2 温和的开始
让我们从展示如何在相对简化的环境中实现成功的学习开始我们的数学分析。想象一下,你刚刚到达一个太平洋小岛。你很快就会发现木瓜是当地饮食中的重要成分。然而,你以前从未品尝过木瓜。你必须学会如何预测你在市场上看到的木瓜是否好吃。首先,你需要决定你的预测应该基于木瓜的哪些特征。根据你以前对其他水果的经验,你决定使用两种特性:木瓜的颜色,从深绿色到橙色和红色到深棕色,以及木瓜的柔软度,从岩石硬到糊状。你对预测规则的输入是一个木瓜样本,你检查了它的颜色和柔软度,然后尝了尝,发现它们是否好吃。让我们分析这个任务,作为学习问题所涉及的考虑因素的示范。
我们的第一步是描述一个旨在捕获此类学习任务的正式模型。
2.1 正式的模型——统计学习框架
- 学习器的输入:在基本统计学习设置中,学习器可以访问以下内容:
- (样本)域(Domain)集:一个任意的集合, X 。这是我们可能希望标记的对象集。比如前面提到的木瓜学习问题,域集将是所有木瓜的集合。通常,这些域点将由特征 向量表示(如木瓜的颜色和柔软度)。我们还将域点称为实例 ,将 X 称为实例空间。
- 标签集:在我们当前的讨论中,我们将标签集限制为双元素集,通常为 {0,1} 或 {−1,+1} 。用 Y 表示我们的一组可能的标签。以木瓜为例,让 Y 为 {0,1} ,其中 1 代表好吃, 0 代表不好吃。
- 训练数据: S=((x1,y1)...(xm,ym)) 是在 X×Y 上的有限对序列:即标记域点的序列。这是输入即学习器可以使用的(例如一组已经品尝过的木瓜及其颜色、柔软度和味道)。此类标记示例通常称为训练示例 。我们有时也将 S 称为训练集 。
尽管用的是“集合”的符号,但 S 是一个序列。特别是序列中同一个示例可能在 S 中出现两次,有些算法会考虑到 S 中示例的顺序。
- 学习器的输出: 学习器被要求输出一个预测规则, h:X→Y 。这个函数也被称为预测器、假设或分类器。该预测器可用于预测新域点的标签。以木瓜为例,这是我们的学习器用来预测他在农贸市场检验的未见过的木瓜是否好吃的规则。我们使用符号 A(S) 来表示学习算法 A 在接收到训练序列 S 时返回的假设。
- 一个简单的数据生成模型:我们现在解释训练数据是如何生成的。首先,我们假设实例(我们遇到的木瓜)是由某种概率分布(在这种情况下,代表环境)生成的。让我们用 D 来表示 X 上的概率分布。需要注意的是,我们并不假设学习器知道这个分布。对于我们讨论的学习任务类型,这可以是任意的概率分布。关于标签,在当前的讨论中,我们假设有一些“正确的”标签函数, f:X→Y ,并且对于所有的 i 有 yi=f(xi) 。这个假设将在下一章中放宽。标记函数对于学习器来说是未知的。事实上,这正是学习器想要弄清楚的。总之,训练数据 S 中的每一对都是通过先根据 D 采样一个点,然后用 f 标记它来生成的。
- 成功的度量:我们将分类器的误差 定义为它不能预测由上述潜在分布生成的随机数据点上的正确标签的概率。即 h 的误差是根据分布 D 采样出随机实例 x 并使得 h(x) 不等于 f(x) 的概率。
形式上,给定一个域集的子集 A⊂X ,概率分布 D ,指定一个值 D(A) ,这个值决定了观察一个点 x∈A 的可能性有多大,在很多情况下,我们把 A 称为一个事件,用函数 π:X→{0,1} 表示,即 A={x∈X:π(x)=1} 。在这种情况下,我们也使用符号 Px∼D[π(x)] 来表示 D(A) 。
