

-
grep:(global search regular expression and print out the line)文本过滤工具
-
sed:(stream editor)流编辑器,文本编辑工具
-
awk:(三位发明者的首字母)linux的实现为gawk,文本报告生成器(格式化文本)
正则表达公式:
由**==特殊字符以及文本字符==**所编写的模式,其中有些字符不表示其字面意义,而是用于表示控制或通配的功能
元字符不同分为两类:
- 基本正则表达式 BRE
- 扩展正则表达式 ERE
一. grep
-
作用:文本过滤工具,根据用户==指定的“模式(过滤条件)”==对目标文本==逐行==匹配检 查,打印匹配到的行;
-
模式:由正则表达式的元字符及文本字符所编写的过滤条件
grep [OPTIONS] PATTERN [FILE...] grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
1. option
-i | ignore | |
-o | only | |
-v | invert | |
-q | quiet | |
-E | Extend | 扩展正则 |
-a | all | --text 不要忽略二进制的数据 |
-A | After | |
-B | Before | |
-C | Context | |
–color=auto |
2. 正则表达式/PATTERN
基本正则表达式元字符
2.1 字符匹配
. | 任意单个字符 |
[] | 指定范围==内==任意单个字符 |
[^] | 指定范围==外==任意单个字符 |
[:digit:] | 数字 |
[:lower:] | 小写 |
[:upper:] | 大写 |
[:alpha:] | 字母 |
[:alnum:] | 包含数字和字母的 |
[:punct:] | 标点符号 |
[:space:] | 空白字符(包括制表符、空格、换行符等) |
[root@localhost ~]# grep "r[[:alpha:]][[:alpha:]]t" /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
注意:
[[:alpha:]]
==外中括号==表示匹配单个字符
==内中括号==表示单个字母字符
2.2 匹配次数
限制前面字符出现的==次数==(默认贪心模式,能匹配多长就多长)==反斜杠是转义==
| 匹配前面的字符 | |
|---|---|
* | ==任意次==; 0,1,多次 |
.* | ==任意==长度的==任意==字符 |
\? | 0次或1次,==可有可无== |
\+ | 1次或多次,==至少一次== |
\{m\} | ==精确指定m次== |
\{m,n\} | ==至少m次,至多n次== |
\{0,n\}至多n次 | |
\{m,\}至少m次 | |
2.3 位置==锚定(行首、行尾、词首)==
| 行、词 | |
|---|---|
^ | 行首锚定 |
$ | 行尾锚定 |
^PATTERN$ | 匹配整行 |
^[[:space:]]*$ | 含有空白字符的行 |
\< | 词首锚定 |
\> | 词尾锚定 |
\<PATTERN\> | 精确锚定 |
练习题:
1. grep -v "/bin/bash$" /etc/passwd
# 注意需要锚定词首和词尾,不然就不是两位或三位数。
2. grep "\<[[:digit:]]\{2,3\}\>" /etc/passwd
3. grep "^[[:space:]]\{1,\}[^[:space:]]\{1,\}" /etc/grub2.cfg
load_env
set default="${next_entry}"
set next_entry=
save_env next_entry
set boot_once=true
set default="${saved_entry}"
menuentry_id_option="--id"
4. netstat -ant |grep "LISTEN[[:space:]]*$"
tcp 0 0 0.0.0.0:139 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:445 0.0.0.0:* LISTEN
tcp6 0 0 :::3306 :::* LISTEN
tcp6 0 0 :::139 :::* LISTEN
tcp6 0 0 :::22 :::* LISTEN
tcp6 0 0 :::445 :::* LISTEN
tcp6 0 0 :::33060 :::* LISTEN
2.4 分组及引用(==后向引用==:引用前面括号匹配到的字符)
\(\) | 将一个或者多个字符捆绑在一起,==当作一个整体==进行处理 |
| grep引擎会自动记录分组变量 | |
\1 | 第一组左括号,右括号匹配到的内容 |
\2 | |
\3 | |
3. egrep fgrep
egrep :扩展grep
fgrep :fastgrep 默认不用正则
三者可以通过-E -F -G切换
- 元字符

==注意:括号()和<>需要转义==
-
练习
1.
grep -i "^s" /proc/meminfo
grep -i "^[sS]" /proc/meminfo
grep -E "^s|^S" /proc/meminfo
grep -E "^(s|S)" /proc/meminfo
2.
