

组合操作符
本节介绍的分别是组合创建操作符/组合操作符。
-
组合创建操作符目标依然是创建操作
Observable,但来源不再是特定的数值等,而是直接将另一个Observable或数个当作数据源来建立新的Observable。 -
组合操作符会根据指定的条件将来源
original Observable的数据进行组合,变成一个新的Observable流
组合创建操作符
concat
Rxjs8 中将会使用
concatWith
concat可以将数个Observables组合成一个新的Observable,且在每个Observable结束后才续续下一个Observable,我们看一段代码:
const sourceA = of(1, 2);
const sourceB = of(3, 4);
const sourceC = of(5, 6);
如何希望sourceA跑完再跑sourceB接着最后跑sourceC,在不知道如何用operators的情况可能会这样写:
sourceA.subscribe({
next: data => console.log(data),
complete: () => sourceB.subscribe({
next: data => console.log(data),
complete: () => sourceC.subscribe({
next: data => console.log(data)
})
})
});
// 1
// 2
// 3
// 4
// 5
// 6
不用多说,相信同学们已经看出问题所在,这种深层次的嵌套,可以用concat来解救我们
concat(sourceA, sourceB, sourceC)
.subscribe(data => {
console.log(data);
});
执行结果是一样的,所有的Observable会依序执行,目前的Observable结束后再去执行下一个Observable
弹珠图:
sourceA: 1------2------|
sourceB: 3------4------|
sourceC: 5------6------|
concat(sourceA1, sourceB, source)
(sourceA) (sourceB) (sourceC)
1------2------3------4------5------6------|
^ 到这里sourceA 结束,接着下一个 sourceB
^ 到这里 sourceB 結束,接着下一个 sourceC
merge
merge跟concat类似,会同进启动参数内的所有的Observable,会有平行处理的感觉,看一段代码
const sourceA = interval(1000).pipe(map((data) => `A${++data}`));
const sourceB = interval(3000).pipe(map((data) => `B${++data}`));
const sourceC = interval(5000).pipe(map((data) => `C${++data}`));
merge(sourceA, sourceB, sourceC).subscribe((data) => {
console.log(`merge 示例 ${data}`);
});
// merge 示例 A1
// merge 示例 A2
// merge 示例 A3 (A3, B1 会同时发生)
// merge 示例 B1
// merge 示例 A4
// merge 示例 A5 (A5, C1 会同时发生)
// merge 示例 C1
// merge 示例 A6 (A6, B2 会同时发生)
// merge 示例 B2
先看弹珠图:
sourceA$: --A1--A2--A3--A4--A5--A6--....
sourceB$: ----------B1----------B2--...
sourceC$: ------------------C1------....
merge(sourceA, sourceB, sourceC)
--A1--A2--(A3,B1)--A4--(A5,C1)--(A6,B2)------.......
说明:
-
第1,2秒时,会产生
sourceA的A1和A2事件 -
第3秒时,
sourceA和sourceB分别发生了A3和B1事件 -
第4秒时,
sourceA产生A4事件 -
每5秒时,
sourceAt和sourceC分别发生了A5和C1事件 -
每6秒时,
sourceAt和sourceB分别发生了A6和B2事件 -
....
zip
zip翻译过来有拉链的意思,我们看下拉链的作用是把两个链条合并在一起。实际使用时,zip会将传入的Observable信次组合在一起成为一个组,已经被组合的就不会再次组合,看一段代码:
const sourceA = interval(1000).pipe(map((data) => `A${++data}`));
const sourceB = interval(2000).pipe(map((data) => `B${++data}`));
const sourceC = interval(3000).pipe(map((data) => `C${++data}`));
zip(sourceA, sourceB, sourceC).subscribe((data) => {
console.log(`zip 示例: ${data}`);
});
/**
zip 示例: A1,B1,C1
zip 示例: A2,B2,C2
zip 示例: A3,B3,C3
*/
先看弹珠图:
sourceA: --A1--A2--A3--A4--............
sourceB: ----B1 ----B2 ----B3--....
sourceC: ------C1 ------C2 ------C3......
zip(sourceA, sourceB, sourceC)
------** ------** ------**.......