严格来说,我们应该更加小心,要求 A 是在定义了 D 的 X 子集的一些σ-代数的成员。我们将在下一章正式定义我们的可测性假设。
我们将预测规则的误差定义为
LD,f(h)=defx∼DP[h(x)=f(x)]=defD(x:h(x)=f(x)).(2.1)
也就是说,这样的 h 的误差是随机选择一个示例 x 使得 h(x)=f(x) 的概率。下标 (D,f) 表示误差是根据概率分布 D 和正确的标记函数 f 来测量的。当上下文表述清楚时,我们可以省略这个下标。 L(D,f)(h) 有几个同义词,例如 h 的泛化误差 、风险 或真实误差 ,我们将在整本书中交替使用这些名称。我们使用字母 L 表示错误,因为我们将此错误视为学习器的损失( loss) 。我们稍后还将讨论这种损失的其他可能表述。
- 关于学习器可用信息的注释:学习器对世界上潜在的分布 D 和标记函数 f 是完全不了解的。在我们的木瓜例子中,我们刚刚到达一个新的岛屿,我们不知道木瓜是如何分布的,也不知道如何预测它们的味道。学习器与环境互动的唯一方式是通过观察训练集。
在下一节中,我们将为前面的设置描述一个简单的学习范例,并分析其性能。
2.2 经验风险最小化
如前所述,学习算法接收一个训练集 S 作为输入,该训练集从一个未知分布 D 中采样并由某个目标函数 f 标记,并且应该输出一个预测器 hS:X→Y (下标 S 强调了输出的预测器依赖于 S 的事实)。该算法的目标是找到关于未知 D 和 f 的具有最小化误差的 hS 。
因为学习器不知道 D 和 f 是什么,所以学习器不能直接得到真正的错误。学习器可以计算的一个有用的误差概念是训练误差(经验误差) ——分类器在训练样本上引起的误差:
LS(h)=defm∣{i∈[m]:h(xi)=yi}∣,(2.2)
其中 [m]=1,…,m 。
术语经验误差 和经验风险 经常互换使用。
因为训练样本是学习器可以获得的真实世界的快照,所以搜索一个对该数据有效的解决方案是有意义的。这种学习范式——提出了一个最小化 LS(h) 的预测器——简称为经验风险最小化(Empirical Risk Minimization) 或简称ERM。
2.2.1 可能会出错——过度拟合
尽管ERM规则看起来很自然,但如果不小心,这种方法可能会惨败。
为了说明这样的失败,让我们回到学习根据木瓜的柔软度和颜色来预测其味道的问题。 考虑如下所示的例子:
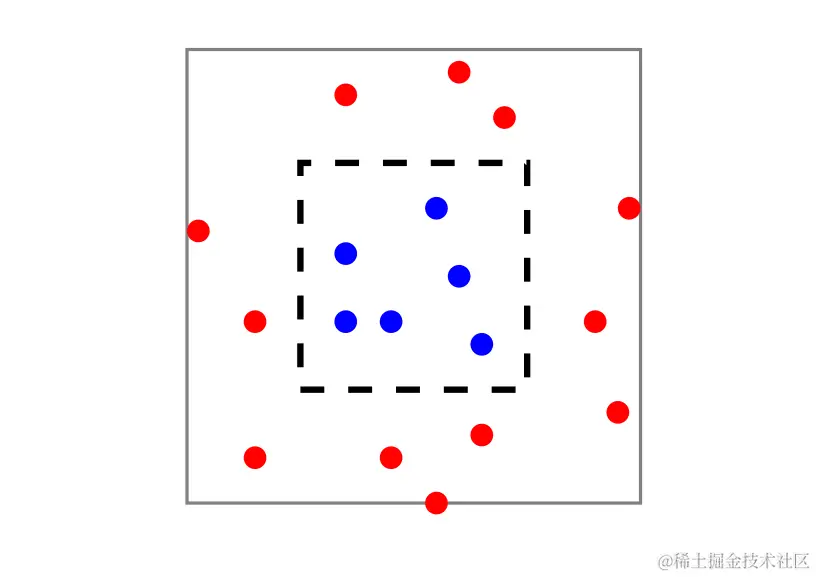 假设概率分布 D 是这样的,即实例在灰色正方形内均匀分布,如果实例在内部黑色正方形内,则标记函数 f 确定标记为 1 ,否则为 0 。图片中灰色正方形的面积是 2 ,黑色正方形的面积是 1 。考虑以下预测器:
假设概率分布 D 是这样的,即实例在灰色正方形内均匀分布,如果实例在内部黑色正方形内,则标记函数 f 确定标记为 1 ,否则为 0 。图片中灰色正方形的面积是 2 ,黑色正方形的面积是 1 。考虑以下预测器:
hS(x)={yi0 if ∃i∈[m] s.t. xi=xotherwise.(2.3)
虽然这个预测器看起来非常像人为设计的,但在练习 1 中,我们使用多项式给出了它比较自然的表示。显然,无论样本是什么, LS(hS)=0 ,因此这个预测器可以通过ERM算法被选择输出(它是经验最小成本假设之一;没有分类器可以具有更小的误差)。另一方面,在这种情况下,仅在有限数量的实例上预测标签 1 的任何分类器的真实误差是 21 。因此, LD(hS)=21 。我们发现了一个预测器,它在训练集上的表现非常出色,但在真实世界上的表现却很差。这种现象被称为过拟合 。直觉上,当我们的假设与训练数据非常吻合时,就会发生过拟合(也许就像日常经验,一个人对自己的每一个行为都提供完美详细的解释可能会引起怀疑)。