# 注意锚定词尾
grep -E "^(root|mysql|samba)\>" /etc/passwd
3.
grep -E "\<[[:alpha:]]*\>\(" /etc/rc.d/init.d/functions
grep "\<[[:alpha:]]*\>(" /etc/rc.d/init.d/functions
纠正后:
grep -E "\<[_,[:alnum:]]*\>\(\)" /etc/rc.d/init.d/functions
4.
echo `pwd` |egrep -o "^\/\<[[:alpha:]]+\>"
纠正后:注意从行尾开始往前定位
echo /root/mysite/layouts/ |grep -E -o "[^/]+/?$"
5.
ifconfig |grep -E '\<[1,2]{1}[0-9]{0,1}[0-9]{0,1}\>'
纠正后:
从个位数,十位数到百位数开始
1-9
10-99
100-199
200-249
250-255
ifconfig |grep -E '\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>'
6.
1-255
0-255
0-255
1-254
ifconfig |grep -E -o '\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>.\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>.\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-4])\>'
7.
注意锚定词首词尾,行首,行尾
grep -E "^(\<[^:]+\>).*\1$" /etc/passwd
* 补充wc, cut, sort, uniq, diff
1. wc: world count
-l | line |
-w | word |
-c | 字节 |
2. cut
-d | 分隔符 |
-f | 第几列 |
3. sort
排序算法很厉害
-t char | 指定分隔符 |
-k# | 排序比较的字段 |
-n | 按数值序比较 |
-r | 逆序 |
-f | 忽略字符大小写 |
-u | ==重复的行只保留一份==。重复行:连续且相同 |
4. uniq
-c | 显示每行的重复次数 |
-u | 仅显示唯一的行 |
-d | 仅显示不唯一的行 |
5. diff
逐行比较不同
6. patch补丁(可正向逆向)
diff old file Newfie > patch_file
-u 使用unfied机制,即显示要修改的行的上下文,默认为三行。
-R 可正向,可逆向恢复

-
练习
取出ifconfig 命令结果中的ip地址
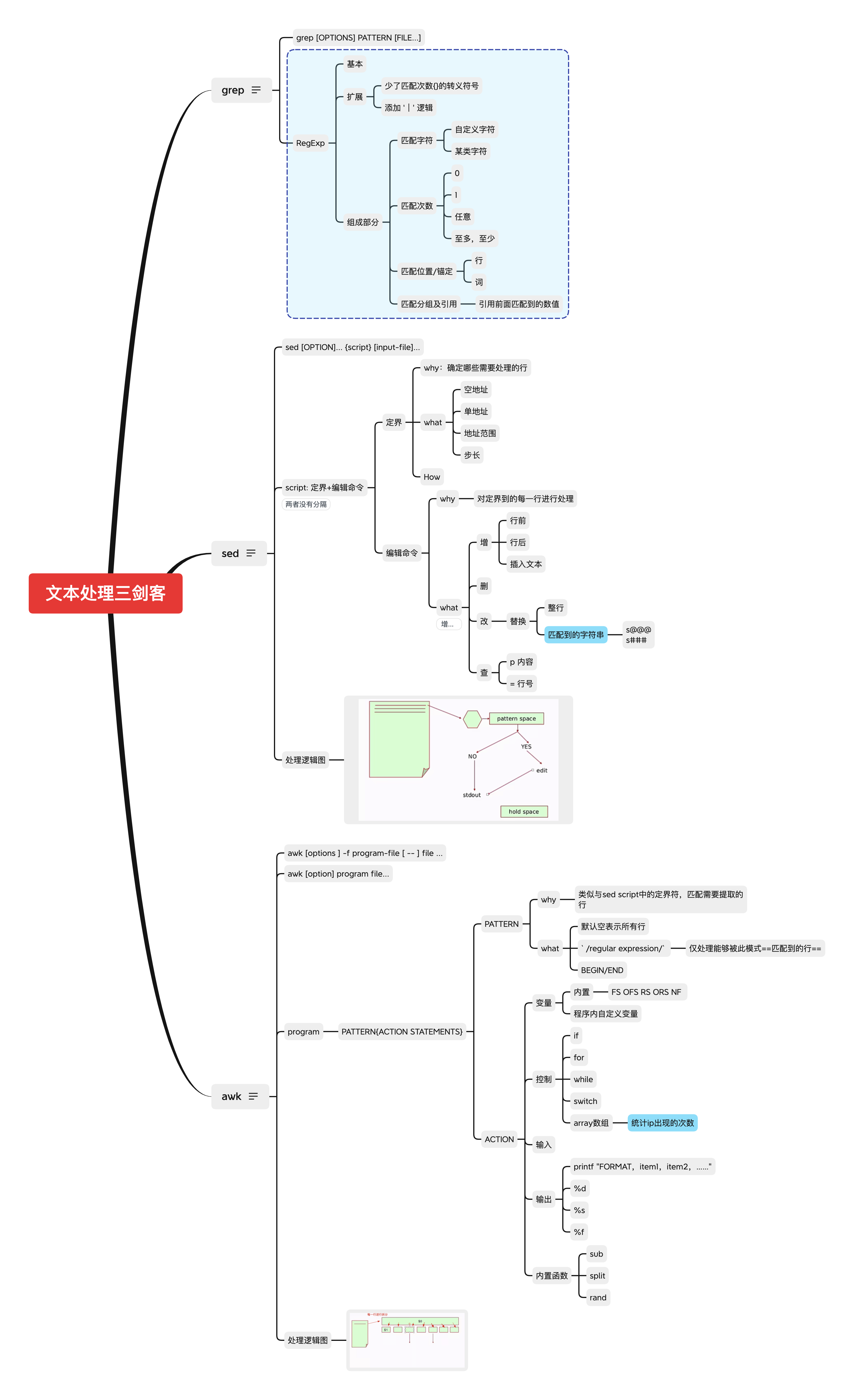
二. sed
sed [OPTION]... {script} [input-file]...
1. option
