连接查询
SQLyog Ultimate v10.00 Beta1
MySQL - 5.7.18-log : Database - girls
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`girls` /*!40100 DEFAULT CHARACTER SET gb2312 */;
USE `girls`;
/*Table structure for table `admin` */
DROP TABLE IF EXISTS `admin`;
CREATE TABLE `admin` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(10) NOT NULL,
`password` varchar(10) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
/*Data for the table `admin` */
insert into `admin`(`id`,`username`,`password`) values (1,'john','8888'),(2,'lyt','6666');
/*Table structure for table `beauty` */
DROP TABLE IF EXISTS `beauty`;
CREATE TABLE `beauty` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`sex` char(1) DEFAULT '女',
`borndate` datetime DEFAULT '1987-01-01 00:00:00',
`phone` varchar(11) NOT NULL,
`photo` blob,
`boyfriend_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8;
/*Data for the table `beauty` */
insert into `beauty`(`id`,`name`,`sex`,`borndate`,`phone`,`photo`,`boyfriend_id`) values (1,'柳岩','女','1988-02-03 00:00:00','18209876577',NULL,8),(2,'苍老师','女','1987-12-30 00:00:00','18219876577',NULL,9),(3,'Angelababy','女','1989-02-03 00:00:00','18209876567',NULL,3),(4,'热巴','女','1993-02-03 00:00:00','18209876579',NULL,2),(5,'周冬雨','女','1992-02-03 00:00:00','18209179577',NULL,9),(6,'周芷若','女','1988-02-03 00:00:00','18209876577',NULL,1),(7,'岳灵珊','女','1987-12-30 00:00:00','18219876577',NULL,9),(8,'小昭','女','1989-02-03 00:00:00','18209876567',NULL,1),(9,'双儿','女','1993-02-03 00:00:00','18209876579',NULL,9),(10,'王语嫣','女','1992-02-03 00:00:00','18209179577',NULL,4),(11,'夏雪','女','1993-02-03 00:00:00','18209876579',NULL,9),(12,'赵敏','女','1992-02-03 00:00:00','18209179577',NULL,1);
/*Table structure for table `boys` */
DROP TABLE IF EXISTS `boys`;
CREATE TABLE `boys` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`boyName` varchar(20) DEFAULT NULL,
`userCP` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
/*Data for the table `boys` */
insert into `boys`(`id`,`boyName`,`userCP`) values (1,'张无忌',100),(2,'鹿晗',800),(3,'黄晓明',50),(4,'段誉',300);
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
含义:又称多表查询,当查询的字段来自于多个表时,就会用到连接查询
笛卡尔乘积现象:表1 有m行,表2有n行,结果=m*n行
发生原因:没有有效的连接条件
如何避免:添加有效的连接条件
分类:
按年代分类:
sql92标准:仅仅支持内连接
sql99标准【推荐】:支持内连接+外连接(左外和右外)+交叉连接
按功能分类:
内连接:
等值连接
非等值连接
自连接
外连接:
左外连接
右外连接
全外连接
交叉连接
*/
SELECT * FROM beauty;
SELECT * FROM boys;
SELECT NAME,boyName FROM boys,beauty
WHERE beauty.boyfriend_id= boys.id;
#一、sql92标准
#1、等值连接
/*
① 多表等值连接的结果为多表的交集部分
②n表连接,至少需要n-1个连接条件
③ 多表的顺序没有要求
④一般需要为表起别名
⑤可以搭配前面介绍的所有子句使用,比如排序、分组、筛选
*/
#案例1:查询女神名和对应的男神名
SELECT NAME,boyName
FROM boys,beauty
WHERE beauty.boyfriend_id= boys.id;
#案例2:查询员工名和对应的部门名
SELECT last_name,department_name
FROM employees,departments
WHERE employees.`department_id`=departments.`department_id`;
#2、为表起别名
/*
①提高语句的简洁度
②区分多个重名的字段
注意:如果为表起了别名,则查询的字段就不能使用原来的表名去限定
*/
#查询员工名、工种号、工种名
SELECT e.last_name,e.job_id,j.job_title
FROM employees e,jobs j
WHERE e.`job_id`=j.`job_id`;
#3、两个表的顺序是否可以调换
#查询员工名、工种号、工种名
SELECT e.last_name,e.job_id,j.job_title
FROM jobs j,employees e
WHERE e.`job_id`=j.`job_id`;
#4、可以加筛选
#案例:查询有奖金的员工名、部门名
SELECT last_name,department_name,commission_pct
FROM employees e,departments d
WHERE e.`department_id`=d.`department_id`
AND e.`commission_pct` IS NOT NULL;
#案例2:查询城市名中第二个字符为o的部门名和城市名
SELECT department_name,city
FROM departments d,locations l
WHERE d.`location_id` = l.`location_id`
AND city LIKE '_o%';
#5、可以加分组
#案例1:查询每个城市的部门个数
SELECT COUNT(*) 个数,city
FROM departments d,locations l
WHERE d.`location_id`=l.`location_id`
GROUP BY city;
#案例2:查询有奖金的每个部门的部门名和部门的领导编号和该部门的最低工资
SELECT department_name,d.`manager_id`,MIN(salary)
FROM departments d,employees e
WHERE d.`department_id`=e.`department_id`
AND commission_pct IS NOT NULL
GROUP BY department_name,d.`manager_id`;
#6、可以加排序
#案例:查询每个工种的工种名和员工的个数,并且按员工个数降序
SELECT job_title,COUNT(*)
FROM employees e,jobs j
WHERE e.`job_id`=j.`job_id`
GROUP BY job_title
ORDER BY COUNT(*) DESC;
#7、可以实现三表连接?
