机会比较迟,效果很差。

因为早期buffer比较小,丢失基本意味着拥塞,但随着路由交换设备buffer的扩大,造成以前算法拥塞控制时机很迟,效果很差,网络延迟变大。而且矫枉过正,造成网络震荡。
过了优化运行点只有坏处,没有好处,带宽受限阶段,瓶颈带宽不变,网络延迟增大,buffer受限时,出现丢包,RTT极大。
2. 控制原理
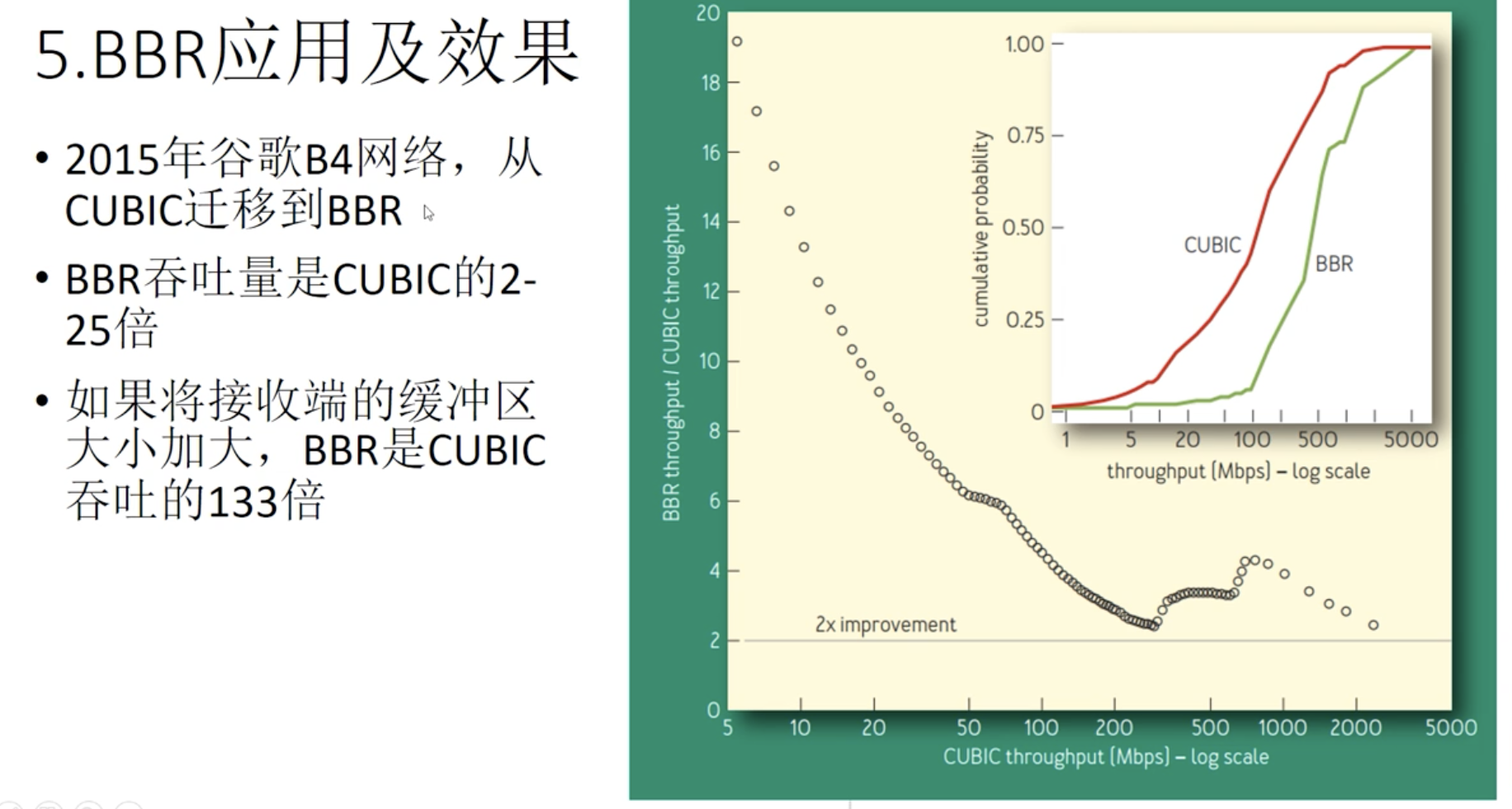