-n | quiet | 不输出模式空间中的内容至屏幕 (每一行都会进入模式空间,等于输入的全都不进行输出,输出的都是script编辑命令的操作结果) |
-e | 多script同时操作输入文本,多点编辑-e script -e script | |
-f | file | script脚本文件,每行一个编辑命令 |
-r | regular | 支持regexp-extended 扩展正则表达式 |
-i[SUFFIX] | edit files in place (makes backup if SUFFIX supplied) | 直接编辑原文件, -i加后缀会添加文件+后缀的备份文件 |
-n 前后对比,把script定界中匹配到的行过滤掉了
[root@localhost layouts]# cat -n /etc/fstab
1
2 #
3 # /etc/fstab
4 # Created by anaconda on Sun Nov 8 17:58:16 2020
5 #
6 # Accessible filesystems, by reference, are maintained under '/dev/disk'
7 # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
8 #
9 UUID=09780b2e-66e0-4fc3-8d91-7d9ddd350bbb / ext4 defaults 1 1
10 UUID=79e8f2c8-9f29-4248-9181-39209540d9a8 /boot xfs defaults 0 0
11 UUID=b822f2a7-37ba-4df5-9a1e-f82f9e2f9bfe swap swap defaults 0 0
[root@localhost layouts]# sed -n '1~2a\123' /etc/fstab
123
123
123
123
123
123
[root@localhost layouts]# sed '1~2a\123' /etc/fstab
123
#
# /etc/fstab
123
# Created by anaconda on Sun Nov 8 17:58:16 2020
#
123
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
123
#
UUID=09780b2e-66e0-4fc3-8d91-7d9ddd350bbb / ext4 defaults 1 1
123
UUID=79e8f2c8-9f29-4248-9181-39209540d9a8 /boot xfs defaults 0 0
UUID=b822f2a7-37ba-4df5-9a1e-f82f9e2f9bfe swap swap defaults 0 0
123
2. script组成
==地址定界编辑命令==(注意中间无分割)
-
地址定界
-
空地址:对全文进行处理
-
单地址:
#指定行 /pattern/被此模式所匹配到的每一行 -
地址范围