#案例:查询员工名、部门名和所在的城市
SELECT last_name,department_name,city
FROM employees e,departments d,locations l
WHERE e.`department_id`=d.`department_id`
AND d.`location_id`=l.`location_id`
AND city LIKE 's%'
ORDER BY department_name DESC;
#2、非等值连接
#案例1:查询员工的工资和工资级别
SELECT salary,grade_level
FROM employees e,job_grades g
WHERE salary BETWEEN g.`lowest_sal` AND g.`highest_sal`
AND g.`grade_level`='A';
/*
select salary,employee_id from employees;
select * from job_grades;
CREATE TABLE job_grades
(grade_level VARCHAR(3),
lowest_sal int,
highest_sal int);
INSERT INTO job_grades
VALUES ('A', 1000, 2999);
INSERT INTO job_grades
VALUES ('B', 3000, 5999);
INSERT INTO job_grades
VALUES('C', 6000, 9999);
INSERT INTO job_grades
VALUES('D', 10000, 14999);
INSERT INTO job_grades
VALUES('E', 15000, 24999);
INSERT INTO job_grades
VALUES('F', 25000, 40000);
*/
#3、自连接
#案例:查询 员工名和上级的名称
SELECT e.employee_id,e.last_name,m.employee_id,m.last_name
FROM employees e,employees m
WHERE e.`manager_id`=m.`employee_id`;
案例
USE myemployees
SELECT last_name,d.department_id,department_name
FROM employees e,departments d
WHERE e.`department_id` = d.`department_id`
SELECT job_id,location_id
FROM employees e,departments d
WHERE e.`department_id`=d.`department_id`
AND e.`department_id`=90
last_name , department_name , location_id , city
SELECT last_name , department_name , l.location_id , city
FROM employees e,departments d,locations l
WHERE e.department_id = d.department_id
AND d.location_id=l.location_id
AND e.commission_pct IS NOT NULL
last_name , job_id , department_id , department_name
SELECT last_name , job_id , d.department_id , department_name
FROM employees e,departments d ,locations l
WHERE e.department_id = d.department_id
AND d.location_id=l.location_id
AND city = 'Toronto'
SELECT department_name,job_title,MIN(salary) 最低工资
FROM employees e,departments d,jobs j
WHERE e.`department_id`=d.`department_id`
AND e.`job_id`=j.`job_id`
GROUP BY department_name,job_title
bcc
SELECT country_id,COUNT(*) 部门个数
FROM departments d,locations l
WHERE d.`location_id`=l.`location_id`
GROUP BY country_id
HAVING 部门个数>2
employees Emp
kochhar 101 king 100
SELECT e.last_name employees,e.employee_id "Emp
FROM employees e,employees m
WHERE e.manager_id = m.employee_id
AND e.last_name='kochhar'
sql99语法的连接查询
语法:
select 查询列表
from 表1 别名 【连接类型】
join 表2 别名
on 连接条件
【where 筛选条件】
【group by 分组】
【having 筛选条件】
【order by 排序列表】
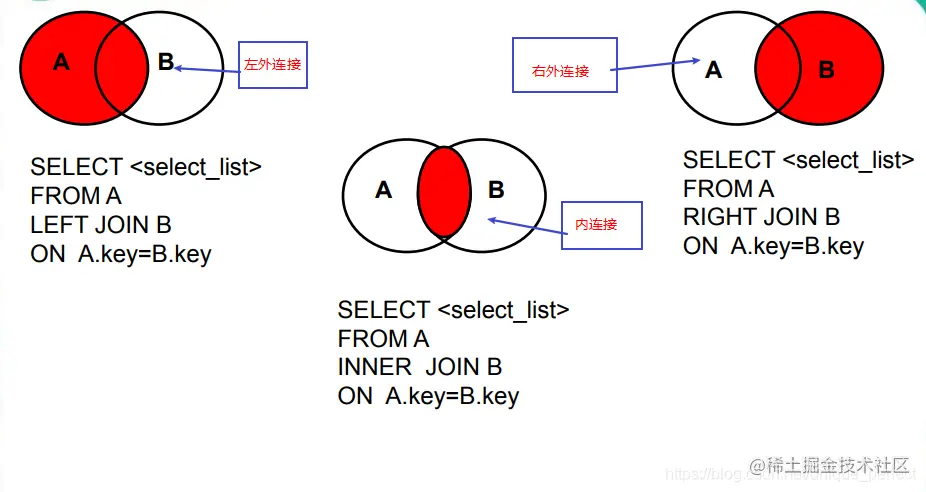
分类:
内连接(★):inner
外连接
左外(★):left 【outer】
右外(★):right 【outer】
全外:full【outer】
交叉连接:cross
*/
#一)内连接
/*
语法:
select 查询列表
from 表1 别名
inner join 表2 别名
on 连接条件;
分类:
等值
非等值
自连接
特点:
①添加排序、分组、筛选
②inner可以省略
③ 筛选条件放在where后面,连接条件放在on后面,提高分离性,便于阅读
④inner join连接和sql92语法中的等值连接效果是一样的,都是查询多表的交集
*/
#1、等值连接
#案例1.查询员工名、部门名
SELECT last_name,department_name
FROM departments d
JOIN employees e
ON e.`department_id` = d.`department_id`;
#案例2.查询名字中包含e的员工名和工种名(添加筛选)
SELECT last_name,job_title
FROM employees e
INNER JOIN jobs j
ON e.`job_id`= j.`job_id`
WHERE e.`last_name` LIKE '%e%';
#3. 查询部门个数>3的城市名和部门个数,(添加分组+筛选)
#①查询每个城市的部门个数
#②在①结果上筛选满足条件的
SELECT city,COUNT(*) 部门个数
FROM departments d
INNER JOIN locations l
ON d.`location_id`=l.`location_id`
GROUP BY city
HAVING COUNT(*)>3;
#案例4.查询哪个部门的员工个数>3的部门名和员工个数,并按个数降序(添加排序)
#①查询每个部门的员工个数
SELECT COUNT(*),department_name
FROM employees e
INNER JOIN departments d
ON e.`department_id`=d.`department_id`
GROUP BY department_name
#② 在①结果上筛选员工个数>3的记录,并排序
SELECT COUNT(*) 个数,department_name
FROM employees e
INNER JOIN departments d
ON e.`department_id`=d.`department_id`
GROUP BY department_name
HAVING COUNT(*)>3
ORDER BY COUNT(*) DESC;
#5.查询员工名、部门名、工种名,并按部门名降序(添加三表连接)
SELECT last_name,department_name,job_title
FROM employees e
INNER JOIN departments d ON e.`department_id`=d.`department_id`
INNER JOIN jobs j ON e.`job_id` = j.`job_id`
ORDER BY department_name DESC;
#二)非等值连接
#查询员工的工资级别
