

了解和优化应用程序的内存使用情况
作者:Chris Bailey 2012 年 2 月 29 日出版
尽管优化应用程序代码的内存使用的主题并不新鲜,但通常并不是一个很好理解的主题。本文简要介绍了 Java 进程的内存使用情况,然后深入探讨了您编写的 Java 代码的内存使用情况。最后,它展示了提高应用程序代码内存效率的方法,特别是在使用 Java 集合(如HashMaps 和ArrayLists)方面。
背景:Java 进程的内存使用情况
当您通过java在命令行上执行或通过启动一些基于 Java 的中间件来运行 Java 应用程序时,Java 运行时会创建一个操作系统进程 — 就像您正在运行基于 C 的程序一样。事实上,大多数 JVM 主要是用 C 或 C++ 编写的。作为操作系统进程,Java 运行时面临与任何其他进程相同的内存限制:体系结构提供的可寻址性以及操作系统提供的用户空间。
该架构提供的内存寻址能力取决于处理器的位大小——例如,32 位或 64 位,或在大型机的情况下为 31 位。进程可以处理的位数决定了处理器能够寻址的内存范围:32 位提供了 2^32 的可寻址范围,即 4,294,967,296 位或 4GB。64 位处理器的可寻址范围要大得多:2^64 是 18,446,744,073,709,551,616 或 16 艾字节。
推荐资源
处理器体系结构提供的一些可寻址范围被操作系统本身用于其内核和(对于用 C 或 C++ 编写的 JVM)用于 C 运行时。操作系统和 C 运行时使用的内存量取决于所使用的操作系统,但通常很重要:Windows 的默认使用量为 2GB。剩余的可寻址空间 — 称为用户空间— 是可供实际运行的进程使用的内存。
对于 Java 应用程序,用户空间是 Java 进程使用的内存,实际上由两个池组成:Java 堆和本机(非 Java)堆。Java 堆的大小由JVM 的Java 堆设置控制:-Xms并分别-Xmx设置最小和最大Java 堆。本机堆是在以最大大小设置分配 Java 堆后剩余的用户空间。图 1 显示了一个 32 位 Java 进程的示例:
图 1. 32 位 Java 进程的示例内存布局

在图 1 中,OS 和 C 运行时使用大约 4GB 可寻址范围中的 1GB,Java 堆使用近 2GB,本机堆使用其余部分。请注意,JVM 本身使用内存——与操作系统内核和 C 运行时使用的方式相同——并且 JVM 使用的内存是本机堆的子集。
Java 对象剖析
当您的 Java 代码使用new运算符创建 Java 对象的实例时,分配的数据比您预期的要多得多。例如,您可能会惊讶地发现,一个int值与一个Integer对象(可以容纳一个int值的最小对象)的大小比通常是 1:4。额外的开销是 JVM 用来描述 Java 对象的元数据,在本例中为Integer.
对象元数据的数量因 JVM 版本和供应商而异,但通常包括:
- Class:指向类信息的指针,它描述了对象类型。
java.lang.Integer例如,在对象的情况下,这是指向java.lang.Integer类的指针。 - Flags:一组描述对象状态的标志,包括对象的哈希码(如果有的话)和对象的形状(即对象是否是数组)。
- Lock:对象的同步信息——即对象当前是否同步。
对象元数据之后是对象数据本身,由存储在对象实例中的字段组成。在java.lang.Integer对象的情况下,这是单个int.
