


- 原文地址:Advanced Python: How To Implement Caching In Python Application
- 原文作者:Farhad Malik
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:jaredliw
- 校对者:KimYangOfCat、greycodee
Python 进阶:如何在 Python 应用中实现缓存
缓存对每一个 Python 程序员来说都是一个值得理解的重要概念。
简而言之,缓存就是利用编程技术将数据存储在临时位置,而不是每次都从源数据去检索。
此外,缓存能提升应用程序的性能,因为从临时位置访问数据总比从源数据(数据库,服务器等)获取来得快。
本篇文章主要探讨缓存在 Python 中是如何运作的。这对 Python 开发者来说是一个进阶的话题。如果你正在使用 Python 或打算使用它,那么你非常适合阅读本篇文章。
如果你想从入门到进阶地了解 Python 程序语言,那么我强烈推荐你阅读这篇文章。
文章主旨
在这篇文章中,我会解释缓存是什么,我们为什么需要缓存以及如何在 Python 中实现它。
当我们想要提高应用程序的性能时,就可以用到缓存。
我将概述以下三个关键点:
- 什么是缓存以及为什么我们需要实现缓存?
- 缓存的规则是什么?
- 如何实现缓存?
我将首先解释什么是缓存,为什么我们需要在我们的应用程序中引入缓存,以及如何实现缓存。
1. 什么是缓存以及为什么我们需要实现缓存?
要想了解缓存是什么以及我们为什么需要缓存,试考虑以下场景:
- 我们正在用 Python 构建一个应用程序,它将向终端用户展示产品列表。
- 每天将有超过 100 个用户多次访问此应用程序。
- 该应用程序将托管在应用程序服务器上,并可在互联网上访问。
- 产品的资料将存储在数据库服务器中。
- 因此应用程序服务器将查询数据库以获取相关记录。
下图展示了我们的目标应用程序是如何配置的:
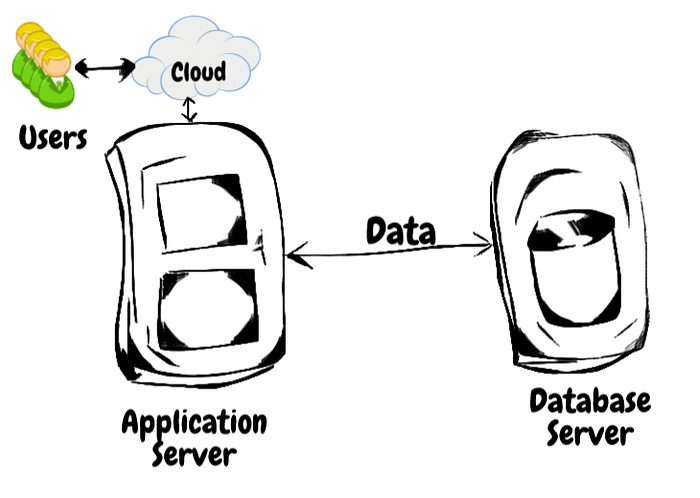
上图说明了应用程序服务器如何从数据库服务器获取数据。
问题
从数据库中获取数据是一个 I/O 密集型的操作。因此,它本质上是缓慢的。如果服务端需要频繁地发送请求但服务器响应跟不上请求的速度,那么我们可以将响应缓存在应用程序的内存中。
与其每次都查询数据库,我们可以将结果缓存,如下所示:
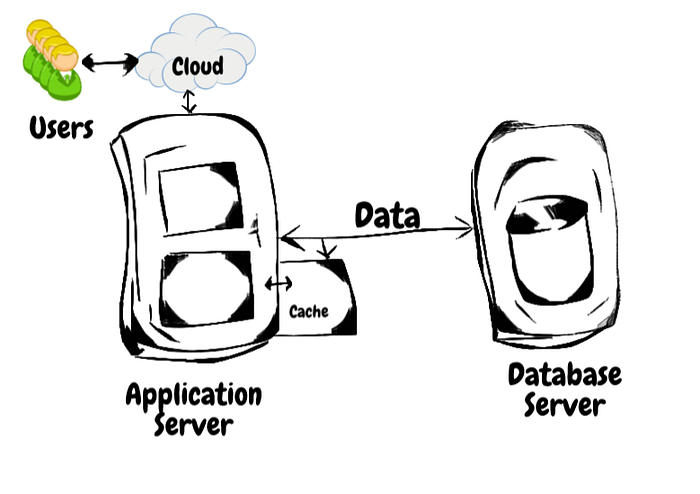
获取数据的请求必须通过网线,响应也必须通过网线返回。
这本质上是缓慢的。因此,我们引入了缓存。
我们可以缓存结果以减少运算时间并节省计算机资源。
缓存是一个临时存储位置。它以惰性载入的方式工作。
一开始,缓存是空的。当应用程序服务器从数据库服务器获取数据时,数据集将填充缓存。从那以后,后续的请求便能直接从缓存中获取数据。