SELECT salary,grade_level
FROM employees e
JOIN job_grades g
ON e.`salary` BETWEEN g.`lowest_sal` AND g.`highest_sal`;
#查询工资级别的个数>20的个数,并且按工资级别降序
SELECT COUNT(*),grade_level
FROM employees e
JOIN job_grades g
ON e.`salary` BETWEEN g.`lowest_sal` AND g.`highest_sal`
GROUP BY grade_level
HAVING COUNT(*)>20
ORDER BY grade_level DESC;
#三)自连接
#查询员工的名字、上级的名字
SELECT e.last_name,m.last_name
FROM employees e
JOIN employees m
ON e.`manager_id`= m.`employee_id`;
#查询姓名中包含字符k的员工的名字、上级的名字
SELECT e.last_name,m.last_name
FROM employees e
JOIN employees m
ON e.`manager_id`= m.`employee_id`
WHERE e.`last_name` LIKE '%k%';
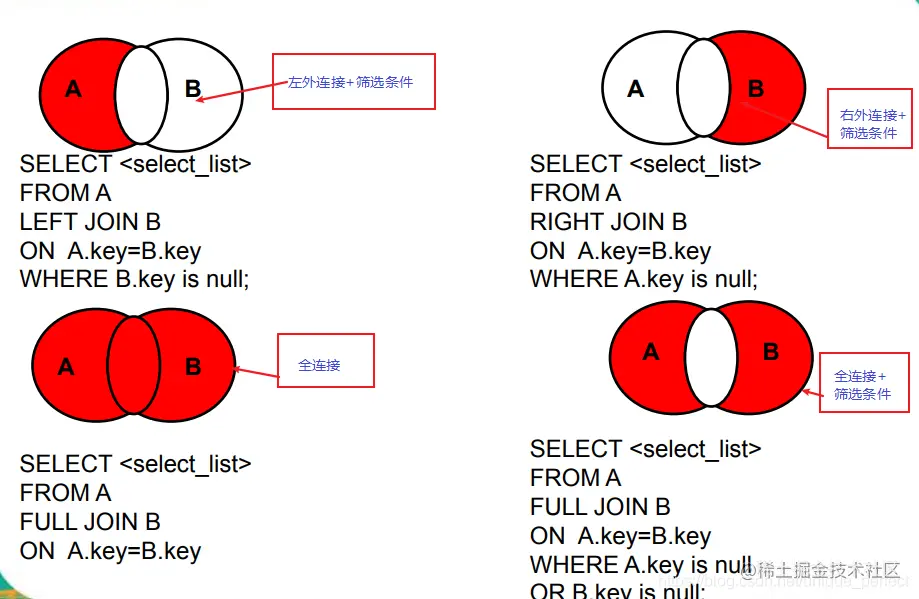
#二、外连接
/*
应用场景:用于查询一个表中有,另一个表没有的记录
特点:
1、外连接的查询结果为主表中的所有记录
如果从表中有和它匹配的,则显示匹配的值
如果从表中没有和它匹配的,则显示null
外连接查询结果=内连接结果+主表中有而从表没有的记录
2、左外连接,left join左边的是主表
右外连接,right join右边的是主表
3、左外和右外交换两个表的顺序,可以实现同样的效果
4、全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的
*/
#引入:查询男朋友 不在男神表的的女神名
SELECT * FROM beauty;
SELECT * FROM boys;
#左外连接
SELECT b.*,bo.*
FROM boys bo
LEFT OUTER JOIN beauty b
ON b.`boyfriend_id` = bo.`id`
WHERE b.`id` IS NULL;
#案例1:查询哪个部门没有员工
#左外
SELECT d.*,e.employee_id
FROM departments d
LEFT OUTER JOIN employees e
ON d.`department_id` = e.`department_id`
WHERE e.`employee_id` IS NULL;
#右外
SELECT d.*,e.employee_id
FROM employees e
RIGHT OUTER JOIN departments d
ON d.`department_id` = e.`department_id`
WHERE e.`employee_id` IS NULL;
#全外
USE girls;
SELECT b.*,bo.*
FROM beauty b
FULL OUTER JOIN boys bo
ON b.`boyfriend_id` = bo.id;
#交叉连接相当于92语法的笛卡尔乘积
SELECT b.*,bo.*
FROM beauty b
CROSS JOIN boys bo;
#sql92和 sql99pk
/*
功能:sql99支持的较多
可读性:sql99实现连接条件和筛选条件的分离,可读性较高
*/
多表连接
#一、查询编号>3的女神的男朋友信息,如果有则列出详细,如果没有,用null填充
SELECT b.id,b.name,bo.*
FROM beauty b
LEFT OUTER JOIN boys bo
ON b.`boyfriend_id` = bo.`id`
WHERE b.`id`>3;
#二、查询哪个城市没有部门
SELECT city
FROM departments d
RIGHT OUTER JOIN locations l
ON d.`location_id`=l.`location_id`
WHERE d.`department_id` IS NULL;
#三、查询部门名为SAL或IT的员工信息
SELECT e.*,d.department_name,d.`department_id`
FROM departments d
LEFT JOIN employees e
ON d.`department_id` = e.`department_id`
WHERE d.`department_name` IN('SAL','IT');
SELECT * FROM departments
WHERE `department_name` IN('SAL','IT');
join连接总结
子查询
/*
含义:
出现在其他语句中的select语句,称为子查询或内查询
外部的查询语句,称为主查询或外查询
分类:
按子查询出现的位置:
select后面:
仅仅支持标量子查询
from后面:
支持表子查询
where或having后面:★
标量子查询(单行) √
列子查询 (多行) √
行子查询
exists后面(相关子查询)
表子查询
按结果集的行列数不同:
标量子查询(结果集只有一行一列)
列子查询(结果集只有一列多行)
行子查询(结果集有一行多列)
表子查询(结果集一般为多行多列)
*/
/*
1、标量子查询(单行子查询)
2、列子查询(多行子查询)
3、行子查询(多列多行)
特点:
①子查询放在小括号内
②子查询一般放在条件的右侧
③标量子查询,一般搭配着单行操作符使用
> < >= <= = <>
列子查询,一般搭配着多行操作符使用
in、any/some、all
④子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果
*/
SELECT salary
FROM employees
WHERE last_name = 'Abel'
SELECT *
FROM employees
WHERE salary>(
SELECT salary
FROM employees
WHERE last_name = 'Abel'
)
SELECT job_id
FROM employees
WHERE employee_id = 141
SELECT salary
FROM employees
WHERE employee_id = 143
SELECT last_name,job_id,salary
FROM employees
WHERE job_id = (
SELECT job_id
FROM employees
WHERE employee_id = 141
) AND salary>(
SELECT salary
FROM employees
WHERE employee_id = 143
)
SELECT MIN(salary)
FROM employees
SELECT last_name,job_id,salary
FROM employees
WHERE salary=(
SELECT MIN(salary)
FROM employees
)
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
SELECT MIN(salary),department_id
FROM employees
GROUP BY department_id
SELECT MIN(salary),department_id
FROM employees
GROUP BY department_id
HAVING MIN(salary)>(
SELECT MIN(salary)
FROM employees
WHERE department_id = 50
)
SELECT MIN(salary),department_id
FROM employees
GROUP BY department_id
HAVING MIN(salary)>(
SELECT salary
FROM employees
WHERE department_id = 250
)
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
SELECT last_name
FROM employees
WHERE department_id <>ALL(
SELECT DISTINCT department_id
FROM departments
WHERE location_id IN(1400,1700)
)