#,#[指定行,指定行] #,+#[指定行,指定行+#] #,/pattern/[指定行,pattern匹配行] /pattern1/,/pattern2/[pattern1匹配行,pattern2匹配行] -
步进
1~21开始,步长为2,所有奇数行 2~22开始,步长为2,所有偶数行
-
-
编辑命令
ddelete 删除匹配行 ppattern 显示模式空间的内容 a \textappend 在匹配行后append i \textinsert 在匹配行前insert c \textrelace&change 匹配到的行替换为text w /WritePathwrite 保存模式空间匹配到的行 r /FilePathreplace&append 读取文件,并追加到模式空间匹配行后面 =行号 为模式匹配到的行打印行号 !地址定界 !编辑命令sed -n '2~2!=' testtest11
1
3s///替换标记search&replace ==分隔符可以指定== s@@@``s###
==替换标记==:g全局替换w替换成功的结果保存p显示打印成功的行
3. input-file
可以加多个文件,进行处理。
练习
1.
sed -r '/^[[:space:]]+/s/^[[:space:]]+//p' /etc/grub2.cfg
2.
sed -r -n '/^#/s/^#[[:space:]]*//p' /etc/fstab
3.
echo '/home/xcg/desktop' |sed 's@[^/]*\/\?$@@'
4. 高级编辑命令
==模式空间,保持空间==
脑洞大开:

三. awk
awk (1) - pattern scanning and processing language
awk197几年就已经出现了,GNU awk是linux上重新实现的。
模式扫描和处理==语言==,脚本语言解释器编程语言。
1. 基本用法
awk [options] 'program' file ...
program支持条件判断,循环,也有变量。
program :
==PATTERN{ACTION STATEMENTS}==
语句之间用分号分隔
2. option
-F | 分隔符 | |
-v | 定义内建变量 | -v FS=':' (field seperator 默认为空白字符) -v OFS=':' (output field seperator 默认为空白字符) |
3. program
3.1 print
3.2 变量
3.2.1 内建变量
FS | field seperator | 默认为空白字符 |
OFS | output field seperator | 默认为空白字符 |
RS | Input Record Separator | 输入时的换行符 ,会按分隔符进行换行处理 |
ORS | output Record seperator | 输出时的换行符 |
NF | number of fields | 字段数量 |
{print $NF} 最后一个字短 | ||
{print NF} 字段数量 | ||
NR | number of record | 行数 |
FNR | File number of Record | 各文件分别计数,行数 |