因此,当您java.lang.Integer在运行 32 位 JVM时创建对象的实例时,对象的布局可能如图 2 所示:
图 2. java.lang.Integer32 位 Java 进程的对象布局示例

正如图2所示,128位数据用于存储在所述数据的32位int值,因为对象元数据使用这些128位的其余部分。
Java 数组对象剖析
数组对象(例如int值数组)的形状和结构类似于标准 Java 对象的形状和结构。主要区别在于数组对象有一个额外的元数据,用于表示数组的大小。那么,数组对象的元数据包括:
- Class:指向类信息的指针,它描述了对象类型。在
int字段数组的情况下,这是指向int[]类的指针。 - Flags:一组描述对象状态的标志,包括对象的哈希码(如果有的话)和对象的形状(即对象是否是数组)。
- Lock:对象的同步信息——即对象当前是否同步。
- 大小:数组的大小。
图 3 显示了一个int数组对象的示例布局:
图 3. int32 位 Java 进程的数组对象布局示例

在图 3 中,160 位数据将 32 位数据存储在int值中,因为数组元数据使用其余 160 位。对于基元如byte,int,和long,单条目阵列是在存储器比相应的包装对象(而言更昂贵Byte,Integer或Long)为单字段。
更复杂的数据结构剖析
良好的面向对象设计和编程鼓励使用封装(提供控制数据访问的接口类)和委托(使用辅助对象来执行任务)。封装和委托导致大多数数据结构的表示涉及多个对象。一个简单的例子是一个java.lang.String对象。java.lang.String对象中的数据是一个字符数组,由一个java.lang.String对象封装,该对象管理和控制对字符数组的访问。java.lang.String32 位 Java 进程的对象布局可能如图 4 所示:
图 4. java.lang.String32 位 Java 进程的对象布局示例
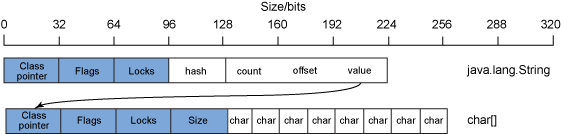
正如图4所示,一个java.lang.String对象包含-除了标准的对象元数据-某些字段来管理字符串数据。通常,这些字段是哈希值、字符串大小的计数、字符串数据的偏移量以及对字符数组本身的对象引用。
这意味着要有一个 8 个字符的字符串(128 位char数据),256 位数据用于字符数组,224 位数据用于java.lang.String管理它的对象,总共 480 位(60 字节)表示 128 位(16 字节)的数据。这是 3.75:1 的开销比率。
一般来说,数据结构越复杂,其开销就越大。这将在下一节中更详细地讨论。
32位 和 64 位 Java 对象
前面示例中对象的大小和开销适用于 32 位 Java 进程。正如您从背景:Java 进程的内存使用部分中了解到的那样,64 位处理器比 32 位处理器具有更高级别的内存寻址能力。对于 64 位进程,Java 对象中某些数据字段的大小——特别是对象元数据和任何引用另一个对象的字段——也需要增加到 64 位。其他数据字段类型-例如int,byte和long-不改变大小。图 5 显示了 64 位Integer对象和int数组的布局:
图 5. 64 位 Java 进程的java.lang.Integer对象和int数组的示例布局
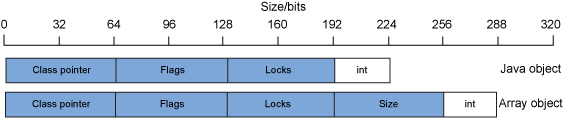
图 5显示,对于 64 位Integer对象,现在使用 224 位数据来存储用于int字段的 32 位— 开销比为 7:1。对于 64 位单元素int数组,288 位数据用于存储 32 位int条目 — 开销为 9:1。这对实际应用程序的影响是,以前在 32 位 Java 运行时上运行的应用程序的 Java 堆内存使用量在迁移到 64 位 Java 运行时时显着增加。通常,增加量约为原始堆大小的 70%。例如,使用 1GB Java 堆和 32 位 Java 运行时的 Java 应用程序通常将使用 1.7GB 的 Java 堆和 64 位 Java 运行时。
请注意,这种内存增加不仅限于 Java 堆。本机堆内存区域使用量也会增加,有时会增加 90%。
表 1 显示了应用程序在 32 位和 64 位模式下运行时对象和数组的字段大小:
表 1. 32 位和 64 位 Java 运行时对象中的字段大小 {: #table-1-field-sizes-in-objects-for-32-bit-and-64-bit-java-runtimes}