我们还需要及时使缓存失效,以确保我们向终端用户显示最新信息。
本文的下一部分:缓存规则。
2. 缓存规则
在我看来,缓存有三个规则。
在启用缓存之前,我们需要执行一个关键步骤 —— 分析应用程序。
因此,在应用程序中引入缓存之前的第一步是分析应用程序。
只有这样我们才能了解每个函数需要执行多长时间以及它被调用了多少次。
我在这篇文章中解释了分析的艺术,我强烈将它推荐给大家。
分析完成后,我们需要确定需要缓存的内容。
我们需要一种能将输入链接到函数的输出的机制,并将它们存储在内存中。这就是缓存的第一条规则。
2.1. 第一条规则:
第一条规则是确保目标函数确实需要很长时间才能返回输出,且它会频繁被执行但输出的更动不大。
我们不想为不需要很长时间才能完成的函数,或几乎不会在应用程序中调用的函数,或那些返回结果在源中频繁更改的函数引入缓存。
请牢记这条重要的规则。
适合缓存的候选 = 经常调用的函数,输出不经常变化并且需要很长时间执行。
举例来说,如果一个函数被执行了 100 次,且该函数需要很长时间才能返回结果,并且它为给定的输入返回相同的结果,那么我们可以缓存它。
相反,如果函数返回的值在源中每秒更新一次,但我们每分钟才收到一个执行该函数的请求,那么我们得明白是否需要缓存这样的结果。这非常重要,因为这可能导致应用发送过时的数据给用户。这个例子可以帮助我们明白是否需要缓存,是否需要不同的通信通道、数据结构或序列化机制来更快地检索数据,例如通过 socket 使用二进制序列化器还是通过 HTTP 的 XML 序列化发送数据。
此外,知道何时使缓存失效并重新加载新数据到缓存也是非常重要的。
2.2. 第二条规则:
第二条规则是确保从缓存中获取数据的速度比执行目标函数的速度更快。
如果实践缓存后对检索结果所需的时间有正面的影响,我们才应该引入缓存。
缓存应该比从当前数据源获取数据更快。
因此,选择合适的数据结构(例如字典或 LRU 缓存)作为缓存的实例至关重要。
2.3. 第三条规则:
第三个重要规则是关于内存占用,这很常被忽略。你执行的是 I/O 操作(例如查询数据库、网络服务),还是执行 CPU 密集型操作(例如处理数字和执行内存内计算)?
当我们缓存数据时,应用程序的内存占用会增加,因此选择合适的数据结构并且只缓存需要缓存的数据是至关重要的。
有时侯,我们得查询多个表来创建一个类的对象。然而,我们只需要在我们的应用程序中缓存基本属性。
缓存对内存占用有影响。
例如,假设我们构建了一个报告面板,用于查询数据库并检索订单列表。为了让你有个大致的画面,我们假设面板上仅显示订单名称。
因此,我们可以只缓存每个订单的名称,而不是缓存整个订单对象。通常,架构师建议创建一个具有 __slots__ 属性的「瘦身版」数据传输对象(DTO)以减少内存占用。命名元组或 dataclass 类也有同样的效果。(dataclass 类是 Python 3.7 中新增的功能。)
本文的最后一部分:概述实现缓存的细节。
3. 如何实现缓存?