FILENAME | 当前文件名 | |
ARGC | 命令行参数的个数 | |
ARGV | 数组,保存的是命令行所给定的各个参数 |
3.2.2 自定义变量
-v var = value
变量区分字符大小写
- 在
program中直接定义
3.3 printf命令
格式化输出:printf "FORMAT,item1,item2,……"
-
FORMAT必须给出
-
不会自动换行,需要显式给出换行控制符,\n
-
FORMAT中需要分别为后面的每个item指定一个格式化符号
-
格式符
%c显示字符的ASCII码 %d,%i十进制整数 %e,%E科学计数法数值显示 %f显示为浮点数 %g%G以科学计数法或符点形式显示数值 %s显示字符串 %u无符号整数 %%显示%自身 -
修饰符
#[.#]第一个 #数字控制显示的宽度,第二个#表示小数点后的精度%3.1f -==左对齐== %-15s + 显示数值的符号
-
3.4 操作符
-
算数操作符
+ - * / ^ % -x +x -
字符串操作符:没有符号的操作,字符串连接
-
赋值操作符:
= += -= *= /= ^= %= ++ -- -
比较操作符
> >= < <= != == -
==模式匹配符==
~ 是否匹配 !~ 是否不匹配 -
逻辑操作符
&& || ! -
函数调用
function_name(argu1, argu2,……) -
条件表达式
?::uid >= 1000的为普通用户,否则为系统用户
3.5 PATTERN
==类似于sed的定界符==
empty | 空模式,匹配每一行 |
/regular expression/ | 仅处理能够被此模式==匹配到的行== |
relation expression | ==关系/比较表达式==,结果为真才会被处理。真:结果为非0值。 |
line ranges | 行范围 |
startline,endline:/pattern1/,/pattern2/不支持直接给出数字的格式 | |
BEGIN/END模式 | BEGIN{}仅在开始处理文件中的文本之前执行一次 |
END{}仅在文本处理完成之后再执行一次 |
3.6 常用的action
expression | |
control statement | if while等控制语句 |
compound statements | 组合语句 |
input statements | 输入语句 |
output statements | 输出语句 |
3.7 控制语句
if(condition) {statements}
if(condition) {statements} else {statements}
while(condition){statements}
do{statements} while (condition)
for(expr1;expr2;expr3){statements}
break;
continue;
delete array[index]
delete array
exit
{ statements }
-
If - else
语法:
if(condition) {statements} else {statements}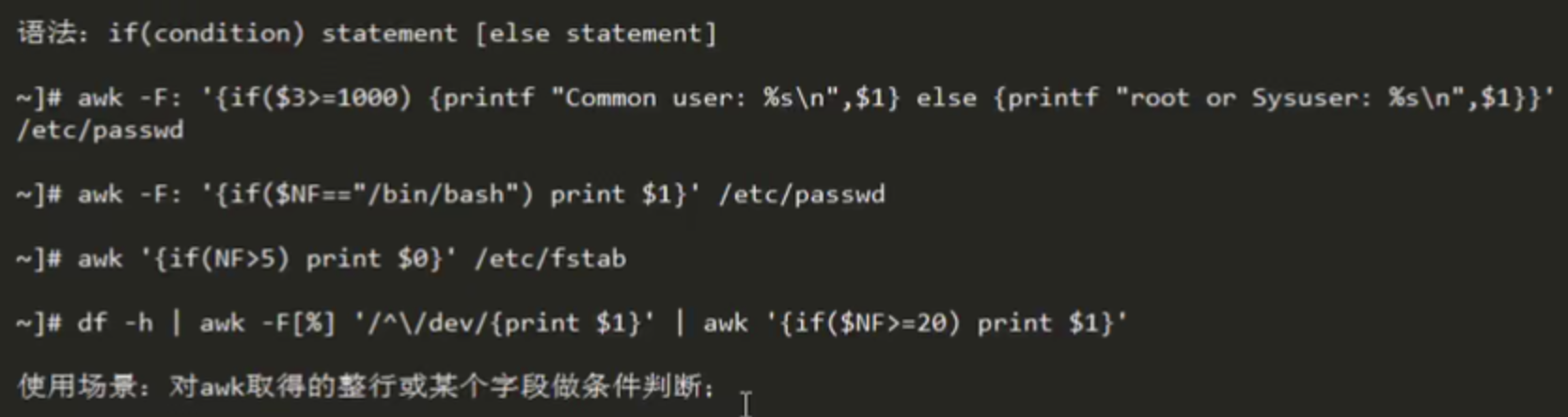
-
while
语法:
while(condition){statements} -
Do while
语法:
do{statements} while (condition)至少执行一次的循环体
-
for循环
语法:
for(expr1;expr2;expr3){statements} -
switch语句
语法:
switch(expression){case VALUE1 or /REGEXP:statement;case VALUE2 or /REGEXP2: statements;....} -
break 和 continue
-
next
提前结束对本行的处理而提前进入下一行。类似于
continue,但是next是表示行间,continue是表示行内。 -
array ==统计常用==
关联数组:
array[index-expression]
index-expression:-
可使用任意字符串。字符串需要使用==双引号==括起来。
-
如果某数组元素事先不存在,在引用时,awk会自动创建元素,并将其值初始化为“空串”
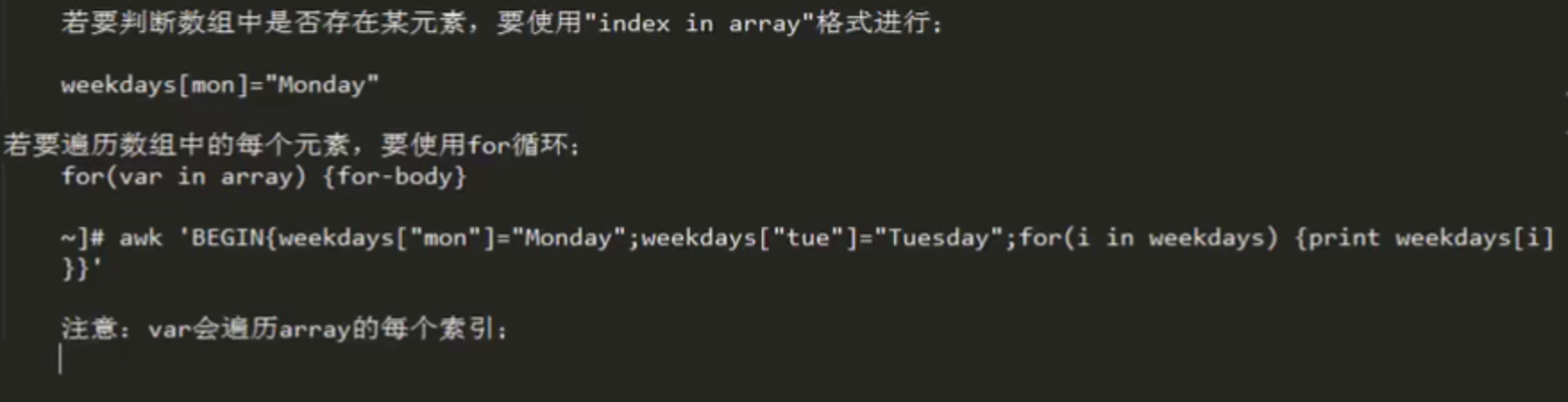
==按访问ip次数进行统计==
==练习:==
-
统计/etc/fstab文件每个文件系统类型出现的次数;
~]# awk '/^UUID/{fs[$3]++}END{for(i in fs) {print i,fs[i]}}' /etc/fstab swap 1 ext4 1 xfs 1 -
统计指定文件中每个单词出现的次数
~]# cat word.txt aaa bbb aaa ccc aaa eee bbb ccc ~]# awk '{for(i=1;i<=NF;i++) word[$i]++}END{for(i in word) {print i,word[i]}}' word.txt aaa 3 ccc 2 eee 1 bbb 2
-
-
3.8 函数
| 内置函数 | ||
|---|---|---|
| 数值处理 | rand() | 返回0和1之间的一个随机数,只有第一次取是随机的 |
| 字符串处理 | sub(r,s,[t]) | 查找t所表示的字符串中的匹配r的内容,并将其第一次出现替换为s表示的内容 |
gsub(r,s,[t]) | 全局替换,查找t所表示的字符串中的匹配r的内容,并将其所有次数出现替换为s表示的内容 | |
split(s,a[],r) | 以r为分隔符切割字符s,并将切割后的结果保存至a所表示的数组中 |
split用法示例:
# 以:分隔第三列字符,然后进行统计,格式化输出
~]# netstat -nlptu |awk '/^tcp\>/{split($4,ip,":");count[ip[1]]++}END{for(i in count) {printf"%-10s\t%d\n",i,count[i]}}'
127.0.0.1 1
0.0.0.0 3