谷歌B4网络
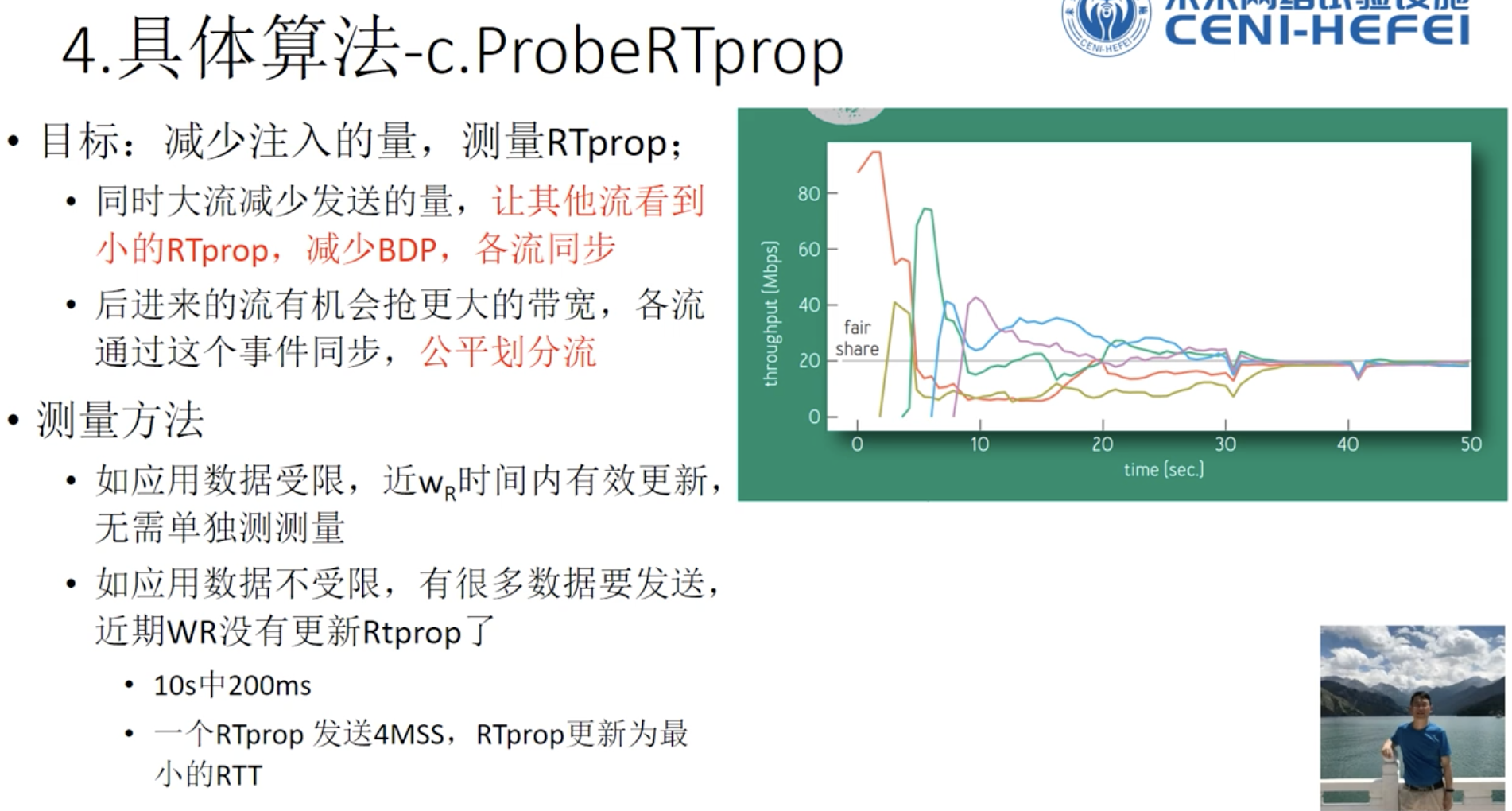
- 运行在应用受限阶段,测量RTT
- 运行在带宽受限阶段,测量链路带宽
