

- 原文地址:Build an Article Recommendation Engine With AI/ML
- 原文作者:Tyler Hawkins
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:jaredliw
- 校对者:greycodee、KimYangOfCat
内容平台在向用户推荐相关内容方面发展迅速。平台提供的相关内容越多,用户在网站上停留的时间就越长,而这通常会转化为公司的广告收入。
如果你曾经访问过新闻网站、电子出版社或博客平台,那么你很可能已经接触过推荐引擎。每一个平台都会根据你的阅读历史记录,推荐你可能喜欢的内容。
列举一个简单的解决方案,一个平台可以实现一个基于标签的推荐引擎 —— 比如你阅读了一篇「商业」文章,它还会推荐给你五篇标记为「商业」的相关文章。然而,构建推荐引擎的更好方法是使用相似性搜索和机器学习算法。
在本文中,我们将构建一个 Python Flask 应用程序,该应用程序会使用 Pinecone(一个相似性搜索的服务)来创建我们自己的文章推荐引擎。
演示应用程序概览
下面的简短动画演示了我们的应用程序是如何工作的。最初有十篇文章显示在页面上。用户可以选择任意组合这十篇文章来代表他们的阅读历史。当用户点击提交按钮时,阅读历史将作为输入数据,用以查询文章数据库,然后再向用户显示十篇相关文章。

可以看到,返回的相关文章非常准确!在此示例中,有 1,024 种可能的阅读历史组合可用作输入,并且每种组合都会产生有意义的结果。
那么我们是如何做到的呢?
在构建应用程序时,我们首先从 Kaggle 找到了一个新闻文章数据集。该数据集包含来自 15 个主要出版社的 143,000 篇新闻文章,但我们仅使用前 20,000 篇。(完整数据集包含超过 200 万篇文章!)
之后,我们通过重命名几列并删除不必要的列来清理数据集。接下来,我们将文章输入 embedding 模型以获取各文章的 embedding 向量 —— 这是机器学习算法确定各种输入之间相似性的元数据。我们使用的是平均词嵌入模型。然后,我们将这些 embedding 向量插入到由 Pinecone 管理的向量索引中。
将 embedding 向量添加到索引后,我们就可以开始查找相关内容了。当用户提交他们的阅读历史时,会发送一个请求到 API 端点,该端点使用 Pinecone 的 SDK 来查询 embedding 向量的索引。端点返回十篇类似的新闻文章并将它们显示在应用程序的 UI 中。就是这样!是不是很简单?
如果你想亲自尝试一下,你可以在 GitHub 上找到此应用程序的源码。在 README 中包含了如何在本地设备上运行应用程序的指示和说明。
代码实现
我们已经了解了应用程序的内部工作原理,但我们实际上是如何构建它的呢?如前所述,这是一个使用 Pinecone SDK 的 Python Flask 应用程序。HTML 使用模板文件,前端的其余部分使用静态 CSS 和 JavaScript 构建。为简单起见,所有后端代码都在 app.py 文件中,我将该文件完整地复制在了下面:
from dotenv import load_dotenv
from flask import Flask
from flask import render_template
from flask import request
from flask import url_for
import json
import os
import pandas as pd
import pinecone
import re
import requests
from sentence_transformers import SentenceTransformer
from statistics import mean
import swifter
app = Flask(__name__)
PINECONE_INDEX_NAME = "article-recommendation-service"
DATA_FILE = "articles.csv"
NROWS = 20000
def initialize_pinecone():
load_dotenv()
PINECONE_API_KEY = os.environ["PINECONE_API_KEY"]
pinecone.init(api_key=PINECONE_API_KEY)
def delete_existing_pinecone_index():
if PINECONE_INDEX_NAME in pinecone.list_indexes():
pinecone.delete_index(PINECONE_INDEX_NAME)
def create_pinecone_index():
pinecone.create_index(name=PINECONE_INDEX_NAME, metric="cosine", shards=1)
pinecone_index = pinecone.Index(name=PINECONE_INDEX_NAME)
return pinecone_index
def create_model():
model = SentenceTransformer('average_word_embeddings_komninos')
return model
def prepare_data(data):