[A1,B1,C1] [A2,B2,C2] [A3,B3,C3]
弹珠图刻意把时间拉开一些,同学们可以注意到合并的感觉是依照事件发生的次序进行合并的,也就是所有第一次生的事件合并成一组,所有第二次发生的事件合并成另外一组,依次类推
combineLatest
在未来的Rxjs8中将弃用,使用
combineLatestWith替换
combineLatest跟上面的zip很类似,差别在于
-
zip会依序组合,而combineLatest会在数据流有事件发生时,直接跟目前其他数据流的最后一个事件组合在一起,因此这个operator是latest结尾 -
comeintLatest的参数是一个数组,订阅后把数组内的这些Observable组合起来
const sourceA = interval(1000).pipe(map((data) => `A${++data}`));
const sourceB = interval(2000).pipe(map((data) => `B${++data}`));
const sourceC = interval(3000).pipe(map((data) => `C${++data}`));
combineLatest([sourceA, sourceB, sourceC]).subscribe((data) =>
console.log(`combineLatest 示例: ${data}`)
);
/*
combineLatest 示例: A3,B1,C1
combineLatest 示例: A4,B1,C1
combineLatest 示例: A4,B2,C1
combineLatest 示例: A5,B2,C1
combineLatest 示例: A6,B2,C1
combineLatest 示例: A6,B3,C1
combineLatest 示例: A6,B3,C2
*/
从结果可以看到每次有事件发生都会将其他Observable最后发生的事件组合起来,A1发生时,因为其他Observable还没有任何新的事件发生,因此没有办法组合,直到C1发生时,全部Observable都有最后一次事件产生时,才行组合。
弹珠图:
sourceA: --A1--A2--A3 --A4 --A5......
sourceB: ----B1 --B2 ....
sourceC: ------C1
zip(sourceA, sourceB, sourceC)
------** --** --**.......
[A3,B1,C1] [A4,B1,C1]
[A4,B2,C1]
forkJoin
forkJoin会同时订阅传入的Observables,直到每个Observable都结束后,将每个Observable的最后一个值组合起来。与Promise.all有点类似
import { interval, forkJoin } from "rxjs";
import { map, take } from "rxjs/operators";
const sourceA = interval(1000).pipe(
map((data) => `A${++data}`),
take(5)
);
const sourceB = interval(2000).pipe(
map((data) => `B${++data}`),
take(4)
);
const sourceC = interval(3000).pipe(
map((data) => `C${++data}`),
take(3)
);
forkJoin([sourceA, sourceB, sourceC]).subscribe({
next: (data) => console.log(`forkJoin 示例: ${data}`),
complete: () => console.log("forkJoin 结束"),
});
forkJoin([sourceA, sourceB, sourceC]).subscribe({
next: (data) => console.log(`forkJoin 示例: ${data}`),
complete: () => console.log("forkJoin 结束"),
});
//forkJoin 示例: A5,B4,C3
// forkJoin 结束
上面这段代码中,最后结束的是sourceC的C3,此时的sourceA和sourceB已经结束,事件值分别是A5和B4,因此最后订阅会得到一组[A5,B4,C3]然后结束
弹珠图:
sourceA: --A1--A2--A3--A4--A5|
sourceB: ----B1 ----B2 ----B3|
sourceC: ------C1 ------C2 ------C3|
forkJoin(sourceA, sourceB, sourceC)
------ ------ ------**|
[A5,B4,C3]
race
race单词翻译过来有竟速的意思。接受的参数一样是数个Observables。当订阅发生时,这些Observables会同时开跑,当其中一个Observable率先发生事件后,就会以这个Observable为主,并退订其他的Observables,也就是先到先赢。与Promise.race很类似
import {race} from 'rxjs'
const sourceA = interval(1000).pipe(map((data) => `A${++data}`));
const sourceB = interval(2000).pipe(map((data) => `B${++data}`));
const sourceC = interval(3000).pipe(map((data) => `C${++data}`));
race([sourceA, sourceB, sourceC]).subscribe((data) =>
console.log(`race 示例: ${data}`)
);
// race 示例: A1
// race 示例: A2
// race 示例: A3
// race 示例: A4
// race 示例: A5
// race 示例: A6
// race 示例: A7
// race 示例: A8
// race 示例: A9
// race 示例: A10
// 因为sourceA已经先到了,其他的Observables就退订不处理
弹珠图:
sourceA: --A1--A2--A3.....