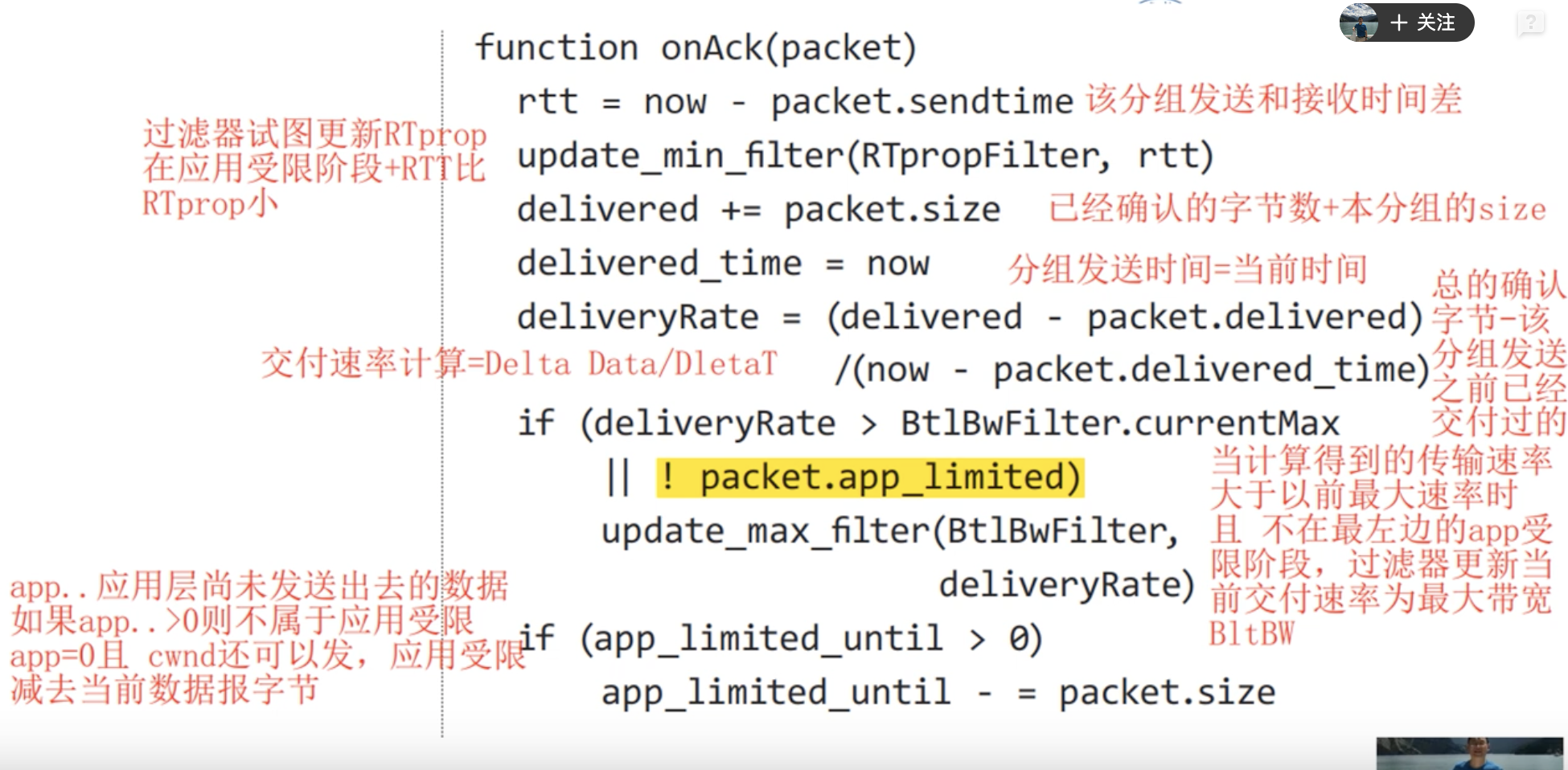
1. 测量RTprop往返延迟

2. 测量瓶颈链路带宽