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
SELECT last_name,employee_id,job_id,salary
FROM employees
WHERE salary<ANY(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
) AND job_id<>'IT_PROG'
SELECT last_name,employee_id,job_id,salary
FROM employees
WHERE salary<(
SELECT MAX(salary)
FROM employees
WHERE job_id = 'IT_PROG'
) AND job_id<>'IT_PROG'
SELECT last_name,employee_id,job_id,salary
FROM employees
WHERE salary<ALL(
SELECT DISTINCT salary
FROM employees
WHERE job_id = 'IT_PROG'
) AND job_id<>'IT_PROG'
SELECT last_name,employee_id,job_id,salary
FROM employees
WHERE salary<(
SELECT MIN( salary)
FROM employees
WHERE job_id = 'IT_PROG'
) AND job_id<>'IT_PROG'
SELECT *
FROM employees
WHERE (employee_id,salary)=(
SELECT MIN(employee_id),MAX(salary)
FROM employees
)
SELECT MIN(employee_id)
FROM employees
SELECT MAX(salary)
FROM employees
SELECT *
FROM employees
WHERE employee_id=(
SELECT MIN(employee_id)
FROM employees
)AND salary=(
SELECT MAX(salary)
FROM employees
)
/*
仅仅支持标量子查询
*/
SELECT d.*,(
SELECT COUNT(*)
FROM employees e
WHERE e.department_id = d.`department_id`
) 个数
FROM departments d
SELECT (
SELECT department_name,e.department_id
FROM departments d
INNER JOIN employees e
ON d.department_id=e.department_id
WHERE e.employee_id=102
) 部门名
/*
将子查询结果充当一张表,要求必须起别名
*/
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
SELECT * FROM job_grades
SELECT ag_dep.*,g.`grade_level`
FROM (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
) ag_dep
INNER JOIN job_grades g
ON ag_dep.ag BETWEEN lowest_sal AND highest_sal
/*
语法:
exists(完整的查询语句)
结果:
1或0
*/
SELECT EXISTS(SELECT employee_id FROM employees WHERE salary=300000)
SELECT department_name
FROM departments d
WHERE d.`department_id` IN(
SELECT department_id
FROM employees
)
SELECT department_name
FROM departments d
WHERE EXISTS(
SELECT *
FROM employees e
WHERE d.`department_id`=e.`department_id`
)
SELECT bo.*
FROM boys bo
WHERE bo.id NOT IN(
SELECT boyfriend_id
FROM beauty
)
SELECT bo.*
FROM boys bo
WHERE NOT EXISTS(
SELECT boyfriend_id
FROM beauty b
WHERE bo.`id`=b.`boyfriend_id`
)
案例
SELECT department_id
FROM employees
WHERE last_name = 'Zlotkey'
SELECT last_name,salary
FROM employees
WHERE department_id = (
SELECT department_id
FROM employees
WHERE last_name = 'Zlotkey'
)
SELECT AVG(salary)
FROM employees
SELECT last_name,employee_id,salary
FROM employees
WHERE salary>(
SELECT AVG(salary)
FROM employees
)
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
SELECT employee_id,last_name,salary,e.department_id
FROM employees e
INNER JOIN (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
) ag_dep
ON e.department_id = ag_dep.department_id
WHERE salary>ag_dep.ag
SELECT DISTINCT department_id
FROM employees
WHERE last_name LIKE '%u%'
SELECT last_name,employee_id
FROM employees
WHERE department_id IN(
SELECT DISTINCT department_id
FROM employees
WHERE last_name LIKE '%u%'
)
SELECT DISTINCT department_id
FROM departments
WHERE location_id = 1700
SELECT employee_id
FROM employees
WHERE department_id =ANY(
SELECT DISTINCT department_id
FROM departments
WHERE location_id = 1700
)
SELECT employee_id
FROM employees
WHERE last_name = 'K_ing'
SELECT last_name,salary
FROM employees
WHERE manager_id IN(
SELECT employee_id
FROM employees
WHERE last_name = 'K_ing'
)
SELECT MAX(salary)
FROM employees
SELECT CONCAT(first_name,last_name) "姓.名"
FROM employees
WHERE salary=(
SELECT MAX(salary)
FROM employees
)
子查询经典案例
# 1. 查询工资最低的员工信息: last_name, salary
#①查询最低的工资
SELECT MIN(salary)
FROM employees
#②查询last_name,salary,要求salary=①
SELECT last_name,salary
FROM employees
WHERE salary=(
SELECT MIN(salary)
FROM employees
);
# 2. 查询平均工资最低的部门信息
#方式一:
#①各部门的平均工资
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
#②查询①结果上的最低平均工资
SELECT MIN(ag)
FROM (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
) ag_dep
#③查询哪个部门的平均工资=②