sourceB: ----B1.........
sourceC: ------C1.....
race(sourceA, sourceB, sourceC)
--A1--A2--A3.....
^ sourceA先到,其它的全退订不处理
partition
上面三个concat,merge,zip都是将多个Observable组合成一个新的Observable,只是顺序和处理数据的方式不同,而partition则是将Observable按照规则拆成两个Observable,需要两个参数:
-
source: 来源 Observable
-
predicate:拆分的条件,是一个
function,每次事件发生都会将数据发送给这个function,判断符合条件会被归到一个observable,不符合条件的则被归到别一个Observable
const source = of(1, 2, 3, 4, 5, 6);
const [sourceEven, sourceOdd] = partition(
source,
(data) => data % 2 === 0
);
sourceEven.subscribe((data) =>
console.log(`partition 示范 (偶数): ${data}`)
);
sourceOdd.subscribe((data) =>
console.log(`partition 示范 (奇数): ${data}`)
);
/*
partition 示例 (偶数): 2
partition 示例 (偶数): 4
partition 示例 (偶数): 6
partition 示例 (奇数): 1
partition 示例 (奇数): 3
partition 示例 (奇数): 5
*/
弹珠图:
source: -----1-----2-----3-----4-----5-----6-----|
[sourceEven, sourceOdd] = partition(source, (data) => data % 2 === 0);
sourceEven: -----------2----------4------------6-----|
sourceOdd: -----1------------3----------5-----------|
But,这个有什么用呢?一般多数用于状态切换的管理,像登录和退出等(true/false)状态。如果我们希望两种状态有各自不同的场景处理时,partition就会很好用。
看一段伪代码
// 这种场景一般搭配Subject使用
const isLogin =()=> ....
const [login, logout] = partition(
isLogin,
(data) => data
);
login.subscribe(() => console.log('我又进来了!'));
logout.subscribe(() => console.log('我又出来了!'));
PS:用
filter也可以实现类似的效果,那么用partition好处是什么?
组合操作符
switchAll
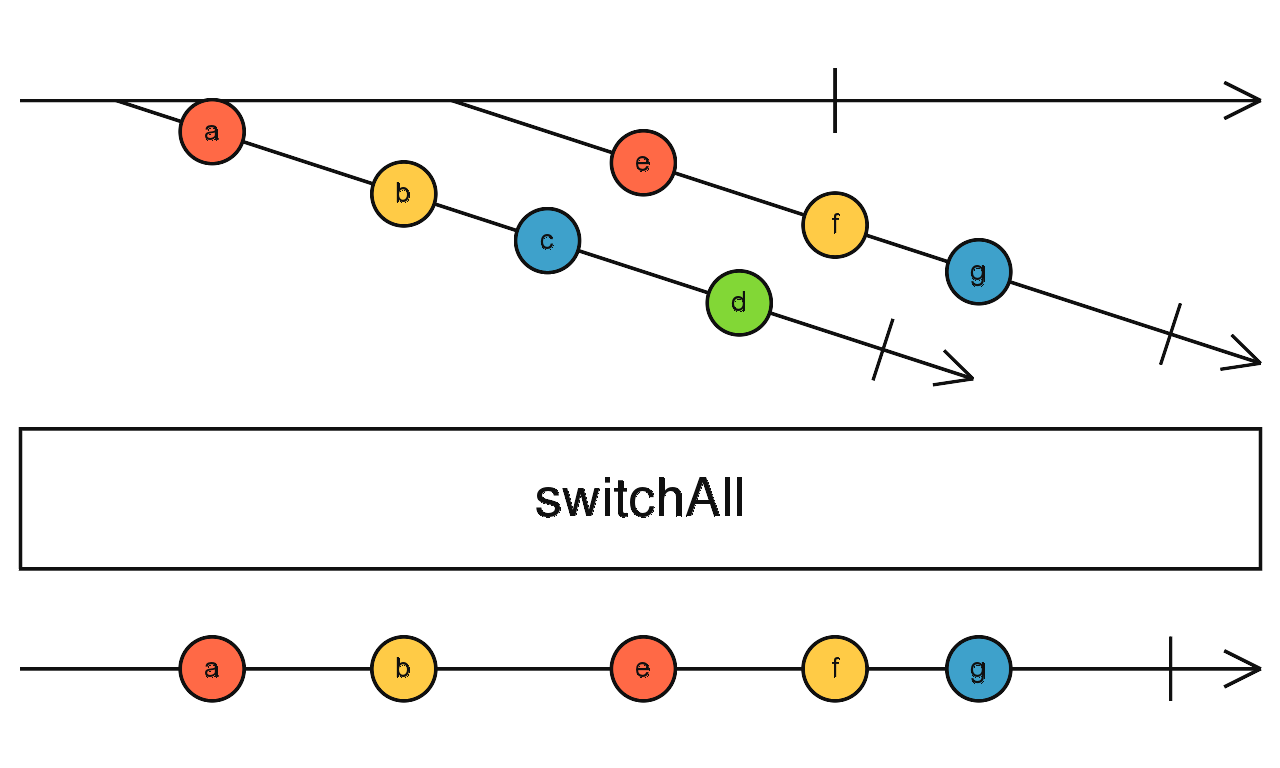
switchAll 与2.2章节提到的switchMap比较类似,是将来源事件的Observable转换成另一个Observable