有多种方法可以实现缓存。
我们可以在 Python 进程中创建本地数据结构来构建缓存,或将缓存作为服务器充当代理并为请求提供服务。
Python 中有相应的内置工具,例如 functools 库中的 cached_property 装饰器。我将通过它来介绍缓存的实现。(仅适用于 Python 3.8 及更高版本。)
下面的代码段说明了 cached_property 如何运作:
from functools import cached_property
class FinTech:
@cached_property
def run(self):
return list(range(1, 100))
因此,现在 FinTech().run 已被缓存,并且 list(range(1,100)) 将只生成一次。但是,在实际场景中,我们几乎不需要缓存属性。
让我们看看其他方法。
3.1. 字典方法
对于简单的用例,我们可以创建/使用映射数据结构(例如字典),将数据保存在内存中并使其使其可在全局范围内访问。
实现方式有多种,最简单的方法是创建一个单例模块,例如:config.py。
在 config.py 中,我们可以创建一个字典类型的字段,该字段在开始时被填充一次。
以后我们便可以使用字典的字段来获取结果。
举例来说,看看下方的代码。
config.py 带有 cache 属性:
cache = {}
试想一下,我们的应用程序将通过 get_prices(symbol, start_date, end_date) 函数查询雅虎财经的网络服务以获取公司的历史价格。
历史价格不会改变,因此我们不需要每次需要历史价格时都查询网络服务。我们可以在内存中缓存价格。
在内部实践中,函数 get_prices(symbol, start_date, end_date) 可以在尝试返回结果之前检查数据是否在缓存中。
让我通过代码解释该策略。
下面的 get_prices 函数接受一个名为 companies 的参数。
- 首先,该函数创建一个开始和结束日期的变量,其中开始日期设为昨天,结束日期设为 12 天前。
- 然后它创建一个名为
target_key的元组类型变量。它的值唯一,由模块、函数、开始和结束日期组成。 - 该函数首先在
config.cache中查找键。如果它找到了,则检查cache是否包含目标公司名称。 - 如果缓存中包含公司名称,它会从缓存中返回价格。
- 如果
target_key不在缓存中,那么它通过雅虎财经检索所有公司,并将价格保存在缓存中以备将来调用,最后返回价格。
因此,基本概念是检查缓存中的目标键,如果不存在,则从源头获取它并在返回之前将其保存在缓存中。
这就是缓存的构建方式:
import datetime
import yfinance as yf
import config
def get_prices(companies):
end_date = datetime.datetime.now() - datetime.timedelta(days=1)
start_date = end_date - datetime.timedelta(days=11)
target_key = (__name__, '_get_prices_',
start_date.strftime("%Y-%m-%d"),
end_date.strftime("%Y-%m-%d"))
if target_key in config.cache:
cached_prices = config.cache[target_key]
# cached_prices 是一个字典,其中键为公司符号,值为价格。
prices = {}
for company in companies:
# 对于每个公司,只获取未缓存的价格。
if company in cached_prices:
# 我们已经缓存了价格。
# 在局部变量中设置价格。
prices[company] = cached_prices[company]
else:
# 去雅虎财经得到价格。
yahoo_prices = yf.download(company, start=start_date, end=end_date)
prices[company] = yahoo_prices['Close']
cached_prices[company] = prices[company]
return prices
else:
company_symbols = ' '.join(map(lambda x: x, companies))
yahoo_prices = yf.download(company_symbols, start=start_date, end=end_date)
# 现在将其存储在缓存中以备将来使用。
prices_per_company = yahoo_prices['Close'].to_dict()
config.cache[target_key] = prices_per_company