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary)=(
SELECT MIN(ag)
FROM (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
) ag_dep
);
#④查询部门信息
SELECT d.*
FROM departments d
WHERE d.`department_id`=(
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary)=(
SELECT MIN(ag)
FROM (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
) ag_dep
)
);
#方式二:
#①各部门的平均工资
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
#②求出最低平均工资的部门编号
SELECT department_id
FROM employees
GROUP BY department_id
ORDER BY AVG(salary)
LIMIT 1;
#③查询部门信息
SELECT *
FROM departments
WHERE department_id=(
SELECT department_id
FROM employees
GROUP BY department_id
ORDER BY AVG(salary)
LIMIT 1
);
# 3. 查询平均工资最低的部门信息和该部门的平均工资
#①各部门的平均工资
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
#②求出最低平均工资的部门编号
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
ORDER BY AVG(salary)
LIMIT 1;
#③查询部门信息
SELECT d.*,ag
FROM departments d
JOIN (
SELECT AVG(salary) ag,department_id
FROM employees
GROUP BY department_id
ORDER BY AVG(salary)
LIMIT 1
) ag_dep
ON d.`department_id`=ag_dep.department_id;
# 4. 查询平均工资最高的 job 信息
#①查询最高的job的平均工资
SELECT AVG(salary),job_id
FROM employees
GROUP BY job_id
ORDER BY AVG(salary) DESC
LIMIT 1
#②查询job信息
SELECT *
FROM jobs
WHERE job_id=(
SELECT job_id
FROM employees
GROUP BY job_id
ORDER BY AVG(salary) DESC
LIMIT 1
);
# 5. 查询平均工资高于公司平均工资的部门有哪些?
#①查询平均工资
SELECT AVG(salary)
FROM employees
#②查询每个部门的平均工资
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
#③筛选②结果集,满足平均工资>①
SELECT AVG(salary),department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary)>(
SELECT AVG(salary)
FROM employees
);
# 6. 查询出公司中所有 manager 的详细信息.
#①查询所有manager的员工编号
SELECT DISTINCT manager_id
FROM employees
#②查询详细信息,满足employee_id=①
SELECT *
FROM employees
WHERE employee_id =ANY(
SELECT DISTINCT manager_id
FROM employees
);
# 7. 各个部门中 最高工资中最低的那个部门的 最低工资是多少
#①查询各部门的最高工资中最低的部门编号
SELECT department_id
FROM employees
GROUP BY department_id
ORDER BY MAX(salary)
LIMIT 1
#②查询①结果的那个部门的最低工资
SELECT MIN(salary) ,department_id
FROM employees
WHERE department_id=(
SELECT department_id
FROM employees
GROUP BY department_id
ORDER BY MAX(salary)
LIMIT 1
);
# 8. 查询平均工资最高的部门的 manager 的详细信息: last_name, department_id, email, salary
#①查询平均工资最高的部门编号
SELECT
department_id
FROM
employees
GROUP BY department_id
ORDER BY AVG(salary) DESC
LIMIT 1
#②将employees和departments连接查询,筛选条件是①
SELECT
last_name, d.department_id, email, salary
FROM
employees e
INNER JOIN departments d
ON d.manager_id = e.employee_id
WHERE d.department_id =
(SELECT
department_id
FROM
employees
GROUP BY department_id
ORDER BY AVG(salary) DESC
LIMIT 1) ;
分页查询
#进阶8:分页查询 ★
/*
应用场景:当要显示的数据,一页显示不全,需要分页提交sql请求
语法:
select 查询列表
from 表
【join type join 表2
on 连接条件
where 筛选条件
group by 分组字段
having 分组后的筛选
order by 排序的字段】
limit 【offset,】size;
offset要显示条目的起始索引(起始索引从0开始)
size 要显示的条目个数
特点:
①limit语句放在查询语句的最后
②公式
要显示的页数 page,每页的条目数size
select 查询列表
from 表
limit (page-1)*size,size;
size=10
page
1 0
2 10
3 20
*/
#案例1:查询前五条员工信息
SELECT * FROM employees LIMIT 0,5;
SELECT * FROM employees LIMIT 5;
#案例2:查询第11条——第25条
SELECT * FROM employees LIMIT 10,15;
#案例3:有奖金的员工信息,并且工资较高的前10名显示出来
SELECT
*
FROM
employees
WHERE commission_pct IS NOT NULL
ORDER BY salary DESC
LIMIT 10 ;
联合查询
/*
union 联合 合并:将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
union
...
应用场景:
要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时
特点:★
1、要求多条查询语句的查询列数是一致的!
2、要求多条查询语句的查询的每一列的类型和顺序最好一致
3、union关键字默认去重,如果使用union all 可以包含重复项
*/
#引入的案例:查询部门编号>90或邮箱包含a的员工信息
SELECT * FROM employees WHERE email LIKE '%a%' OR department_id>90;;
SELECT * FROM employees WHERE email LIKE '%a%'
UNION
SELECT * FROM employees WHERE department_id>90;
#案例:查询中国用户中男性的信息以及外国用户中年男性的用户信息
SELECT id,cname FROM t_ca WHERE csex='男'
UNION ALL
SELECT t_id,tname FROM t_ua WHERE tGender='male';
select语句总结
from 表名
where …….
group by ……..
having …….(就是为了过滤分组后的数据而存在的—不可以单独的出现)
order by ……..