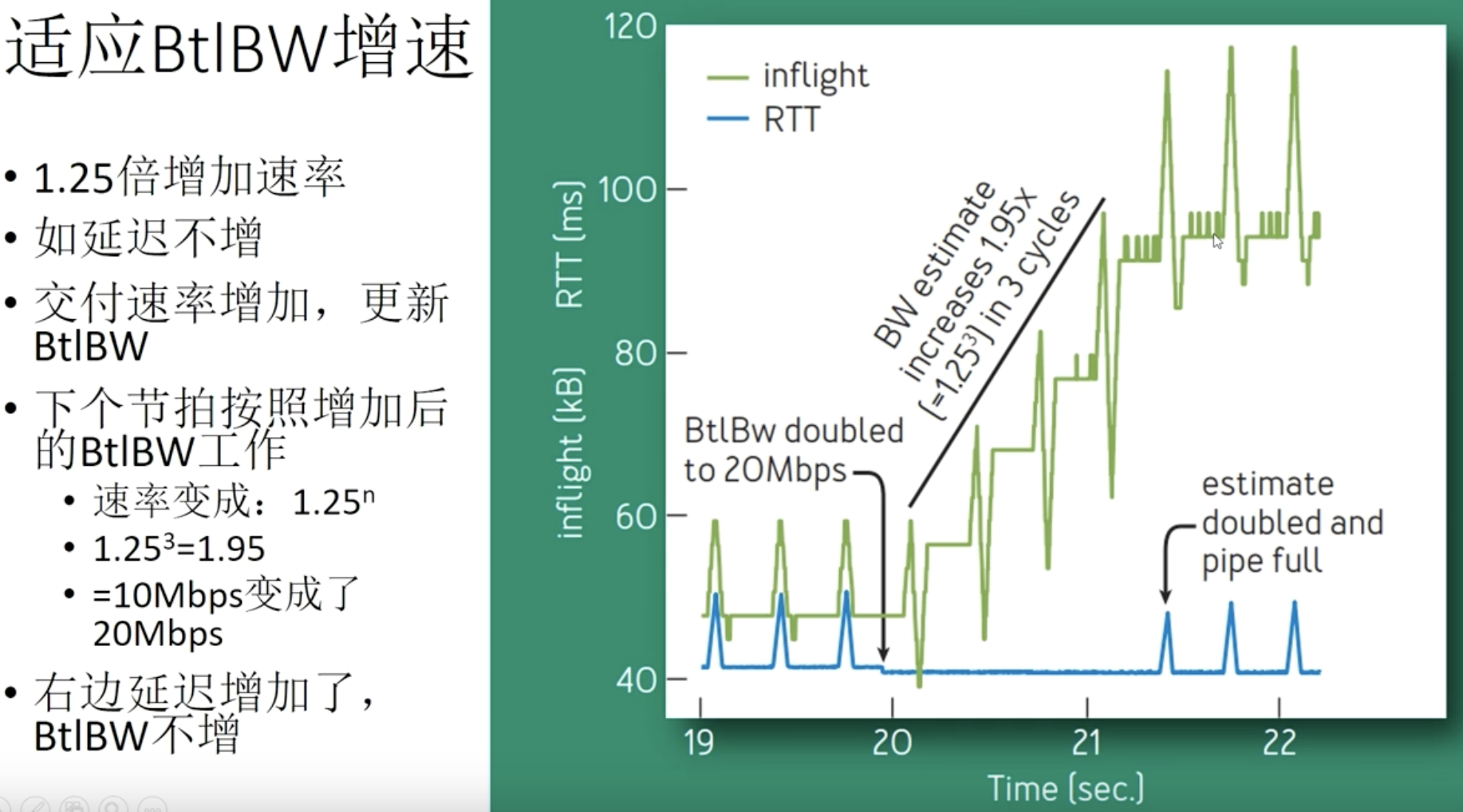
连续三个注入inflight后,RTT增加交付速率不增加25%,则判断进入带宽受限阶段,最大值可以当作链路带宽。