import { timer,Subject } from "rxjs";
import { map, take } from "rxjs/operators";
const transformStreamToObservable = (round) =>
timer(0, 1000).pipe(
map((data) => `数据流 ${round}: ${++data}`),
take(3)
);
const subject = new Subject();
const stream = subject.pipe(map((round) => transformStreamToObservable(round)));
stream.pipe(switchAll()).subscribe((result) => console.log(result));
// 第一次事件
subject.next(1);
// 第二次事件
setTimeout(() => {
subject.next(2);
}, 4000);
// 第三次事件
setTimeout(() => {
subject.next(3);
}, 5000);
// 数据流 1: 1
// 数据流 1: 2
// 数据流 1: 3 第一次事件流1结束
// 数据流 2: 1 第二次事件流开始,产生事件流2
// 数据流 3: 1 事件流2还未结束,第三次事件开始了,产生事件流3
// 数据流 3: 2
// 数据流 3: 3
上面这段代码中,我们建立一个subject以便我们在想要的时间控制事件发生,而stream则是每次subject的事件转换成另外一个Observalbe流。
之后我们再将这个将数据转换成Observable流 transformStreamToObservable的Observable通过switchAll串在一起,switchAll会创建一个数据流,当每次收到一个Observable时,switchAll会帮我们订阅这个Observable,当这个Observable有新事件时,就让事件发在switchAll自行创建的数据流上;而订阅的Observable还没结束同时却收到一个要订阅的Observable时,就会将上一个Observable退订
这种也称为 Observable of Observable
弹珠图:
subject ---1-----------2--------------3|
map (a,b,c a,b,c a,b,c)
switchAll (a,b,c a,b a,b,c)
^事件3发生,退订原来的Observable
switchAll vs switchMap
switchMap会将callback function执行后返回的的Observable进行订阅,因此Observable的来源是从callback function 转变过来的
source.pipe(switchMap(data => of(data));
^这个callback就是switchMap订阅的数据来源
switchAll没有这个callback function,它的来源是从前一个数据流过来的,因此前一个数据流的数据必须是个Observable
source.pipe(
map(data => of(data)), 这里将数据转换成Observable
switchAll() // 订阅上一个operator传给我的Observable
);