2.3 带有归纳偏置的经验风险最小化
我们刚刚证明了ERM规则可能会导致过拟合。但我们不会放弃ERM范式,而是会寻找纠正它的方法。我们将寻找保证在ERM下不发生过拟合的条件,即当ERM预测器在训练数据方面表现良好时,它也很可能在真实潜在数据分布方面表现良好的条件。
一个常见的解决方案是在有限的搜索空间上应用ERM学习规则。形式上,学习器应该提前(在观测到数据之前)选择一个预测器的集合。 这个集合称为假设类 ,用 H 表示。每个 h∈H 都是从 X 到 Y 的函数映射。对于给定的类 H 和训练样本 S , ERMH 学习器使用ERM规则来选择一个预测器 h∈H ,在 S 上具有最低可能的误差。形式上,
ERMH(S)∈h∈Hargmin LS(h),
其中 argmin 代表 H 中的一组假设,该组假设在 H 上达到 LS(h) 的最小值。通过限制学习器从 H 中选择一个预测器,我们将其偏向( bias) 特定的一组预测器。这种限制通常被称为归纳偏置( inductive bias) 。因为这种限制的选择是在学习器观测到训练数据之前确定的,所以它应该理想地基于关于要学习的问题的一些先验知识。例如,对于木瓜味道预测问题,我们可以选择 H 类作为由轴对齐的矩形确定的预测器集合(在由颜色和柔软度坐标确定的空间中)。我们稍后将证明这个类上的 ERMH 是保证不会过拟合的。另一方面,我们之前看到的过拟合的例子表明,选择 H 作为一类预测器,包括所有将值 1 赋给有限域点集的函数,并不足以保证 ERMH 不会过拟合。
学习理论中的一个基本问题是, ERMH 学习哪些假设类不会导致过拟合。我们将在本书的后面研究这个问题。
直觉上,选择一个更受限制的假设类可以更好地保护我们免受过拟合的影响,但同时也可能导致我们产生更强的归纳偏置。我们稍后将回到这个基本的权衡(折中,tradeoff)。
2.3.1 有限假设类
对一个类最简单的限制类型是对它的大小施加一个上限(即 H 中预测器 h 的数量)。在本节中,我们表明,如果 H 是一个有限类,那么 ERMH 不会过拟合,只要它基于足够大的训练样本(训练集的大小要求将取决于 H 的大小)。
将学习器限制在某个有限假设类内的预测规则可能被认为是一个相当温和的限制。例如, H 可以是用最多 109 位(bit)代码编写的C++程序可以实现的所有预测器的集合。在我们的木瓜例子中,我们前面提到了轴对齐矩形类。虽然这是一个无限类,但是如果我们离散化实数的表示,比如说,通过使用 64 位浮点表示,假设类就变成了一个有限类。
现在让我们分析一下 ERMH 学习规则的性能,假设 H 是一个有限类。对于一个训练样本 S ,根据某个 f:X→Y 标记,用 hS 表示在 S 上应用 ERMH 的结果,即,
hS∈h∈Hargmin LS(h).(2.4)
在本章中,我们做了以下简化假设(将在下一章中放宽)。
定义2.1(可实现性假设) 存在 h∗∈H s.t. L(D,f)(h∗)=0 。请注意,这个假设意味着对于随机样本 S (其中 S 的实例根据分布 D 进行采样,并用 f 标记)我们有 LS(h∗)=0 的概率为 1 .