以上语句的执行顺序
1.首先执行where语句过滤原始数据
2.执行group by进行分组
3.执行having对分组数据进行操作
4.执行select选出数据
5.执行order by排序
注意:原则:能在where中过滤的数据,尽量在where中过滤,效率较高.
having的过滤是专门对分组之后的数据进行过滤的。
数据的增删改
#DML语言
#一、插入语句
#方式一:经典的插入
SELECT * FROM beauty;
#1.插入的值的类型要与列的类型一致或兼容
INSERT INTO beauty(id,NAME,sex,borndate,phone,photo,boyfriend_id)
VALUES(13,'唐艺昕','女','1990-4-23','1898888888',NULL,2);
#2.不可以为null的列必须插入值。可以为null的列如何插入值?
#方式一:
INSERT INTO beauty(id,NAME,sex,borndate,phone,photo,boyfriend_id)
VALUES(13,'唐艺昕','女','1990-4-23','1898888888',NULL,2);
#方式二:
INSERT INTO beauty(id,NAME,sex,phone)
VALUES(15,'娜扎','女','1388888888');
#3.列的顺序是否可以调换
INSERT INTO beauty(NAME,sex,id,phone)
VALUES('蒋欣','女',16,'110');
#4.列数和值的个数必须一致
INSERT INTO beauty(NAME,sex,id,phone)
VALUES('关晓彤','女',17,'110');
#5.可以省略列名,默认所有列,而且列的顺序和表中列的顺序一致
INSERT INTO beauty
VALUES(18,'张飞','男',NULL,'119',NULL,NULL);
#方式二:
INSERT INTO beauty
SET id=19,NAME='刘涛',phone='999';
#两种方式大pk ★
#1、方式一支持插入多行,方式二不支持
INSERT INTO beauty
VALUES(23,'唐艺昕1','女','1990-4-23','1898888888',NULL,2)
,(24,'唐艺昕2','女','1990-4-23','1898888888',NULL,2)
,(25,'唐艺昕3','女','1990-4-23','1898888888',NULL,2);
#2、方式一支持子查询,方式二不支持
INSERT INTO beauty(id,NAME,phone)
SELECT 26,'宋茜','11809866';
INSERT INTO beauty(id,NAME,phone)
SELECT id,boyname,'1234567'
FROM boys WHERE id<3;
#二、修改语句
#1.修改单表的记录
#案例1:修改beauty表中姓唐的女神的电话为13899888899
UPDATE beauty SET phone = '13899888899'
WHERE NAME LIKE '唐%';
#案例2:修改boys表中id好为2的名称为张飞,魅力值 10
UPDATE boys SET boyname='张飞',usercp=10
WHERE id=2;
#2.修改多表的记录
#案例 1:修改张无忌的女朋友的手机号为114
UPDATE boys bo
INNER JOIN beauty b ON bo.`id`=b.`boyfriend_id`
SET b.`phone`='119',bo.`userCP`=1000
WHERE bo.`boyName`='张无忌';
#案例2:修改没有男朋友的女神的男朋友编号都为2号
UPDATE boys bo
RIGHT JOIN beauty b ON bo.`id`=b.`boyfriend_id`
SET b.`boyfriend_id`=2
WHERE bo.`id` IS NULL;
SELECT * FROM boys;
#三、删除语句
#方式一:delete
#1.单表的删除
#案例:删除手机号以9结尾的女神信息
DELETE FROM beauty WHERE phone LIKE '%9';
SELECT * FROM beauty;
#2.多表的删除
#案例:删除张无忌的女朋友的信息
DELETE b
FROM beauty b
INNER JOIN boys bo ON b.`boyfriend_id` = bo.`id`
WHERE bo.`boyName`='张无忌';
#案例:删除黄晓明的信息以及他女朋友的信息
DELETE b,bo
FROM beauty b
INNER JOIN boys bo ON b.`boyfriend_id`=bo.`id`
WHERE bo.`boyName`='黄晓明';
#方式二:truncate语句
#案例:将魅力值>100的男神信息删除
TRUNCATE TABLE boys ;
#delete pk truncate【面试题★】
SELECT * FROM boys;
DELETE FROM boys;
TRUNCATE TABLE boys;
INSERT INTO boys (boyname,usercp)
VALUES('张飞',100),('刘备',100),('关云长',100);
案例数据的增删改
#1. 运行以下脚本创建表my_employees
USE myemployees;
CREATE TABLE my_employees(
Id INT(10),
First_name VARCHAR(10),
Last_name VARCHAR(10),
Userid VARCHAR(10),
Salary DOUBLE(10,2)
);
CREATE TABLE users(
id INT,
userid VARCHAR(10),
department_id INT
);
#2. 显示表my_employees的结构
DESC my_employees;
#3. 向my_employees表中插入下列数据
ID FIRST_NAME LAST_NAME USERID SALARY
1 patel Ralph Rpatel 895
2 Dancs Betty Bdancs 860
3 Biri Ben Bbiri 1100
4 Newman Chad Cnewman 750
5 Ropeburn Audrey Aropebur 1550
#方式一:
INSERT INTO my_employees
VALUES(1,'patel','Ralph','Rpatel',895),
(2,'Dancs','Betty','Bdancs',860),
(3,'Biri','Ben','Bbiri',1100),
(4,'Newman','Chad','Cnewman',750),
(5,'Ropeburn','Audrey','Aropebur',1550);
DELETE FROM my_employees;
#方式二:
INSERT INTO my_employees
SELECT 1,'patel','Ralph','Rpatel',895 UNION
SELECT 2,'Dancs','Betty','Bdancs',860 UNION
SELECT 3,'Biri','Ben','Bbiri',1100 UNION
SELECT 4,'Newman','Chad','Cnewman',750 UNION
SELECT 5,'Ropeburn','Audrey','Aropebur',1550;
#4. 向users表中插入数据
1 Rpatel 10
2 Bdancs 10
3 Bbiri 20
4 Cnewman 30
5 Aropebur 40
INSERT INTO users
VALUES(1,'Rpatel',10),
(2,'Bdancs',10),
(3,'Bbiri',20);
#5.将3号员工的last_name修改为“drelxer”
UPDATE my_employees SET last_name='drelxer' WHERE id = 3;
#6.将所有工资少于900的员工的工资修改为1000
UPDATE my_employees SET salary=1000 WHERE salary<900;
#7.将userid 为Bbiri的user表和my_employees表的记录全部删除
DELETE u,e
FROM users u
JOIN my_employees e ON u.`userid`=e.`Userid`
WHERE u.`userid`='Bbiri';
#8.删除所有数据
DELETE FROM my_employees;
DELETE FROM users;
#9.检查所作的修正
SELECT * FROM my_employees;
SELECT * FROM users;
#10.清空表my_employees
TRUNCATE TABLE my_employees;
库和表的管理
/*
数据定义语言
库和表的管理
一、库的管理
创建、修改、删除
二、表的管理
创建、修改、删除
创建: create
修改: alter
删除: drop
*/
#一、库的管理
#1、库的创建
/*
语法:
create database [if not exists]库名;
*/
#案例:创建库Books
CREATE DATABASE IF NOT EXISTS books ;
#2、库的修改
RENAME DATABASE books TO 新库名;
#更改库的字符集
ALTER DATABASE books CHARACTER SET gbk;
#3、库的删除
DROP DATABASE IF EXISTS books;
#二、表的管理
#1.表的创建 ★
/*
语法:
create table 表名(
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
...