字段TYPEFIELD大小(比特)ObjectArray32-bit64-bit32-bit64位boolean323288 byte323288 char32321616 short32321616 int32323232 float32323232 long64646464 double64646464Object fields3264(32 )3264(32)对象metadata3264(32 )3264(32)
*用于每个对象元数据条目的对象字段和数据的大小可以通过压缩引用和压缩普通对象指针 (OOP)技术减少到 32 位。
压缩引用和压缩普通对象指针 (OOP)
IBM 和 Oracle JVM 分别通过 Compressed References ( -Xcompressedrefs) 和 Compressed OOPs ( -XX:+UseCompressedOops) 选项提供对象引用压缩功能。使用这些选项使对象字段和对象元数据值能够以 32 位而不是 64 位存储。当应用程序从 32 位 Java 运行时移动到 64 位 Java 运行时,这会抵消 70% 的 Java 堆内存增加。请注意,这些选项对本机堆的内存使用没有影响;64 位 Java 运行时比 32 位 Java 运行时更高。
Java 集合的内存使用
在大多数应用程序中,使用作为核心 Java API 一部分提供的标准 Java Collections 类来存储和管理大量数据。如果内存占用优化对您的应用程序很重要,那么了解每个集合提供的功能和相关的内存开销尤其有用。通常,集合的功能级别越高,其内存开销就越大——因此使用提供比您需要的功能更多的集合类型将导致不必要的额外内存开销。
一些常用的集合是:
除了HashSet,此列表按函数和内存开销的递减顺序排列。( A HashSet,作为HashMap对象的包装器,有效地提供的功能比HashMap稍微大一点的功能要少。)
Java集合: HashSet
AHashSet是Set接口的实现。Java Platform SE 6 API 文档描述HashSet如下:
不包含重复元素的集合。更正式地说,集合不包含一对元素 e1 和 e2,使得 e1.equals(e2),并且最多包含一个空元素。正如其名称所暗示的那样,该接口对数学集合抽象进行建模。
AHashSet的功能比 a 少HashMap,因为它不能包含多个空条目并且不能有重复的条目。该实现是围绕 a 的包装器HashMap,HashSet对象管理允许放入HashMap对象的内容。限制 a 能力的附加功能HashMap意味着HashSets 具有稍高的内存开销。
图 6 显示HashSet了 32 位 Java 运行时上的布局和内存使用情况:
图 6. HashSet32 位 Java 运行时的内存使用和布局

图 6显示了以字节为单位的浅堆(单个对象的内存使用情况),以及一个对象的保留堆(单个对象及其子对象的内存使用情况)(以字节为单位)java.util.HashSet。浅堆大小为 16 字节,保留堆大小为 144 字节。当HashSet被创建,其默认容量-可以放入组条目的数量-为16个条目。当 aHashSet以默认容量创建并且没有条目放入集合时,它占用 144 字节。这比HashMap. 表 2 显示了 a 的属性HashSet:
表 2. HashSet{: #table-2-attributes-of-a-code-hashset-code} 的属性
AttributeDescription默认容量16个条目空大小144字节HashMap开销16字节加上开销开销10K集合的HashMap开销16字节加上开销搜索/插入/删除性能O(1)——所用时间是常数时间,与元素数量无关(假设没有散列冲突)
Java集合: HashMap
AHashMap是Map接口的实现。Java Platform SE 6 API 文档描述HashMap如下:
将键映射到值的对象。地图不能包含重复的键;每个键最多可以映射到一个值。
HashMap提供了一种存储键/值对的方法,使用散列函数将键转换为索引到存储键/值对的集合中。这允许快速访问数据位置。允许空条目和重复条目;因此, aHashMap是 a 的简化HashSet。
a 的实现是一个对象HashMap数组HashMap$Entry。图 7 显示HashMap了 32 位 Java 运行时的内存使用情况和布局:
图 7. HashMap32 位 Java 运行时的内存使用和布局

正如图7所示,一个当HashMap被创建时,结果是一个HashMap对象,并且阵列HashMap$Entry在其16个条目的默认容量对象。HashMap当它完全为空时,这给出了128 字节的大小。插入到 中的任何键/值对HashMap都由一个HashMap$Entry对象包装,该对象本身有一些开销。
大多数HashMap$Entry对象的实现都包含以下字段:
int KeyHashObject nextObject keyObject value
一个 32 字节的HashMap$Entry对象管理放入集合中的数据的键/值对。这意味着 a 的总开销HashMap包括HashMap对象、HashMap$Entry数组条目和HashMap$Entry每个条目的对象。这可以用以下公式表示:
HashMap对象 + 数组对象开销 +(条目数 *(HashMap$Entry数组条目 +HashMap$Entry对象))
对于 10,000 个条目HashMap,仅HashMap、HashMap$Entry数组和HashMap$Entry对象的开销大约为 360K。这是在考虑存储的键和值的大小之前。
表 3 显示了HashMap的属性:
表 3. HashMap{: #table-3-attributes-of-a-code-hashmap-code} 的属性
AttributeDescriptionDefault capacity16 entriesEmpty size128 bytesOverhead64 bytes plus 36 bytes per entry Overhead for a 10K collection~360KSearch/insert/delete performanceO(1) — 花费的时间是常数时间,与元素数量无关(假设没有哈希冲突)
Java集合: Hashtable
Hashtable,如HashMap,是Map接口的实现。Java Platform SE 6 API 文档的描述Hashtable是:
这个类实现了一个哈希表,它将键映射到值。任何非空对象都可以用作键或值。
Hashtable与 非常相似HashMap,但它有两个限制。它不能接受键或值条目的空值,并且它是一个同步集合。相反,HashMap可以接受空值并且不同步但可以使用该Collections.synchronizedMap()方法进行同步。
的实现Hashtable- 也类似于HashMap's - 作为入口对象的数组,在这种情况下是Hashtable$Entry对象。图 8 显示Hashtable了 32 位 Java 运行时的内存使用情况和布局:
图 8. Hashtable32 位 Java 运行时的内存使用和布局

图 8显示,当 aHashtable创建时,结果是一个Hashtable使用 40 字节内存的对象以及Hashtable$entry一个默认容量为 11 个条目的s数组,对于空的 总大小为 104 字节Hashtable。
Hashtable$Entry有效地存储与以下相同的数据HashMap:
int KeyHashObject nextObject keyObject value
这意味着Hashtable$Entry对象也是 32 字节的键/值条目,10K 条目集合(约 360K)的开销和大小Hashtable的计算Hashtable与 的类似HashMap。
表 4 显示了 a 的属性Hashtable:
表 4. Hashtable{: #table-4-attributes-of-a-code-hashtable-code} 的属性
AttributeDescriptionDefault capacity11 entriesEmpty size104 bytesOverhead56 bytes plus 36 bytes per entry Overhead for a 10K collection~360KSearch/insert/delete performanceO(1) — 所用时间是常数时间,与元素数量无关(假设没有散列冲突)
如您所见,Hashtable默认容量比HashMap(11 对 16)略小。否则,主要区别在于Hashtable无法接受空键和值,以及它的默认同步,这可能不需要并降低集合的性能。
Java集合: LinkedList
ALinkedList是List接口的链表实现。Java Platform SE 6 API 文档描述LinkedList如下:
有序集合(也称为序列)。此界面的用户可以精确控制每个元素在列表中的插入位置。用户可以通过它们的整数索引(在列表中的位置)访问元素,并在列表中搜索元素。与集合不同,列表通常允许重复元素。
实现是一个LinkedList$Entry对象的链表。图 9 显示LinkedList了 32 位 Java 运行时的内存使用情况和布局:
图 9. LinkedList32 位 Java 运行时的内存使用和布局

图 9显示,当LinkedList创建a 时,结果是一个LinkedList使用 24 字节内存的LinkedList$Entry对象和一个对象,总共 48 字节的内存用于空的LinkedList.