可实现性假设意味着,对于每个ERM假设,我们都有 LS(hS)=0 。然而,我们感兴趣的是 hS 的真实风险 L(D,f)(hS) ,而不是它的经验风险。
从数学上讲,这里假设成立的概率为 1 。为了简化演示,我们有时会省略“概率为 1 ”的说明符。
显然,对于只能访问样本 S 的算法,任何关于基础分布 D 的误差保证都应该取决于 D 和 S 之间的关系。统计机器学习中的常见假设是,训练样本 S 是由分布 D 中的采样点彼此独立地生成的(即独立同分布)。正式地
- 独立同分布假设: 训练集中的示例根据分布 D 独立且同分布(i.i.d.)。也就是说, S 中的每个 xi 都是根据分布 D 新采样的,然后根据标记函数 f 被标记。我们用 S∼Dm 表示这个假设,其中 m 是 S 的大小, Dm 表示通过应用 D 独立于元组的其他成员挑选元组的每个元素而得到的 m 元组的概率。
直观地说,训练集 S 是一个窗口,学习者通过它获得关于世界范围内分布 D 和标注函数 f 的部分信息。样本量越大,越有可能更准确地反映用于生成它的概率分布和标注函数。
由于 L(D,f)(hS) 依赖于训练集 S ,并且该训练集是由随机过程挑选的,因此在预测值 hS 的选择中存在随机性,因此在风险 L(D,f)(hS) 中也存在随机性。形式上,我们说它是一个随机变量。期待完全确定的 S 足以引导学习器找到一个好的分类器(从 D 的角度来看)是不现实的,因为总有一些概率,采样的训练数据碰巧非常不代表真实潜在的 D 。如果我们回到木瓜味道预测的例子,总有一些(小)机会,我们品尝的所有木瓜碰巧都不好吃,尽管事实上,比如说,我们岛上 70% 的木瓜都好吃。在这种情况下, ERMH(S) 可能是将每个木瓜都标记为“不好吃”的恒定函数(并且对岛内木瓜的真实分布有 70% 的误差)。因此,我们将讨论对真实风险 L(D,f)(hS) 不太大的训练集进行采样的概率 。通常,我们用 δ 表示得到非代表性样本的概率,称 (1−δ) 为我们预测的置信参数 。
最重要的是,由于我们不能保证完美的标签预测,我们引入了另一个关于预测质量的参数,即精度参数,通常用 ϵ 表示。 我们解释事件 L(D,f)(hS)>ϵ 为学习器的失败,而如果 L(D,f)(hS)≤ϵ 我们将算法的输出视为近似正确的预测器。 因此(固定一些标记函数 f:X→Y ),我们感兴趣的是对将导致学习器失败的实例的 m 元组进行采样的概率上限。正式地,令 S∣x=(x1,…,xm) 是训练集的实例。 则概率上限为
Dm({S∣x:L(D,f)(hS)>ϵ}).
注解:
当我们选择的样本集中的所有样本都使得ERM选择的假设经验风险 LS(hS)=0 时才成立,否则就不可能是ERM选择的输出,所有是 m 次方。上述概率上限即ERM选择的假设在我们选择的样本集上的经验风险 LS(hS)=0 且真实风险 L(D,f)(hS)>ϵ 的概率上限。
令 HB 为“坏”假设的集合,也就是说,
HB={h∈H:L(D,f)(h)>ϵ}.
另外,令
M={S∣x:∃h∈HB,LS(h)=0}
作为误导样本的集合:也就是说,对于每一个 S∣x∈M ,都有一个“坏的”假设 h∈HB ,它看起来像是在 S∣x 上的“好的”假设,现在,回想一下,我们希望约束事件 L(D,f)(hS)>ϵ 的概率。但是,既然可实现性假设意味着 LS(hS)=0 ,那么由此可知事件 L(D,f)(hS)>ϵ 只有当对于某些 h∈HB 我们有 LS(h)=0 时才会发生。换句话说,只有当我们的样本在误导样本集中时,这个事件才会发生。形式上地,我们已经证明了这一点
{S∣x:L(D,f)(hS)>ϵ}⊆M.
请注意,我们可以将 M 重写为
M=h∈HB⋃{S∣x:LS(h)=0}.(2.5)
因此,
Dm({S∣x:L(D,f)(hS)>ϵ})≤Dm(∪h∈HB{S∣x:LS(h)=0}).(2.6)
接下来,我们使用联合界(概率的一个基本属性)来约束上限前面等式的右侧。
引理2.2(union bound) 对于任意两个集合 A , B 和分布 D,我们都有
D(A∪B)≤D(A)+D(B).
布尔不等式(Boole’s inequality)也叫(union bound),即并集的上界
将union bound应用于等式(2.6)的右侧会产生
Dm({S∣x:L(D,f)(hS)>ϵ})≤h∈HB∑Dm({S∣x:LS(h)=0}).(2.7)
接下来,让我们限制前面不等式右侧的每个被加数。固定一些“坏的”假设 h∈HB 。 事件 LS(h)=0 等价于事件 ∀i , h(xi)=f(xi) 。由于训练集中的示例是独立同分布采样的。我们得到
Dm({S∣x:LS(h)=0})=Dm({S∣x:∀i,h(xi)=f(xi)})=i=1∏mD({xi:h(xi)=f(xi)}).(2.8)
对于我们所拥有的训练集元素的每个单独采样
D({xi:h(xi)=f(xi)})=1−L(D,f)(h)≤1−ϵ,
其中最后一个不等式源于上面对于 HB 的定义( h∈HB )。将前面的等式与等式(2.8)相结合,并使用不等式 1−ϵ≤e−ϵ 我们得到对于每个 h∈HB ,
Dm({S∣x:LS(h)=0})≤(1−ϵ)m≤e−ϵm.(2.9)
将上式与方程(2.7)结合起来,我们得出结论
Dm({S∣x:L(D,f)(hS)>ϵ})≤∣HB∣e−ϵm≤∣H∣e−ϵm.