列名 列的类型【(长度) 约束】
)
*/
#案例:创建表Book
CREATE TABLE book(
id INT,#编号
bName VARCHAR(20),#图书名
price DOUBLE,#价格
authorId INT,#作者编号
publishDate DATETIME#出版日期
);
DESC book;
#案例:创建表author
CREATE TABLE IF NOT EXISTS author(
id INT,
au_name VARCHAR(20),
nation VARCHAR(10)
)
DESC author;
#2.表的修改
/*
语法
alter table 表名 add|drop|modify|change column 列名 【列类型 约束】;
*/
#①修改列名
ALTER TABLE book CHANGE COLUMN publishdate pubDate DATETIME;
#②修改列的类型或约束
ALTER TABLE book MODIFY COLUMN pubdate TIMESTAMP;
#③添加新列
ALTER TABLE author ADD COLUMN annual DOUBLE;
#④删除列
ALTER TABLE book_author DROP COLUMN annual;
#⑤修改表名
ALTER TABLE author RENAME TO book_author;
DESC book;
#3.表的删除
DROP TABLE IF EXISTS book_author;
SHOW TABLES;
#通用的写法:
DROP DATABASE IF EXISTS 旧库名;
CREATE DATABASE 新库名;
DROP TABLE IF EXISTS 旧表名;
CREATE TABLE 表名();
#4.表的复制
INSERT INTO author VALUES
(1,'村上春树','日本'),
(2,'莫言','中国'),
(3,'冯唐','中国'),
(4,'金庸','中国');
SELECT * FROM Author;
SELECT * FROM copy2;
#1.仅仅复制表的结构
CREATE TABLE copy LIKE author;
#2.复制表的结构+数据
CREATE TABLE copy2
SELECT * FROM author;
#只复制部分数据
CREATE TABLE copy3
SELECT id,au_name
FROM author
WHERE nation='中国';
#仅仅复制某些字段
CREATE TABLE copy4
SELECT id,au_name
FROM author
WHERE 0;
案例库和表的管理
#1. 创建表dept1
NAME NULL? TYPE
id INT(7)
NAME VARCHAR(25)
USE test;
CREATE TABLE dept1(
id INT(7),
NAME VARCHAR(25)
);
#2. 将表departments中的数据插入新表dept2中
CREATE TABLE dept2
SELECT department_id,department_name
FROM myemployees.departments;
#3. 创建表emp5
NAME NULL? TYPE
id INT(7)
First_name VARCHAR (25)
Last_name VARCHAR(25)
Dept_id INT(7)
CREATE TABLE emp5(
id INT(7),
first_name VARCHAR(25),
last_name VARCHAR(25),
dept_id INT(7)
);
#4. 将列Last_name的长度增加到50
ALTER TABLE emp5 MODIFY COLUMN last_name VARCHAR(50);
#5. 根据表employees创建employees2
CREATE TABLE employees2 LIKE myemployees.employees;
#6. 删除表emp5
DROP TABLE IF EXISTS emp5;
#7. 将表employees2重命名为emp5
ALTER TABLE employees2 RENAME TO emp5;
#8.在表dept和emp5中添加新列test_column,并检查所作的操作
ALTER TABLE emp5 ADD COLUMN test_column INT;
#9.直接删除表emp5中的列 dept_id
DESC emp5;
ALTER TABLE emp5 DROP COLUMN test_column;
数据类型
#常见的数据类型
#一、整型
#1.如何设置无符号和有符号
DROP TABLE IF EXISTS tab_int;
CREATE TABLE tab_int(
t1 INT(7) ZEROFILL,
t2 INT(7) ZEROFILL
);
DESC tab_int;
INSERT INTO tab_int VALUES(-123456);
INSERT INTO tab_int VALUES(-123456,-123456);
INSERT INTO tab_int VALUES(2147483648,4294967296);
INSERT INTO tab_int VALUES(123,123);
SELECT * FROM tab_int;
#二、小数
#测试M和D
DROP TABLE tab_float;
CREATE TABLE tab_float(
f1 FLOAT,
f2 DOUBLE,
f3 DECIMAL
);
SELECT * FROM tab_float;
DESC tab_float;
INSERT INTO tab_float VALUES(123.4523,123.4523,123.4523);
INSERT INTO tab_float VALUES(123.456,123.456,123.456);
INSERT INTO tab_float VALUES(123.4,123.4,123.4);
INSERT INTO tab_float VALUES(1523.4,1523.4,1523.4);
#原则:
#三、字符型
CREATE TABLE tab_char(
c1 ENUM('a','b','c')
);
INSERT INTO tab_char VALUES('a');
INSERT INTO tab_char VALUES('b');
INSERT INTO tab_char VALUES('c');
INSERT INTO tab_char VALUES('m');
INSERT INTO tab_char VALUES('A');
SELECT * FROM tab_set;
CREATE TABLE tab_set(
s1 SET('a','b','c','d')
);
INSERT INTO tab_set VALUES('a');
INSERT INTO tab_set VALUES('A,B');
INSERT INTO tab_set VALUES('a,c,d');
#四、日期型
CREATE TABLE tab_date(
t1 DATETIME,
t2 TIMESTAMP
);
INSERT INTO tab_date VALUES(NOW(),NOW());
SELECT * FROM tab_date;
SHOW VARIABLES LIKE 'time_zone';