链表的优点之一是它们的大小准确,不需要调整大小。默认容量实际上是一个条目,并且随着添加或删除更多条目而动态增长和缩小。每个LinkedList$Entry对象仍然有开销,其数据字段为:
Object previousObject nextObject value
但这比HashMaps 和Hashtables的开销要小,因为链表只存储单个条目而不是键/值对,并且不需要存储哈希值,因为不使用基于数组的查找。不利的一面是,查找链表可能会慢得多,因为必须遍历链表才能找到正确的条目。对于大型链表,这可能会导致较长的查找时间。
表 5 显示了 a 的属性LinkedList:
表 5. LinkedList{: #table-5-attributes-of-a-code-linkedlist-code} 的属性
AttributeDescriptionDefault capacity1 entryEmpty size48 bytesOverhead24 bytes, plus 24 bytes per entry Overhead for a 10K collection~240KSearch/insert/delete performanceO(n) - 所用时间线性依赖于元素的数量
Java集合: ArrayList
AnArrayList是List接口的可调整大小的数组实现。Java Platform SE 6 API 文档描述ArrayList如下:
有序集合(也称为序列)。此界面的用户可以精确控制每个元素在列表中的插入位置。用户可以通过它们的整数索引(在列表中的位置)访问元素,并在列表中搜索元素。与集合不同,列表通常允许重复元素。
与LinkedList,ArrayList是使用Objects数组实现的。图 10 显示ArrayList了 32 位 Java 运行时的内存使用情况和布局:
图 10. ArrayList32 位 Java 运行时的内存使用和布局

图 10显示,当ArrayList创建an 时,结果是一个ArrayList使用 32 字节内存的对象,以及Object一个默认大小为 10的数组,总共 88 字节的内存为空。ArrayList这意味着该对象的ArrayList大小不准确,因此有默认容量,恰好是 10 个条目。
表 6 显示了 的属性ArrayList:
表 6. ArrayList{: #table-6-attributes-of-an-code-arraylist-code} 的属性
AttributeDescriptionDefault capacity10Empty size88 bytesOverhead48 bytes plus 4 bytes per entry Overhead for 10K collection~40KSearch/insert/delete performanceO(n) — 所用时间与元素数量线性相关
其他类型的“集合”
除了标准集合之外,StringBuffer也可以认为是一个集合,因为它管理字符数据并且在结构和功能上与其他集合相似。Java Platform SE 6 API 文档描述StringBuffer如下:
一个线程安全的、可变的字符序列...... 每个字符串缓冲区都有一个容量。只要字符串缓冲区中包含的字符序列的长度不超过容量,就不需要分配新的内部缓冲区数组。如果内部缓冲区溢出,它会自动变大。
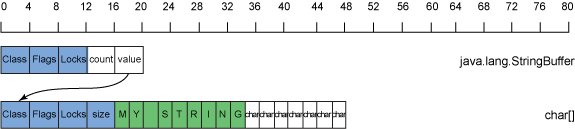
a 的实现StringBuffer是作为chars的数组。图 11 显示StringBuffer了 32 位 Java 运行时的内存使用情况和布局:
图 11. StringBuffer32 位 Java 运行时的内存使用和布局

图 11显示,当 aStringBuffer创建时,结果是一个StringBuffer使用 24 字节内存的对象,以及一个默认大小为 16 的字符数组,一个空的 总共有 72 字节的数据StringBuffer。
与集合一样,StringBuffer具有默认容量和调整大小的机制。表 7 显示了 的属性StringBuffer:
表 7. StringBuffer{: #table-7-attributes-of-a-code-stringbuffer-code} 的属性