图2.1给出了解释我们如何使用联合边界的图解。
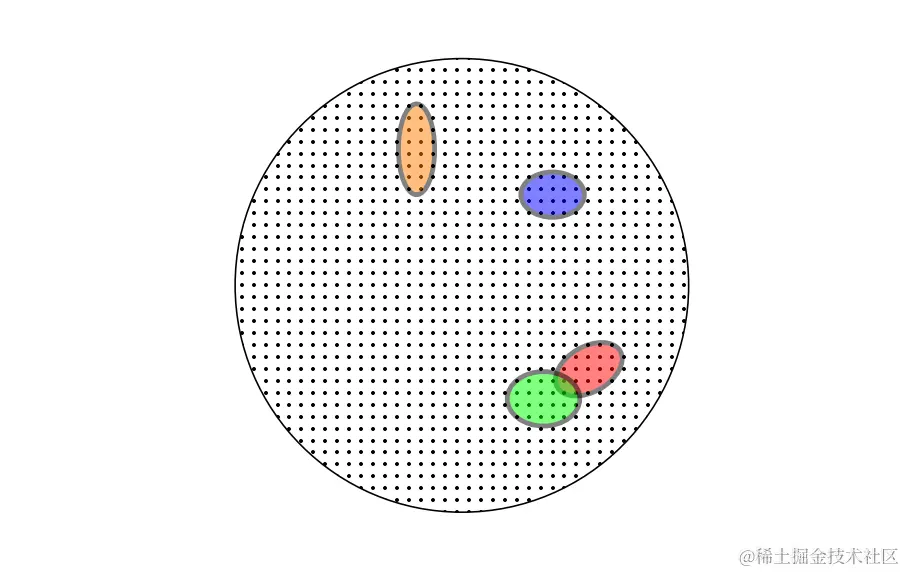
图2.1:大圆中的每个点代表一个可能的 m 元组实例。每个彩色椭圆代表一些导致“坏的”预测器(假设) h∈HB 产生“误导性”的 m 元组实例集。每当EMR得到一个误导性的训练集 S 时,它可能会导致过拟合。也就是说,对于某些 h∈HB 我们有 LS(h)=0 。等式(2.9)保证对于每个单独的坏的假设 h∈HB ,最多有训练集的 (1−ϵ)m 的部分会产生误导。特别地, m 越大,这每一个彩色椭圆中都变得越小。布尔不等式形式化了这样一个事实,即表示相对于某些 h∈HB(即 M 中的训练集)有误导性的训练集的面积至多是彩色椭圆的面积之和。因此,它的边界是 ∣HB∣ 乘以彩色椭圆的最大尺寸。彩色椭圆之外的任何样本 S 都不会导致ERM规则过拟合。
推论2.3 设 H 是一个有限假设类。令 δ∈(0,1) 和 ϵ>0 并令 m 为整数使得满足
m≥ϵlog(δ∣H∣)
注解:
m⇒ ϵm⇒ eϵm⇒ δ⇒ δ≥ϵlog(δ∣H∣)≥log(δ∣H∣)≥δ∣H∣≥eϵm∣H∣≥∣H∣e−ϵm( 其中 δ∈(0,1),ϵ为度量预测质量的精度参数 )
然后,对于任何标记函数 f 和任何分布 D ,可实现性假设成立(也就是说,对于某些 h∈H , L(D,f)(h)=0 ),对于选择集合大小为 m 的独立同分布样本集 S ,我们认为对于每个ERM假设 hS ,至少有 1−δ 的概率有
L(D,f)(hS)≤ϵ.