SET time_zone='+9:00';
常见约束
#常见约束
CREATE TABLE 表名(
字段名 字段类型 列级约束,
字段名 字段类型,
表级约束
)
CREATE DATABASE students;
#一、创建表时添加约束
#1.添加列级约束
USE students;
DROP TABLE stuinfo;
CREATE TABLE stuinfo(
id INT PRIMARY KEY,#主键
stuName VARCHAR(20) NOT NULL UNIQUE,#非空
gender CHAR(1) CHECK(gender='男' OR gender ='女'),#检查
seat INT UNIQUE,#唯一
age INT DEFAULT 18,#默认约束
majorId INT REFERENCES major(id)#外键
);
CREATE TABLE major(
id INT PRIMARY KEY,
majorName VARCHAR(20)
);
#查看stuinfo中的所有索引,包括主键、外键、唯一
SHOW INDEX FROM stuinfo;
#2.添加表级约束
DROP TABLE IF EXISTS stuinfo;
CREATE TABLE stuinfo(
id INT,
stuname VARCHAR(20),
gender CHAR(1),
seat INT,
age INT,
majorid INT,
CONSTRAINT pk PRIMARY KEY(id),#主键
CONSTRAINT uq UNIQUE(seat),#唯一键
CONSTRAINT ck CHECK(gender ='男' OR gender = '女'),#检查
CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id)#外键
);
SHOW INDEX FROM stuinfo;
#通用的写法:★
CREATE TABLE IF NOT EXISTS stuinfo(
id INT PRIMARY KEY,
stuname VARCHAR(20),
sex CHAR(1),
age INT DEFAULT 18,
seat INT UNIQUE,
majorid INT,
CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id)
);
#二、修改表时添加约束
DROP TABLE IF EXISTS stuinfo;
CREATE TABLE stuinfo(
id INT,
stuname VARCHAR(20),
gender CHAR(1),
seat INT,
age INT,
majorid INT
)
DESC stuinfo;
#1.添加非空约束
ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NOT NULL;
#2.添加默认约束
ALTER TABLE stuinfo MODIFY COLUMN age INT DEFAULT 18;
#3.添加主键
#①列级约束
ALTER TABLE stuinfo MODIFY COLUMN id INT PRIMARY KEY;
#②表级约束
ALTER TABLE stuinfo ADD PRIMARY KEY(id);
#4.添加唯一
#①列级约束
ALTER TABLE stuinfo MODIFY COLUMN seat INT UNIQUE;
#②表级约束
ALTER TABLE stuinfo ADD UNIQUE(seat);
#5.添加外键
ALTER TABLE stuinfo ADD CONSTRAINT fk_stuinfo_major FOREIGN KEY(majorid) REFERENCES major(id);
#三、修改表时删除约束
#1.删除非空约束
ALTER TABLE stuinfo MODIFY COLUMN stuname VARCHAR(20) NULL;
#2.删除默认约束
ALTER TABLE stuinfo MODIFY COLUMN age INT ;
#3.删除主键
ALTER TABLE stuinfo DROP PRIMARY KEY;
#4.删除唯一
ALTER TABLE stuinfo DROP INDEX seat;
#5.删除外键
ALTER TABLE stuinfo DROP FOREIGN KEY fk_stuinfo_major;
SHOW INDEX FROM stuinfo;
# 方式一: 级联删除
# 效果: 两个表中的数据都删除掉
ALTER TABLE stuinfo ADD CONSTRAINT fk_stu_major FOREIGN KEY(majorid) REFERENCES major(id) ON DELETE CASCADE;
# 方式二: 级联置空
ALTER TABLE stuinfo ADD CONSTRAINT fk_stu_major FOREIGN KEY(majorid) REFERENCES major(id) ON DELETE SET NULL;
# 效果: 主表数据删除,外表相关字段置空
案例常见约束
#1.向表emp2的id列中添加PRIMARY KEY约束(my_emp_id_pk)
ALTER TABLE emp2 MODIFY COLUMN id INT PRIMARY KEY;
ALTER TABLE emp2 ADD CONSTRAINT my_emp_id_pk PRIMARY KEY(id);
#2. 向表dept2的id列中添加PRIMARY KEY约束(my_dept_id_pk)
#3. 向表emp2中添加列dept_id,并在其中定义FOREIGN KEY约束,与之相关联的列是dept2表中的id列。
ALTER TABLE emp2 ADD COLUMN dept_id INT;
ALTER TABLE emp2 ADD CONSTRAINT fk_emp2_dept2 FOREIGN KEY(dept_id) REFERENCES dept2(id);
位置 支持的约束类型 是否可以起约束名
列级约束: 列的后面 语法都支持,但外键没有效果 不可以
表级约束: 所有列的下面 默认和非空不支持,其他支持 可以(主键没有效果)
#标识列
#一、创建表时设置标识列
DROP TABLE IF EXISTS tab_identity;
CREATE TABLE tab_identity(
id INT ,
NAME FLOAT UNIQUE AUTO_INCREMENT,
seat INT
);
TRUNCATE TABLE tab_identity;
INSERT INTO tab_identity(id,NAME) VALUES(NULL,'john');
INSERT INTO tab_identity(NAME) VALUES('lucy');
SELECT * FROM tab_identity;
SHOW VARIABLES LIKE '%auto_increment%';
SET auto_increment_increment=3;
#二、修改表时设置标识列
ALTER TABLE tab_identity MODIFY COLUMN id INT PRIMARY KEY AUTO_INCREMENT;
# 三、修改表时删除标识列
ALTER TABLE tab_identity MODIFY COLUMN id INT;


