参考网址
zhuanlan.zhihu.com/p/26122044
1/过拟合
<1>什么是过拟合
过拟合就是模型在训练集上效果很好(训练误差很小),但是在验证集(validation data)上效果较差的一种现象,及泛化能力差。
可以理解为把训练数据学得太好了,什么都学到了,细枝末节都学习到了。
但是拿到测试数据集中就歇菜了,泛化能力太差了。
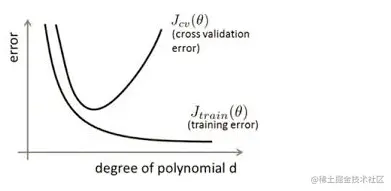
下图给出例子:

我们将上图第三个模型解释为出现了过拟合现象,过度的拟合了训练数据,而没有考虑到泛化能力。
在训练集上的准确率和在开发集上的准确率画在一个图上如下:
<2>过拟合产生的原因
<1>训练数据中有`噪声数据`
模型把噪声数据也当作正常的数据来训练了。
噪声数据把模型‘带跑偏了’
<2>训练数据不足(不能覆盖实际上所有的数据情况)
所以如果测试集中有一些训练集中没有的数据,那么可能效果就会不好。
<3>训练模型过度复杂
(1)训练数据有噪声
为什么数据有噪声,就可能导致模型出现过拟合现象呢?
所有的机器学习过程都是一个search假设空间的过程!
我们是在模型参数空间搜索一组参数,使得我们的损失函数最小,也就是不断的接近我们的真实假设模型,而真实模型只有知道了所有的数据分布,才能得到。
往往我们的模型是在训练数据有限的情况下,找出使损失函数最小的最优模型,然后将该模型泛化于所有数据的其它部分。这是机器学习的本质!
那好,假设我们的总体数据如下图所示:
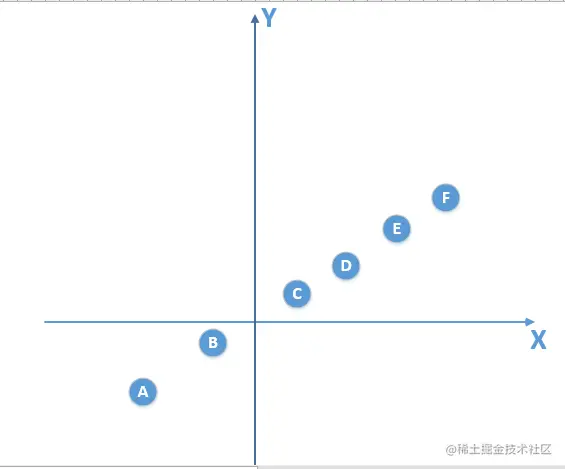
我这里假设总体数据分布满足一个线性模型y = kx+b,现实中肯定不会这么简单,数据量也不会这么少,至少也是多少亿级别,但是不影响解释。反正总体数据满足模型y。
此时我们得到的部分数据,还有噪声的话,如下图所所示,红色点是噪声数据点。
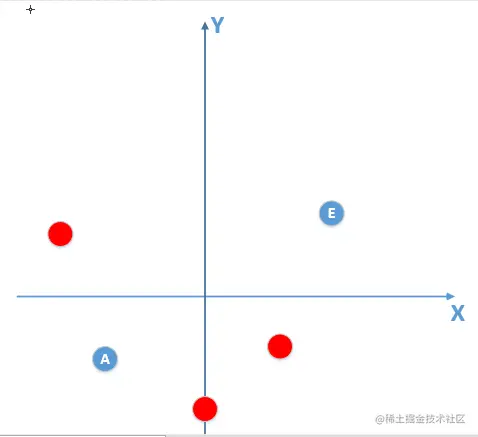
那么由上面训练数据点训练出来的模型肯定不是线性模型(**总体数据分布下满足的标准模型**),
比如训练出来的模型如下:
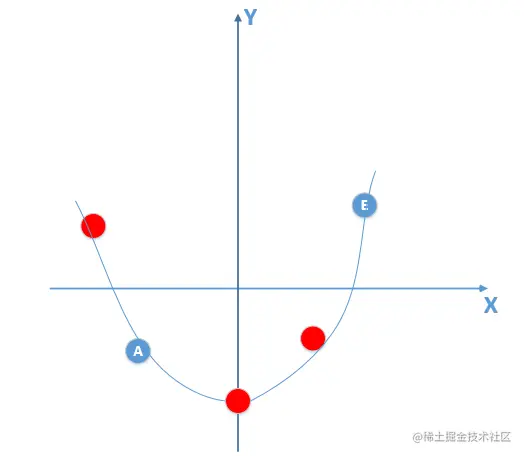
那么我拿着这个有噪声数据的训练数据集通过不断训练,可以做到损失函数值为0。
但是拿着这个模型,到真实总体数据分布中(满足线性模型)去泛化,效果会非常差,
因为你拿着一个非线性模型去预测线性模型的真实分布,显而易得效果是非常差的,也就产生了过拟合现象!