前面的推论告诉我们,对于一个足够大的 m ,有限假设类上的 ERMH 规则是概率 (置信度为 1−δ )近似 (最大误差为 ϵ )正确。在下一章中,我们正式定义了概率近似正确(PAC)学习模型。
注解:
因为 δ∈(0,1) ,有
δ≥∣H∣e−ϵm≥∣HB∣e−ϵm
则
1−δ≤1−∣H∣e−ϵm≤1−∣HB∣e−ϵm
其中 ∣HB∣e−ϵm 表示ERM选择的假设在我们选择的样本集上的经验风险 LS(hS)=0 但真实风险 L(D,f)(hS)>ϵ 的概率上限。
2.4 习题
1. 多项式匹配的过拟合: 我们已经表明等式(2.3)中定义的预测器会导致过拟合。虽然这个预测器看起来很不自然,这个练习的目的是表明它可以被描述为一个阈值多项式。也就是说,证明给定一个训练集 S={(xi,f(xi))}i=1m⊂(Rd×{0,1})m ,存在一个多项式 pS ,当且仅当 pS(x)≥0 时,使得 hS(x)=1 ,其中 hS 是在等式(2.3)中所定义。因此,使用ERM规则学习所有阈值多项式的类别可能会导致过拟合。
解: 给定 S=((xi,yi))i=1m ,定义多元多项式
pS(x)=−i∈[m]:yi=1∏∥x−xi∥2.
那么,对于每一个使得 yi=1 的 i ,我们有 pS(xi)=0 ,而对于每一个其他的 x ,我们有 pS(x)<0 。
2. 设 H 是域 X 上的一类二元分类器,设 D 是 X 上的未知分布,设 f 是 H 中的目标假设,固定一些 h∈H ,证明 LS(h) 关于 S∣x 的选择的期望值等于 L(D,f)(h) ,即,
S∣x∼DmE[LS(h)]=L(D,f)(h).
解: 根据期望的线性性质,
S∣x∼DmE[LS(h)]=S∣x∼DmE[m1i=1∑m1[h(xi)=f(xi)]]=m1i=1∑mxi∼DE[1[h(xi)=f(xi)]]=m1i=1∑mxi∼DP[h(xi)=f(xi)]=m1⋅m⋅L(D,f)(h)=L(D,f)(h) .
3. 轴对齐矩形: 平面中的轴对齐矩形分类器是一种分类器,当且仅当某个点位于某个矩形内时,它会将值 1 赋给该点。形式上,给定实数 a1≤b1 ,a2≤b2 ,定义分类器 h(a1,b1,a2,b2) 如下
h(a1,b1,a2,b2)(x1,x2)={1if a1≤x1≤b1 and a2≤x2≤b20otherwise.(2.10)
平面中所有轴对齐矩形的类别定义为
Hrec2={h(a1,b1,a2,b2):a1≤b1, and a2≤b2} .
注意,这是一个无限大小的假设类。在整个练习中,我们依赖于可实现性假设。
- 设 A 是返回包含训练集中所有正例的最小矩形的算法。证明 A 是一个ERM。
- 说明如果 A 收到一个大小(size) ≥ϵ4log(δ4)的训练集,那么至少有 1−δ 的概率,它返回的假设误差最多为 ϵ 。
提示 :固定 X 上的一些分布 D,令 R∗=R(a1∗,b1∗,a2∗,b2∗) 为一个用来生成标签的矩形,令 f 为对应的假设(即标记函数)。设 a1≥a1∗ 为一个数,使得矩形 R1=R(a1∗,a1,a2∗,b2∗,) 的概率质量(关于 D )恰好为 4ϵ 。类似地,设 b1,a2,b2 为数字,使得矩形 R2=R(b1,b1∗,a2∗,b2∗) , R3=R(a1∗,b1∗,a2∗,a2) , R4=R(a1∗,b1∗,b2,b2∗) 的概率质量都正好 4ϵ 。设 R(S) 为 A 返回的矩形,见图2.2。