因此switchMap合适用在明确知道下一步要使用哪个Observable的场景,由我们写的代码决定要转换成什么Observable;而switchAll适用在来源Observable不明确的场景。就拿上面和代码来说,stream可能是第三方库,我们只需要知道它的事件是一个Observable也就是Observable of Observable需要订阅。
switchAll与switchMap相同的地方在于,当收到新的Observable要订阅时,都会退订上一个Observable,因此可以确保永远都只有最后一个Observable正在执行
concatAll

concatAll与concatMap都会等待前一个Observable完成,在开始继续新的Observable数据流订阅,因此可以确保每个数据流都执行完成
const transformStreamToObservable = round =>
timer(0, 1000).pipe(
map(data => `数据流 ${round}: ${++data}`),
take(3)
);
const subject = new Subject();
const stream = subject.pipe(map(round => transformStreamToObservable(round)));
stream.pipe(concatAll())
.subscribe(result => console.log(result));
subject.next(1);
setTimeout(() => {
subject.next(2);
}, 4000);
setTimeout(() => {
subject.next(3);
}, 5000);
// 数据流 1: 1
// 数据流 1: 2
// 数据流 1: 3
// 数据流 2: 1
// 数据流 2: 2 此时第三次事件已经发生了,但数据流2还没结束,因此等待中
// 数据流 2: 3
// 数据流 3: 1 数据流2结束后 数据流3才开始
// 数据流 3: 2
// 数据流 3: 3
弹珠图:
subject --1-----------2--------------3|
map (a,b,c a,b,c a,b,c)
concatAll (a,b,c a,b,c,a,b,c)
^事件3发生,等待上一个Observable结束
mergeAll
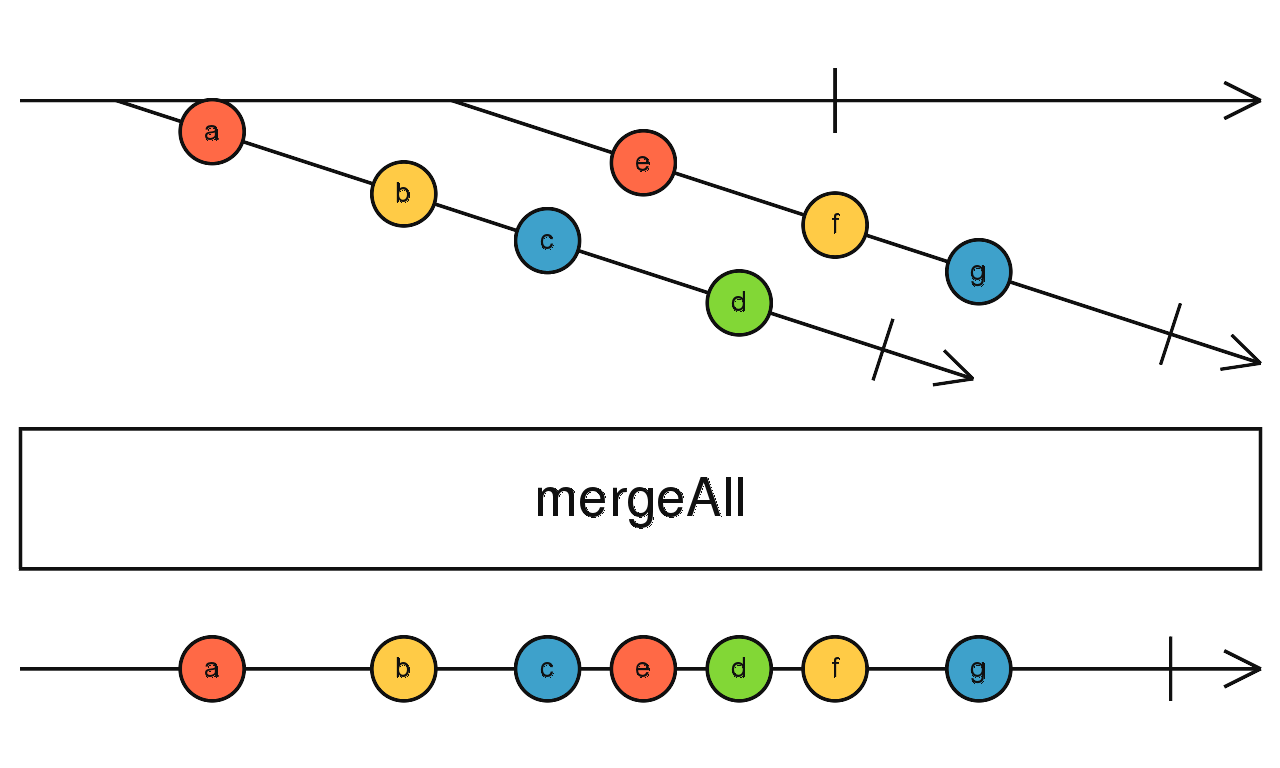
,mergeMap和mergeAll在得到新的数据流后会直接订阅,且不退订之前数据流,因此所有数据流会依照各自发生的时间直接的发生在mergeAll创建的数据流上
const transformStreamToObservable = round =>
timer(0, 1000).pipe(
map(data => `数据流 ${round}: ${++data}`),
take(3)
);
const subject = new Subject();
const stream = subject.pipe(map(round => transformStreamToObservable(round)));
stream.pipe(mergeAll())
.subscribe(result => console.log(result));
subject.next(1);