# 重命名 id 列并删除不必要的列
data.rename(columns={"Unnamed: 0": "article_id"}, inplace = True)
data.drop(columns=['date'], inplace = True)
# 仅提取每篇文章的前几句话以加快向量的计算
data['content'] = data['content'].fillna('')
data['content'] = data.content.swifter.apply(lambda x: ' '.join(re.split(r'(?<=[.:;])\s', x)[:4]))
data['title_and_content'] = data['title'] + ' ' + data['content']
# 基于标题列和文章列,创建 embedding 向量
encoded_articles = model.encode(data['title_and_content'], show_progress_bar=True)
data['article_vector'] = pd.Series(encoded_articles.tolist())
return data
def upload_items(data):
items_to_upload = [(row.id, row.article_vector) for i, row in data.iterrows()]
pinecone_index.upsert(items=items_to_upload)
def process_file(filename):
data = pd.read_csv(filename, nrows=NROWS)
data = prepare_data(data)
upload_items(data)
pinecone_index.info()
return data
def map_titles(data):
return dict(zip(uploaded_data.id, uploaded_data.title))
def map_publications(data):
return dict(zip(uploaded_data.id, uploaded_data.publication))
def query_pinecone(reading_history_ids):
reading_history_ids_list = list(map(int, reading_history_ids.split(',')))
reading_history_articles = uploaded_data.loc[uploaded_data['id'].isin(reading_history_ids_list)]
article_vectors = reading_history_articles['article_vector']
reading_history_vector = [*map(mean, zip(*article_vectors))]
query_results = pinecone_index.query(queries=[reading_history_vector], top_k=10)
res = query_results[0]
results_list = []
for idx, _id in enumerate(res.ids):
results_list.append({
"id": _id,
"title": titles_mapped[int(_id)],
"publication": publications_mapped[int(_id)],
"score": res.scores[idx],
})
return json.dumps(results_list)
initialize_pinecone()
delete_existing_pinecone_index()
pinecone_index = create_pinecone_index()
model = create_model()
uploaded_data = process_file(filename=DATA_FILE)
titles_mapped = map_titles(uploaded_data)
publications_mapped = map_publications(uploaded_data)
@app.route("/")
def index():
return render_template("index.html")
@app.route("/api/search", methods=["POST", "GET"])
def search():
if request.method == "POST":
return query_pinecone(request.form.history)
if request.method == "GET":
return query_pinecone(request.args.get("history", ""))
return "Only GET and POST methods are allowed for this endpoint"
app.run()
让我们回顾一下 app.py 文件的重要部分,以便我们能理解它。