AttributeDescriptionDefault capacity16Empty size72 bytesOverhead24 bytesOverhead for 10K collection24 bytesSearch/Insert/Delete performanceNA
集合中的空白空间
具有给定数量对象的各种集合的开销并不是整个内存开销故事。前面示例中的测量假定集合的大小已准确。但是对于大多数集合来说,这不太可能是真的。大多数集合都是使用给定的初始容量创建的,并且数据被放入集合中。这意味着集合的容量通常大于集合中存储的数据,这会带来额外的开销。
考虑 a 的示例StringBuffer。其默认容量为 16 个字符条目,大小为 72 字节。最初,这 72 个字节中没有存储任何数据。例如,如果您将一些字符放入字符数组中,"MY STRING"那么您将在 16 个字符的数组中存储 9 个字符。图 12 显示了 32 位 Java 运行时中StringBuffer包含的内存使用情况"MY STRING":
图 12. 一个StringBuffer包含"MY STRING"在 32 位 Java 运行时上的内存使用
正如图12所示,在不使用阵列中可用的7级额外字符的项,但正在消耗存储器-在这种情况下为112个字节的附加开销。对于此集合,您有 9 个条目,容量为 16,这为您提供了 0.56的填充率。集合的填充率越低,备用容量导致的开销就越大。
集合的扩展和调整大小
在集合达到其容量并请求将其他条目放入集合后,该集合将调整大小并扩展以容纳新条目。这会增加容量,但通常会降低填充率并引入更大的内存开销。
使用的扩展算法因集合而异,但常见的方法是将集合的容量加倍。这是为StringBuffer. 在前面示例的 的情况下StringBuffer,如果您想附加" OF TEXT"到缓冲区以产生"MY STRING OF TEXT",则需要扩展集合,因为您的新字符集合有 17 个条目,而当前容量为 16。图 13 显示了结果内存使用情况:
图 13. 一个StringBuffer包含"MY STRING OF TEXT"在 32 位 Java 运行时上的内存使用
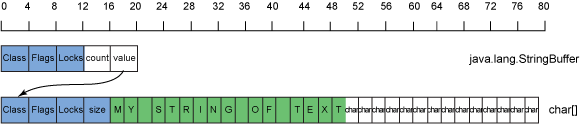
现在,如图 13所示,您有一个 32 个条目的字符数组和 17 个使用的条目,填充率为 0.53。填充率没有显着下降,但您现在有 240 字节的备用容量开销。
在小字符串和集合的情况下,低填充率和备用容量的开销似乎不是太大的问题,但在更大的大小时它们变得更加明显和昂贵。例如,如果您创建一个StringBuffer仅包含 16MB 数据的文件,它将(默认情况下)使用一个字符数组,该数组的大小可容纳多达 32MB 的数据 — 以备用容量的形式创建 16MB 的额外开销。
Java 集合:总结
表 8 总结了集合的属性:
表 8. 集合属性汇总
| 收藏 | 表现 | 默认容量 | 空号 | 10K 条目开销 | 尺寸准确吗? | 扩展算法 |
|---|---|---|---|---|---|---|
HashSet | O(1) | 16 | 144 | 360K | 不 | x2 |
HashMap | O(1) | 16 | 128 | 360K | 不 | x2 |
Hashtable | O(1) | 11 | 104 | 360K | 不 | x2+1 |
LinkedList | 在) | 1 | 48 | 240K | 是的 | +1 |
ArrayList | 在) | 10 | 88 | 40K | 不 | x1.5 |
StringBuffer | O(1) | 16 | 72 | 24 | 不 | x2 |
Hash集合的性能比任何List一个都好得多,但每次输入的成本要高得多。由于访问性能,如果您正在创建大型集合(例如,要实现缓存),最好使用Hash基于集合的集合,而不管额外的开销。
对于访问性能不是问题的较小集合,Lists 成为一种选择。ArrayList和LinkedList集合的性能大致相同,但它们的内存占用不同:每个条目的大小ArrayList比 小得多LinkedList,但大小不准确。anArrayList或 aLinkedList是否是Listto use的正确实现取决于 the 的长度的可预测性List。如果长度未知,aLinkedList可能是正确的选项,因为集合将包含较少的空白空间。如果大小已知,ArrayList则内存开销会少得多。