setTimeout(() => {
subject.next(2);
}, 2000);
setTimeout(() => {
subject.next(3);
}, 3000);
// 数据流 1: 1
// 数据流 1: 2
// 数据流 2: 1 第二次事件发生,产生数据充2,原来数据流不退订
// 数据流 1: 3 原來的数据流 1 在此结束
// 数据流 3: 1 第三次事件发生,产生数据流3,原來的数据流不退订
// 数据流 2: 2
// 数据流 3: 2
// 数据流 2: 3
// 数据流 3: 3
弹珠图:
subject ---1-----2--------3|
map (a,b,c a,b,c a,b,c)
mergeAll (a,b a,c bc,a,b,c)
^事件2发生,直接订阅新的数据流,旧的数据流未结束不能退订
combineAll
combineAll 和 combineLateset 很类似,都是把数据流的数据组合在一起,规则是每当有资料流产生新事件值时,将这个事件值和其他资料流最后一次事件组合起来
combineLateset要明确指定要组合哪些Observable,而combineAll则适用在来源不确的Observable of Observable的场景,因为来源并不明确,困此必须要等事个Observable结束。
const transformStreamToObservable = round =>
timer(0, 1000).pipe(
map(data => `数据流 ${round}: ${++data}`),
take(3)
);
const subject = new Subject();
const stream = subject.pipe(map(round => transformStreamToObservable(round)));
stream.pipe(combineAll())
.subscribe(result => console.log(result));
subject.next(1);
setTimeout(() => {
subject.next(2);
subject.complete();
}, 3000);
// ["数据流 1: 1", "数据流 2: 1"]
// ["数据流 1: 2", "数据流 2: 1"]
// ["数据流 1: 2", "数据流 2: 2"]
// ["数据流 1: 3", "数据流 2: 2"]
// ["数据流 1: 3", "数据流 2: 3"]
startWith
startWith会在一个Observable内加上一初始值,也就是订阅产生时会最先收到的一个值,2.2讲的pairwise时,会因为第一个事件值没有上一个事件值被忽略,改用scan来处理,如何使用startWith,会更简单
interval(1000).pipe(
take(6),
map(data => data + 1),
startWith(0), // 初始值
pairwise() // 再搭配 pairwise时,就能让原始的Observable的第一个事件有上一个事件
).subscribe(result => {
console.log(result);
});
弹珠图:
---1---2---3---4---5---6|
startWith(0)
0--1---2---3---4---5---6|