- 证明 R(S)⊂R∗ 。
- 证明如果 S 在所有的矩形 R1,R2,R3,R4 中包含(正的)示例,那么 A 返回的假设最多有误差 ϵ 。
- 对于每个 i∈{1,…,4} ,S 不包含来自 Ri 的示例的概率上界。
- 用union bound来结束讨论。
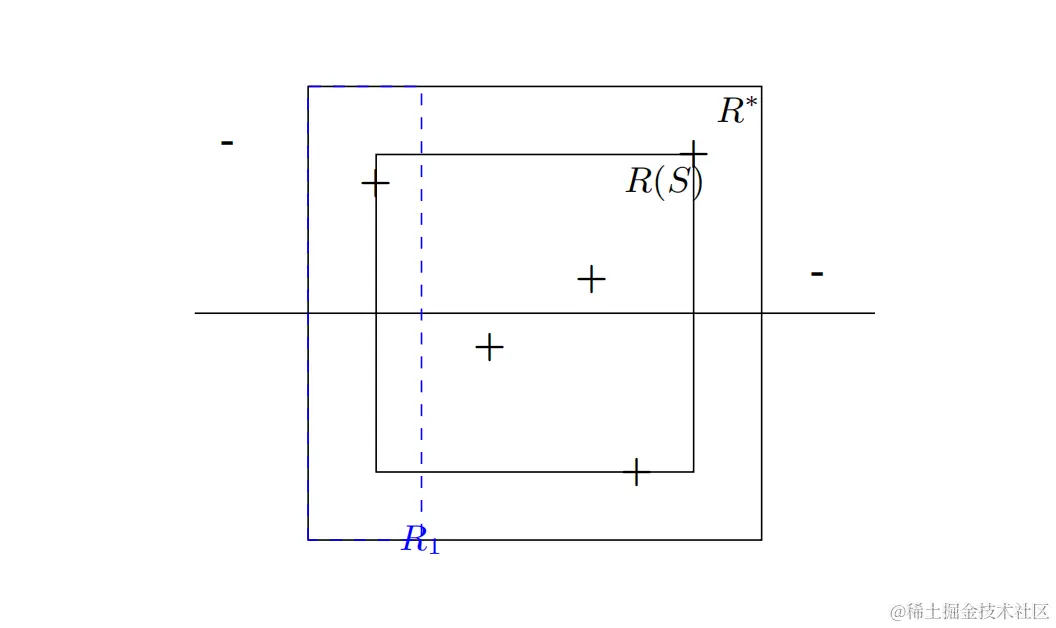
图2.2:轴对齐的矩形。
- 对 Rd 中的轴对齐矩形类重复上一个问题。
- 证明应用前面提到的算法 A 的运行时间是 d 、ϵ1 、log(δ1) 中的多项式。
解:
(1)首先,观察根据定义, A 肯定地标记了训练集中的所有正实例。其次,当我们假设可实现性时,由于返回了包围所有正实例的最紧矩形,所以所有负实例也被 A 正确标记。我们的结论是 A 是一个ERM。
(2)固定 X 上的一些分布 D ,定义 R∗ 就像提示里说的那样。设 f 为与 R∗ 相关的训练集 S 的假设(即标记函数),用 R(S) 表示由所提出的算法返回的矩形,用 A(S) 表示相应的假设。算法 A 的定义意味着对于每个 S 有 R(S)⊆R∗ 。因此,
L(D,f)(R(S))=D(R∗∖R(S)).
固定一些 ϵ∈(0,1) 。
叙述一:
像提示中那样定义 R1,R2,R3 和 R4 。为每个 i 定义事件
Fi={S∣x:S∣x∩Ri=∅}.
应用union bound,我们得到
Dm({S:L(D,f)(A(S))>ϵ})≤Dm(i=1⋃4Fi)≤i=1∑4Dm(Fi) .
因此,保证对于每一个 i 的 Dm(Fi)≤4δ 就足够了。固定一些 i∈[4] ,那么,样本在 Fi 中的概率就是所有实例不在 Ri 中的概率,正好是 (1−4ϵ)m 。因此,
Dm(Fi)=(1−4ϵ)m≤exp(−4mϵ) ,
因此,
Dm({S:L(D,f)(A(S))>ϵ})≤4exp(−4mϵ) .
插入关于 m 的假设,得证。
叙述二:
PAC学习算法 A ,给定一个带标签的样本 S ,该算法包括返回的最紧的轴对齐矩形 R′=R(s) ,其中包含标记为 1 的点。根据定义,其点必须包含在目标概念 R 中,所以 R(S) 不会产生任何假阳性( R(S) 标记为正的点但实际上标签为负的点)。因此,R(S) 的误差区域包括在 R 中。
这里的 R 即 R∗ (用来生成标签的矩形),R′ 即 R(S) 。固定 ϵ>0 。设 P[R] 表示由 R 定义的区域的概率质量,即根据 D 随机抽取的点落在 R 范围内的概率。由于我们的算法所产生的误差只能由落在 R 内的点引起,我们可以假设 P[R]>ϵ ;否则,不管收到的训练样本 S 如何 R(S) 的误差一定小于或等于 ϵ 。
现在,由于 P[R]>ϵ ,我们可以沿着 R(S) 的边定义四个矩形区域 r1,r2,r3 和 r4,每个区域的概率质量至少是 4ϵ 。这些区域可以通过从完整的矩形 R 开始构建,然后通过尽可能多地移动一侧来减小尺寸,同时保持至少 4ϵ 的分布质量。图2.3说明了这些区域的定义。
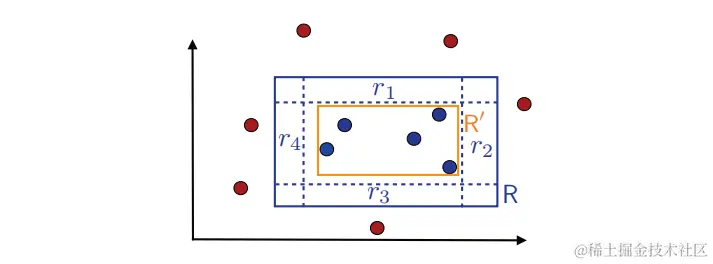
图2.3:区域 r1,…,r4 的图解。