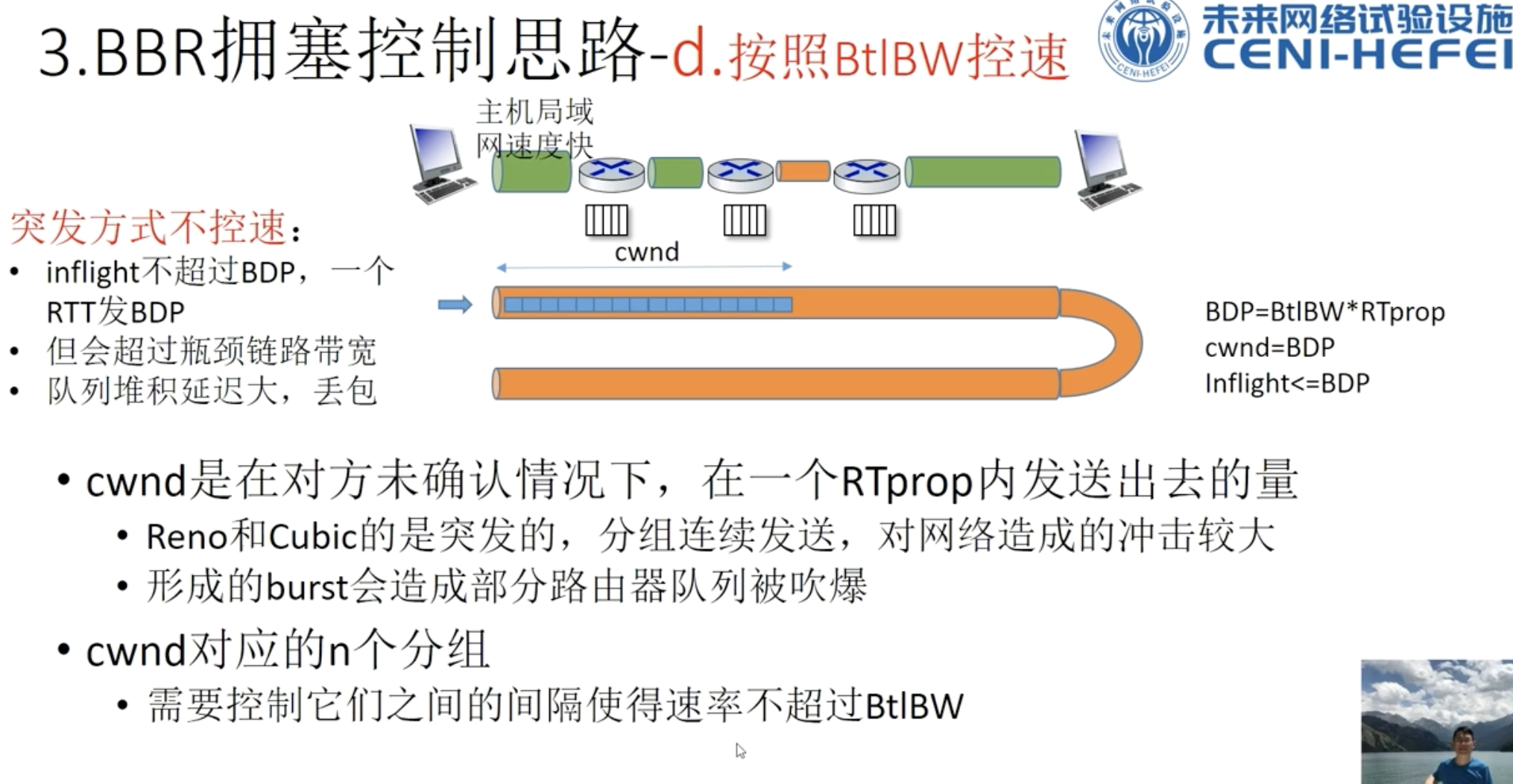
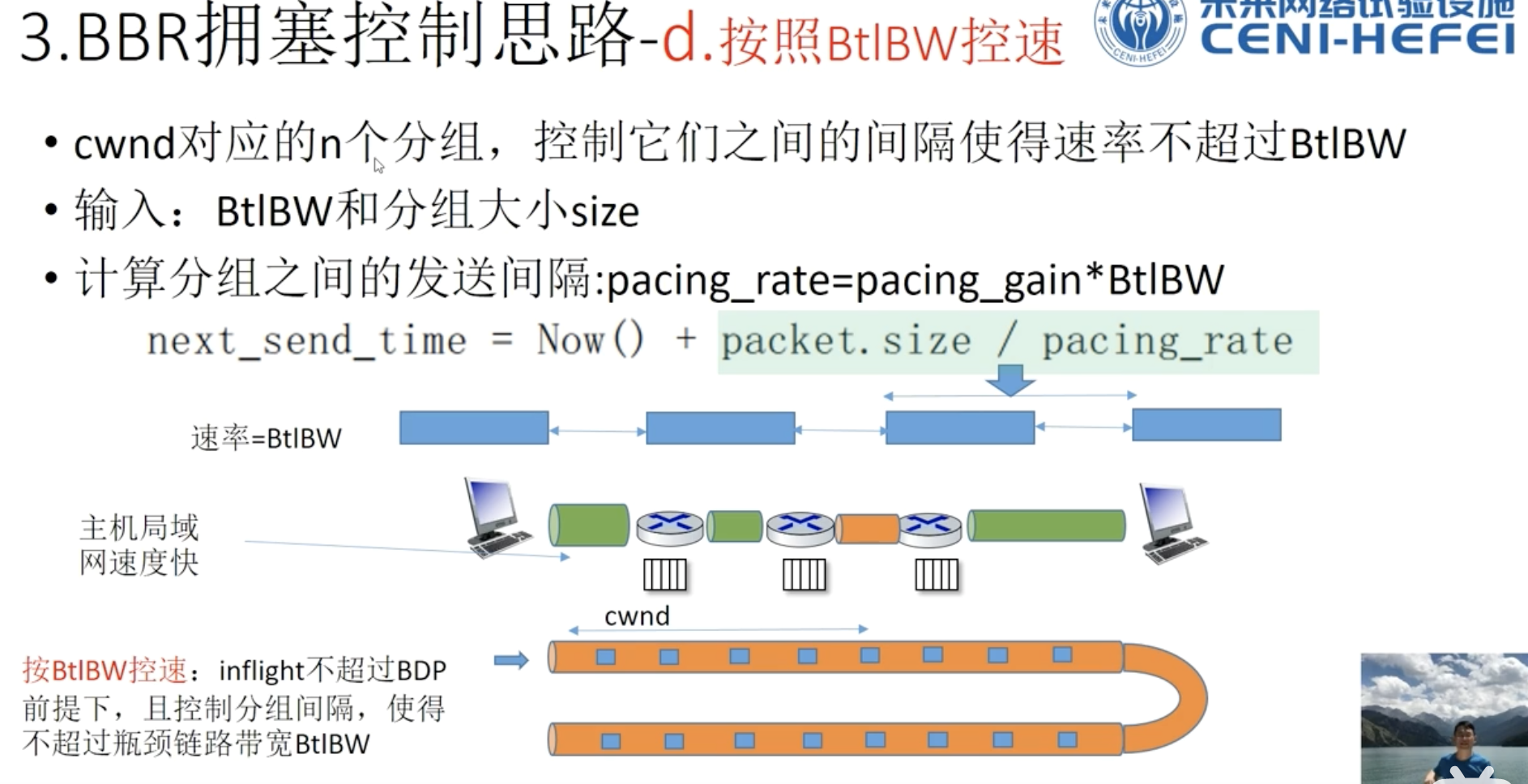
pacing_time 节拍时间
3. 算法与应用