选择正确的集合类型使您能够在集合性能和内存占用之间选择正确的平衡点。此外,您可以通过正确调整集合大小来最大限度地减少内存占用,以最大限度地提高填充率并最大限度地减少未使用的空间。
使用中的集合:PlantsByWebSphere 和 WebSphere Application Server Version 7
在表 8 中,创建一个Hash基于10,000 个条目的集合的开销显示为 360K。考虑到复杂的 Java 应用程序运行以 GB 为单位的 Java 堆的情况并不少见,这似乎不是一个很大的开销——当然,除非正在使用大量集合。
表 9 显示了当 WebSphere® Application Server 版本 7 提供的 PlantsByWebSphere 示例应用程序在五用户负载测试下运行时,作为 206MB Java 堆使用量的一部分的集合对象使用情况:
表 9. PlantsByWebSphere 在 WebSphere Application Server v7 上的集合使用情况
| 收藏类型 | 实例数 | 总收集开销 (MB) |
|---|---|---|
Hashtable | 262,234 | 26.5 |
WeakHashMap | 19,562 | 12.6 |
HashMap | 10,600 | 2.3 |
ArrayList | 9,530 | 0.3 |
HashSet | 1,551 | 1.0 |
Vector | 1,271 | 0.04 |
LinkedList | 1,148 | 0.1 |
TreeMap | 299 | 0.03 |
| 全部的 | 306,195 | 42.9 |
您可以从表 9中看到,正在使用超过 300,000 个不同的集合——并且集合本身,不计算它们包含的数据,占 206MB Java 堆使用量的 42.9MB(21%)。这意味着如果您更改集合类型或确保集合的大小更准确,则可以节省大量潜在的内存。
使用内存分析器寻找低填充率
IBM Monitoring and Diagnostic Tools for Java – Memory Analyzer 工具(Memory Analyzer)作为 IBM Support Assistant 的一部分提供,可以分析 Java 集合的内存使用情况(参见 参考资料)。它的功能包括分析填充率和集合大小。您可以使用此分析来识别任何可以优化的集合。
Memory Analyzer 中的集合分析功能位于 Open Query Browser -> Java Collections 菜单下,如图 14 所示:
图 14. Memory Analyzer 中 Java 集合的填充率分析
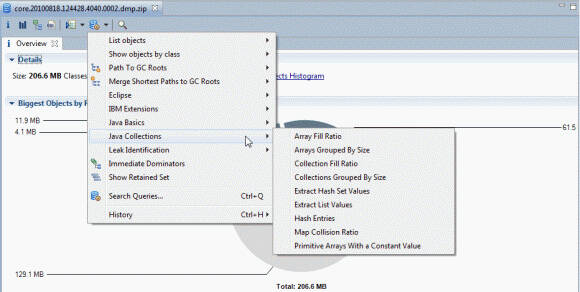
图 14 中选择的 Collection Fill Ratio 查询对于识别比当前所需的集合大得多的集合最有用。您可以为此查询指定许多选项,包括:
- objects:您感兴趣的对象(集合)的类型
- segment:将对象分组到的填充率范围
在对象选项设置为“java.util.Hashtable”且段选项设置为“10”的情况下运行查询会产生如图 15 所示的输出:
图 15. 在 Memory Analyzer 中对Hashtables的填充率进行分析
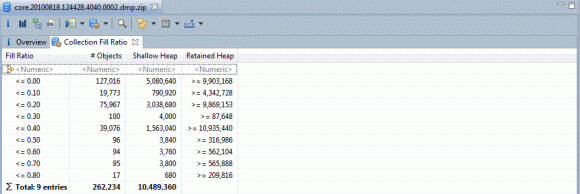
图 15显示,在 262,234 个实例中java.util.Hashtable,其中 127,016 个(48.4%)完全为空,并且几乎所有实例都只有少量条目。
这则可以通过选择结果表和右键单击的行选择,以确定这些集合对象列表- >与传入引用,看看哪些对象自己的集合或列表对象- >即将离任的引用,看看里面是什么的集合。图 16 显示了查看空Hashtables的传入引用并展开几个条目的结果:
图 16.Hashtable在 Memory Analyzer 中分析对空s的传入引用