(2)训练数据不足
当我们训练数据不足的时候,即使训练数据中没有噪声,训练出来的模型也可能产生过拟合现象,解释如下:
假设我们的总体数据分布如下:
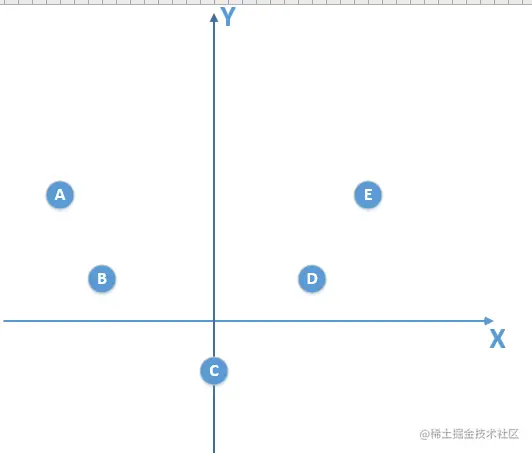
我们得到的训练数据由于是有限的,比如是下面这个:
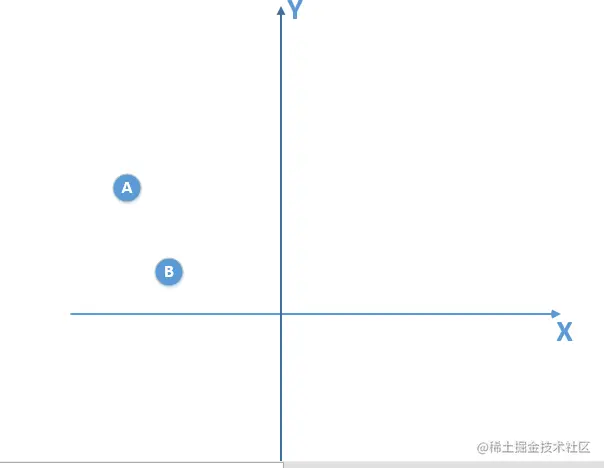
我只得到了A,B俩个训练数据,
那么由这个训练数据,我得到的模型是一个线性模型,通过训练较多的次数,我可以得到在训练数据使得损失函数为0的线性模型,拿这个模型我去泛化真实的总体分布数据(实际上是满足二次函数模型),很显然,泛化能力是非常差的,也就出现了过拟合现象!
(3)训练模型过度导致模型非常复杂
训练模型过度导致模型非常复杂,也会导致过拟合现象!
这点和第一点俩点原因结合起来其实非常好理解,当我们在训练数据训练的时候,如果训练过度,导致完全拟合了训练数据的话,得到的模型不一定是可靠的。
比如说,在有噪声的训练数据中,我们要是训练过度,会让模型学习到噪声的特征,无疑是会造成在没有噪声的真实测试集上准确率下降!
<3>如何解决过拟合
(1)如果是噪声数据导致的,
那么可以提前先对数据进行预处理,删除噪声数据
(2)如果是训练数据不足导致的,
那么可以增加训练数据的比例,让模型「看见」尽可能多的「例外情况」。
增加能代表实际数据情况的数据,尽可能覆盖实际中的所有数据情况。
这样模型就会不断修正自己,从而得到更好的训练结果。
(3)如果是模型过于复杂导致的,
可以采用一定的办法降低模型的复杂度。
例如,在神经网络模型中减少网络层数、神经元个数等;
在决策树模型中降低树的深度,进行剪枝,控制叶子节点的个数,以及叶子节点中样本数据的权重等。
2/欠拟合
<1>什么是欠拟合
欠拟合指的是模型在训练数据集和测试数据集上表现都不好的情况。
在训练集上效果不好,那么在测试集上肯定不会好。
<2>欠拟合产生的原因
<1>特征不足,或者特征不够有代表性/区分性,特征feature与标签label的相关性不强
在这种情况下,怎么学都学不好。
巧妇难为无米之炊。
这种情况就是,我们的特征工程做的不好。
<2>模型的复杂度不够
<3>正则化系数过大
<3>如何解决欠拟合
<1>添加新特征。
当特征不足或者特征与样本标签的相关性不强时,模型容易出现欠拟合。
通过挖掘“上下文特征”、“ID类特征”、“组合特征”等新的特征,往往能够取得更好的效果。
在深度学习潮流中,有很多模型可以帮助完成特征工程,如因子分解机、梯度提升决策树、Deep-crossing等都可以成为丰富特征的方法。
<2>增加模型复杂度。
简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更强的拟合能力。
例如,在线性模型中添加高次项,在神经网络模型中增加网络层数或神经元个数等。
<3>减小正则化系数。
正则化是用来防止过拟合的,但当模型出现欠拟合现象时,则需要有针对性地减小正则化系数。
1/过拟合
当训练数据不多时,或者over-training时,经常会出现over-fitting。
其直观的表现形式如下图所示:
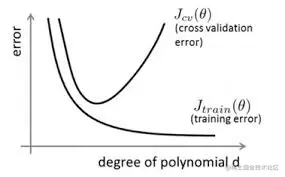
随着训练过程的进行,模型复杂度在增大,在training data上的error渐渐减小, 可是在验证集上的error却反而渐渐增大。
由于训练出来的网络过拟合了训练集,对训练集以外的数据却不work。
在机器学习算法中,我们经常将原始数据集分为三部分:训练集(training data)、验证集(validation data)、测试集(testing data)。
validation data是什么
它事实上就是用来避免过拟合的。
在训练过程中,我们通经常使用它来确定一些超參数(比方,依据validation data上的accuracy来确定early stopping的epoch大小、依据validation data确定learning rate等等)。
那为啥不直接在testing data上做这些呢?
由于假设在testing data做这些,那么随着训练的进行,我们的网络实际上就是在一点一点地overfitting我们的testing data,导致最后得到的testing accuracy没有什么參考意义。
因此,training data的作用是计算梯度更新权重,testing data则给出一个accuracy以推断网络的好坏。