设 l 、r 、b 和 t 是定义 R:R=[l,r]×[b,t] 的四个实值。那么,比如左矩形 r4 定义为 r4=[l,s4]×[b,t] ,s4=inf{s:P[[l,s]×[b,t]]≥4ϵ} 。不难看出,区域 r4=[s4,r]×[b,t] 是通过由 r4 排除最右侧(概率最多 4ϵ )得到的。r1 、r2 、R3 和 r1 、r2 、r3 以类似的方式定义。
注意,如果 R(S) 与这四个区域都相交,由于它是一个矩形,它将在这四个区域中各有一条边(几何参数)。它的误差区域,即它没有覆盖到的 R 中的部分,包含在区域 ri (其中 i∈[4] )的并集中,其概率不可能大于 ϵ 。通过对照,如果 L(D,f)(R(S))>ϵ ,则 R(S) 必须至少与一个区域 ri (其中 i∈[1,4] )不相交。因此,我们可以认为
S∼DmP[L(D,f)(R(S))>ϵ]≤S∼DmP[∪i=14{R(S)∩ri=∅}](2.5)≤i=1∑4S∼DmP[{R(S)∩ri=∅}](受并集约束)≤4(1−4ϵ)m(因为P[ri]>ϵ/4)≤4exp(−4mϵ)
在最后一步中,对于所有 x∈R2 我们使用一般恒等式 1−x≤e−x 。对于任何 δ>0 ,确保 PS∼Dm[L(D,f)(R(S))>ϵ]≤δ ,我们可以进一步认为
4exp(−4mϵ)≤δ⇔m≥ϵ4logδ4(2.6)
因此,对于任何 ϵ>0 和 δ>0 ,如果样本大小 m 大于 ϵ4logδ4 ,那么 PS∼Dm[L(D,f)(R(S))>ϵ]≤δ 。此外,R2 和轴对齐矩形中的点的表示的计算成本是恒定的,可以通过它们的四个角来定义。这证明了轴对齐矩形的概念类是PAC可学的,且PAC可学的轴对齐矩形样本复杂度为 O(ϵ1logδ1) 。
我们也许经常会看到与式(2.6)类似的样本复杂度结果的等效方法,是给出泛化界。泛化界表明,在概率至少为 1−δ 的情况下,L(D,f)(R(S)) 的上限是取决于样本大小 m 和 δ 的某个量。为了得到这一点,如果满足 δ 等于式(2.5)中推导出的上界,即 δ=4exp(−4mϵ) ,就可解出 ϵ 。当概率至少为 1−δ 时,算法的有界误差为:
L(D,f)(R(S))≤m4logδ4(2.7)
在这个例子中可以考虑其他PAC学习算法。例如,一种替代方法是返回不包含负值的最大轴对齐矩形。本文所给出的最紧轴对齐矩形的PAC学习,可以很容易地应用于其他这类算法的分析。
(3) Rd 中的轴对齐矩形的假设类定义如下。给定实数 a1≤b1 ,a2≤b2 ,… , ad≤bd ,定义分类器 h(a1,b1, … ,ad,bd) 由
h(a1,b1, … ,ad,bd)(xi, … ,xd)={1if ∀i∈[d],ai≤xi≤bi0otherwise(1)
Rd 中所有轴对齐矩形的假设类定义为
Hrecd={h(a1,b1, … ,ad,bd):∀i∈[d],ai≤bi}.
可以看出,上面提出的相同算法也是这种情况下的ERM。类似地分析样本复杂性。唯一的区别是,我们没有 4 条,而是有 2d 条(每个维度 2 条)。因此,抽取大小为 ⌈ϵ2dlog(δ2d)⌉ 的训练集就足够了。
(4)对于每个维度,该算法必须找到训练序列中正实例的最小值和最大值。因此,它的运行时是 O(md) 。既然我们已经证明了 m 的要求值最多是 ⌈ϵ2dlog(δ2d)⌉ ,那么算法的运行时间的确是关于 d ,ϵ1 和 log(δ1) 的多项式。