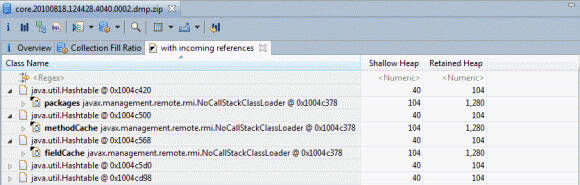
图 16 显示了一些空Hashtables 归javax.management.remote.rmi.NoCallStackClassLoader代码所有。
通过查看 Memory Analyzer 左侧面板中的Attributes视图,您可以看到有关其Hashtable自身的特定详细信息,如图 17 所示:
图 17.Hashtable在 Memory Analyzer 中检查空

图 3显示Hashtable的大小为 11(默认大小)并且完全为空。
对于javax.management.remote.rmi.NoCallStackClassLoader代码,可以通过以下方式优化集合使用:
- 延迟分配
Hashtable: 如果 为Hashtable空的情况很常见,那么Hashtable只有在其中存储数据时才分配可能是有意义的。 - 分配
Hashtable到一个准确的大小:因为已经使用了默认大小,所以可以使用更准确的初始大小。
这些优化中的一个或两个是否适用取决于代码的常用方式以及其中通常存储的数据。
PlantsByWebSphere 示例中的空集合
表 10 显示了分析 PlantsByWebSphere 示例中的集合以识别空集合的结果:
表 10. PlantsByWebSphere 在 WebSphere Application Server v7 上的 Empty-collection 使用
| 收藏类型 | 实例数 | 空实例 | % 空的 |
|---|---|---|---|
Hashtable | 262,234 | 127,016 | 48.4 |
WeakHashMap | 19,562 | 19,465 | 99.5 |
HashMap | 10,600 | 7,599 | 71.7 |
ArrayList | 9,530 | 4,588 | 48.1 |
HashSet | 1,551 | 866 | 55.8 |
Vector | 1,271 | 622 | 48.9 |
| 全部的 | 304,748 | 160,156 | 52.6 |
表 10显示,平均而言,超过 50% 的集合是空的,这意味着可以通过优化集合使用来节省大量内存占用。它可以应用于应用程序的各个级别:在 PlantsByWebSphere 示例代码中、在 WebSphere Application Server 中以及在 Java 集合类本身中。
在 WebSphere Application Server 版本 7 和版本 8 之间,已经做了一些工作来提高 Java 集合和中间件层的内存效率。例如,实例的很大一部分开销java.util.WeahHashMap是由于它包含一个实例java.lang.ref.ReferenceQueue来处理弱引用。图 18 显示WeakHashMap了 32 位 Java 运行时的内存布局:
图 18. WeakHashMap32 位 Java 运行时的内存布局
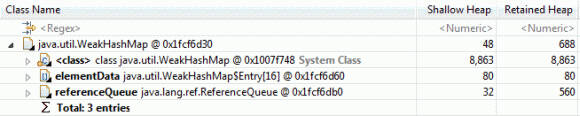
图 18显示该ReferenceQueue对象负责保留 560 字节的数据,即使它WeakHashMap是空的,ReferenceQueue因此不需要。对于具有 19,465 个空WeakHashMaps的 PlantsByWebSphere 示例案例,ReferenceQueue对象添加了额外的 10.9MB 不需要的数据。在 WebSphere Application Server 版本 8 和 IBM Java 运行时的 Java 7 版本中,WeakHashMap已经进行了一些优化:它包含一个ReferenceQueue,而后者又包含一个Reference对象数组。该数组已更改为延迟分配 - 也就是说,仅当对象添加到ReferenceQueue.
结论
任何给定的应用程序中都存在数量庞大且可能令人惊讶的集合,对于复杂的应用程序更是如此。使用大量集合通常可以通过选择正确的集合、正确调整其大小以及可能通过延迟分配来实现有时显着的内存占用节省。这些决定最好在设计和开发期间做出,但您也可以使用内存分析器工具来分析现有应用程序,以优化潜在的内存占用。