在第 1 至 14 行,我们引入应用程序的依赖。我们的应用程序依赖以下的包:
dotenv用于从.env文件中读取环境变量flask用于设置 Web 应用程序json用于处理 JSONos也用于获取环境变量pandas用于处理数据集pinecone用于使用 Pinecone SDKre用于处理正则表达式(RegEx)requests用于发送 API 请求以下载我们的数据集statistics提供了一些方便的统计函数sentence_transformers用于我们的嵌入模型swifter用于处理pandas的DataFrame
在第 16 行,我们提供了一些模板代码来告诉 Flask 我们应用程序的名称。
在第 18 至 20 行,我们定义了一些将在应用程序中使用的常量,其中包括我们的 Pinecone 索引名称、数据集的文件名以及要从 CSV 文件中读取的行数。
在第 22 至 25 行,我们的 initialize_pinecone 方法从 .env 文件中获取 API 密钥并使用它来初始化 Pinecone。
在第 27 至 29 行,我们的 delete_existing_pinecone_index 方法在 Pinecone 实例中搜索与我们正在使用的索引(“article-recommendation-service”)同名的索引。如果找到现有索引,我们将其删除。
在第 31 至 35 行,我们的 create_pinecone_index 方法使用我们选择的名称(“article-recommendation-service”)创建一个新索引,使用余弦相似度作为指标,数据分片为 1。
在第 37 至 40 行,我们的 create_model 方法使用 sentence_transformers 库来处理平均词嵌入模型。稍后我们将使用这个模型对我们的 embedding 向量进行编码。
在第 62 至 68 行,我们的 process_file 方法读取 CSV 文件,然后调用 prepare_data 和 upload_items 方法。这两个方法的介绍在下方。
在第 42 至 56 行,我们的 prepare_data 方法通过重命名第一个 id 列并删除 date 列来调整数据集。然后,它抓取每篇文章的前四行,并将它们与文章标题结合起来,创建一个新字段,作为要编码的数据。我们可以基于文章的整个正文创建 embedding 向量,但为了加快编码过程,四行就足够了。
在第 58 至 60 行,我们的 upload_items 方法通过使用我们的模型对其进行编码来为每篇文章创建一个 embedding 向量,然后将 embedding 向量插入到 Pinecone 索引中。
在第 70 至 74 行,我们的 map_titles 和 map_publications 方法创建了一些包含标题和出版商的字典,以便以后更容易通过它们的 ID 查找文章。
上方描述的每个方法都会在后端应用程序启动时在第 98 至 104 行调用。这项工作让我们为最后一步 —— 根据用户输入查询 Pinecone 索引,做好准备。
在第 106 至 116 行,我们为应用程序定义了两条路由:一条用于主页,另一条用于 API 端点。主页提供 index.html 模板文件以及 JavaSript 和 CSS 资产,API 端点则提供查询 Pinecone 索引的搜索功能。
最后,在第 76 至 96 行,我们的query_pinecone 方法获取用户的阅读历史输入,将其转换为 embedding 向量,然后查询 Pinecone 索引以查找相似的文章。获取 /api/search 端点时将调用此方法。每当用户提交新的搜索查询时都会调用这个 API。
对于视觉学习者,这里提供一个概述应用程序如何工作的图表:
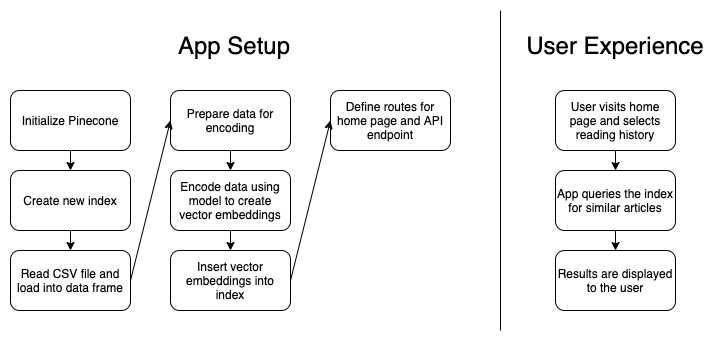
示例场景
那么,将所有的这些综合到一起,用户体验如何?我们来看看三个场景:分别对体育、技术和政治感兴趣的三群用户。
体育用户选择前两篇关于塞雷娜·威廉姆斯(Serena Williams)和安迪·穆雷(Andy Murray)这两位著名网球运动员的文章作为他们的阅读历史。在他们提交选择后,该应用程序会返回有关温布尔登网球锦标赛、美国公开赛、罗杰·费德勒(Roger Federer)和拉斐尔·纳达尔(Rafael Nadal)的文章。准确!
对技术感兴趣的用户选择了有关三星和苹果的文章。在他们提交选择后,该应用会回复有关三星、苹果、谷歌、英特尔和 iPhone 的文章。又是个很好的推荐!
对政治感兴趣的用户选择一篇关于选举舞弊的文章。在他们提交他们的选择后,该应用程序会返回有关选民 ID、美国 2020 年大选、选民投票率和非法选举声言(以及他们为什么不阻止)的文章。
试了三个场景后!事实证明,我们的推荐引擎非常有用。
结论
我们现在已经创建了一个简单的 Python 应用程序来解决现实生活中的问题。如果内容网站能够向用户推荐相关内容,用户就会更喜欢这些内容,并会在网站上花费更多时间,从而为公司带来更多收入。双赢局面!
相似性搜索有助于为你的用户提供更好的建议。而 Pinecone,作为一个相似性搜索的服务方,可使你能轻松地向用户提供推荐,以便您可以专注于自己最擅长的事情 —— 构建一个充满值得阅读的内容的优质平台。
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