return prices_per_company
上方的所选键包含开始日期和结束日期。你也可以在键中包含公司名称,存储 (公司名称,开始日期,结束日期,函数名称) 作为键。
数据结构的键必须是唯一的,它可以是一个元组。
历史价格不会改变,因此不构建及时使缓存失效的逻辑也是安全的。
这个缓存是一个嵌套字典,因为其值是一个字典。它加快了查找的速度,使得操作的时间复杂度为 O(1)。
这里有一篇很棒的文章,它以一种易于理解的方式解释了 Python 数据结构的时间复杂性。
有时键会变得太长,最好使用 MD5、SHA 等对其进行散列。但是,使用散列可能会发生冲突,使得两个字符串产生相同的散列。
我们也可以利用记忆化(memoisation)技术。
记忆化通常用于递归函数调用,中间结果存储在内存中,并在需要时返回。
因此我将介绍 LRU。
3.2. LRU 算法
我们可以使用 Python 的内置 LRU 功能。
LRU 代表的是 Least Recently Used(最近最少使用)的算法。LRU 可依赖于函数的参数来缓存返回值。
LRU 在 CPU 密集型的递归操作中特别有用。
它本质上是一个装饰器:@lru_cache(maxsize, typed),我们可以用它来装饰我们的函数。
maxsize告诉装饰器缓存的最大大小(预设值为 128)。如果我们不想限制大小,那么只需将其设置为None。- 当缓存比较输入/输出时,
typed用于指示是否要将不同数据类型下的相同值分别缓存。(如果typed设置为True,则不同类型的函数参数将分别缓存。例如,f(3)和f(3.0)将被视为具有不同结果的不同调用。)
当我们期望相同的输入有相同的输出时,这非常有用。
保存应用程序的所有数据到内存可能也会造成困扰。
在具有多个进程的分布式应用程序中,这可能会成为一个问题。这种情况下,将所有结果缓存在所有进程的内存中是不合适的。
一个很好的用例是当应用程序在一组机器上运行时,我们可以将缓存托管为服务。
3.3. 服务式缓存
第三个选项是将缓存数据作为外部服务托管。它充当代理服务器,负责所有的请求和响应,所有应用程序都可以通过它检索数据。
试考虑一下,我们正在构建一个与维基百科一样大的应用程序,预计它可以同时、并行地处理 1000 个请求。
我们需要一个缓存机制,并希望在服务器之间分配缓存。
我们可以使用 Memcached 来缓存数据。
Memcached 在 Linux 和 Windows 中非常流行,因为:
- 它可用于实现具有状态的记忆缓存。
- 它甚至可以跨服务器分布。
- 它使用起来非常简单,速度很快,并且被整个行业中的多个大型组织使用。
- 支持缓存数据自动过期。
我们需要安装一个名为 pymemcache 的 Python 库。
Memcached 要求将数据存储为字符串或二进制。因此,我们必须序列化缓存对象。当我们想要检索它们时,我们必须反序列化它们。
以下的代码段显示了我们如何启动和使用 Memcached:(在执行代码前,你需要下载 Memcached 并启动它。关于如何创建 serialiser 和 deserialiser,请看这里。)
from pymemcache.client.base import Client
client = Client(host, serialiser, deserialiser)
client.set('blog', {'name': 'caching', 'publication': 'fintechexplained'})
blog = client.get('blog')
3.4. 问题:使缓存失效
最后,我想快速地概述一个场景:当相同输入的函数输出频繁更改,且我们希望缩短结果的缓存时间。
试考虑两个应用程序在两个不同的应用程序服务器上运行的情况。
第一个应用程序从数据库服务器获取数据,第二个应用程序更新数据库服务器中的数据。数据被频繁获取,我们希望将数据缓存在第一个应用程序服务器中:
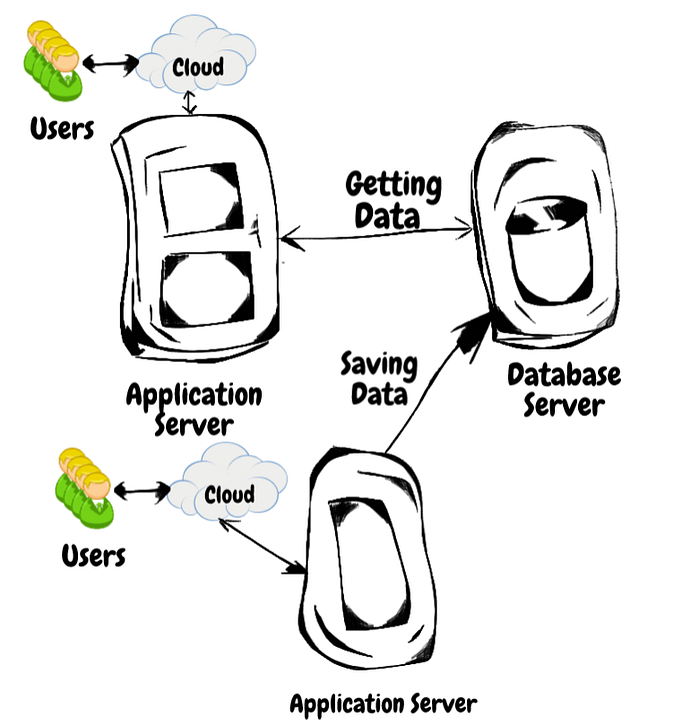
这里有几种方法可以解决它:
- 每当存储新记录时,第二个应用服务器中的应用可以通知第一个应用服务器,以便刷新缓存。它可以将消息发布到第一个应用程序可以订阅的队列。
- 第一个应用服务器还可以对数据库服务器进行轻量级调用以查找上次更新数据的时间,然后它可以使用该时间来确定是否需要刷新缓存或从缓存中获取数据。
- 我们还可以添加一个超时来清除缓存,以便下一个请求可以重新加载它。它很容易实现,但不如我的上一个选项可靠。它可以通过
signal库实现,我们可以订阅一个 handler 到signal.alarm(timeout),并在timeout被调用后,清除 handler 中的缓存。我们还可以运行后台线程来清除缓存,但是,确保你使用了适当的同步对象。
总结
缓存是每个 Python 程序员和数据科学家都需要理解的重要概念。
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
