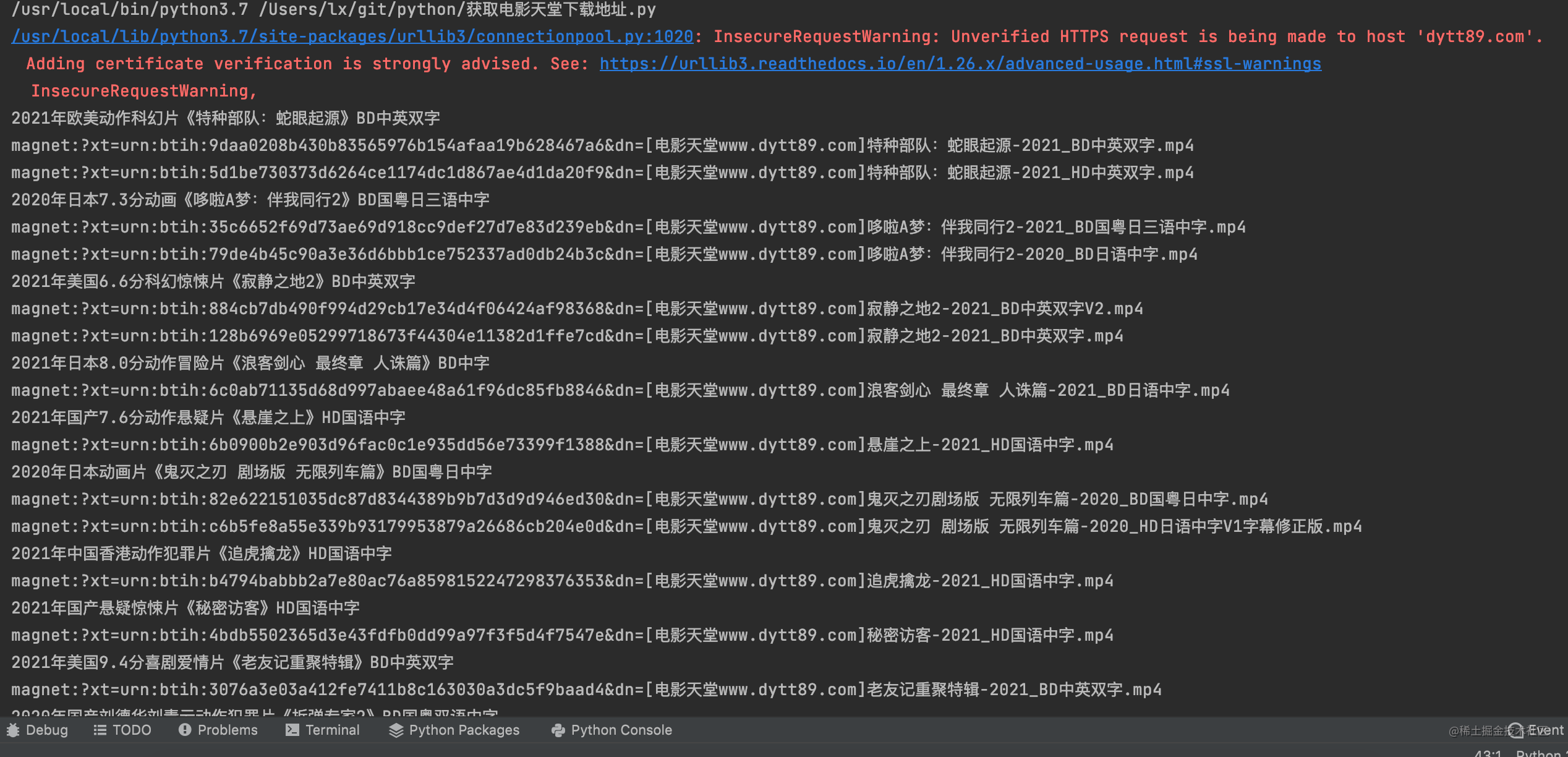
import csv
import requests
import re
url = "https://dytt89.com/"
resp = requests.get(url,verify=False)
resp.encoding = 'gb2312'
page_content = resp.text
obj = re.compile(r'2021必看热片.*?<ul>(?P<page1>.*?)</ul>',re.S)
result = obj.finditer(page_content)
movie_download = open("dytt.csv",mode='w')
movie_write = csv.writer(movie_download)
for it in result:
page_first = it.group('page1')
page1_ojb = re.compile(r'''<li><a href='(?P<movie1>.*?)' title=".*?">.*?</a><span>.*?</li>''',re.S)
result1 = page1_ojb.finditer(page_first)
for itt in result1:
movie_url_list = []
page_movie_url_info = itt.group('movie1')
movie_url = url+page_movie_url_info.strip('/')
movie_url_list.append(movie_url)
for url_listt in movie_url_list:
details = requests.get(url_listt)
details.encoding = 'gb2312'
detaile_content = details.text
details_obj_name = re.compile(r'<div class="title_all"><h1>(?P<movie_name>.*?)</h1></div>',re.S)
details_obj_url = re.compile(r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download_url>.*?)&tr=.*?</a></td>',re.S)
details_result_name = details_obj_name.finditer(detaile_content)
details_result_url = details_obj_url.finditer(detaile_content)
for details_name in details_result_name:
print(details_name.group('movie_name'))
for details_url in details_result_url:
print(details_url.group('download_url'))
movie_download.close()
resp.close()