这是我参与8月更文挑战的第13天,活动详情查看:8月更文挑战
本文为吴恩达机器学习课程的笔记系列第七篇,主要学习异常检测算法。
异常检测(Anomaly Detection)
异常检测属于非监督问题。异常检测是机器学习算法的一个常见应用,是对不匹配预期模式或数据集中其他项目的项目、事件或观测值的识别。简单来说,当正样本比较多时,通过对正样本的学习,机器学会正样本的特征,从而对异常样本有了识别能力。
异常检测的核心就在于找到一个概率模型,帮助我们知道一个样本落入正常样本中的概率,从而帮助我们区分正常和异常样本。
高斯分布
高斯分布模型是异常检测中常用的概率模型。其概率密度函数如下:
p(x,μ,σ2)=2πσ1exp(−2σ2(x−μ)2)
其中:
- μ=m1i=1∑mx(i)
- σ2=m1i=1∑m(xj(i)−μj)2
应用到异常检测算法,对于m 个样本的数据集,针对每一个特征,进行参数估计:
- μj=m1i=1∑mxj(i)
- σj2=m1i=1∑m(x(i)−μ)2
假设每个样本有n个特征,即 xi 变成一个 n 维的向量 ⎣⎡xi(1)xi(2)⋮xi(n)⎦⎤
对于一个训练实例,有:
p(x)=j=1∏n(xj,μ,σ2)=j=1∏n2πσ1exp(−2σ2(x−μ)2)
如何判断样本是否异常?
我们选择一个ϵ,将 p(x)=ϵ 作为我们的判定边界,当 p(x)>ϵ 时预测数据为正常数据,否则为异常。
异常检测与有监督学习对比
| 异常检测 | 有监督学习 |
|---|
| 数据非常偏斜,非常少量的正向类(异常数据y=1 ), 大量的负向类(y=0) | 数据分布均匀,同时有大量的正向类和负向类 |
| 异常的类型不一,很难根据对现有的异常数据(即正样本)来训练算法。 | 有足够多的正样本,可以根据对正样本的拟合来知道正样本的形态,从而预测新来的样本是否是正样本。 |
| 未来遇到的异常可能与已掌握的异常、非常的不同。 | 未来遇到的正向类实例可能与训练集中的非常近似。 |
| 例如: 欺诈行为检测 生产(例如飞机引擎)检测数据中心的计算机运行状况 | 例如:邮件过滤器 天气预报 肿瘤分类 |
特征选择
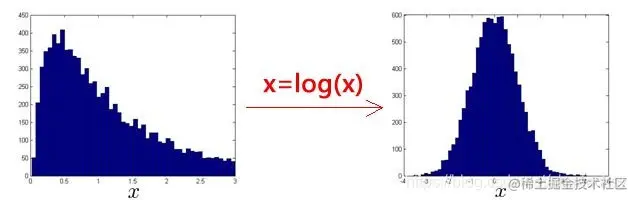
我们使用异常检测算法时,是假设数据集特征符合高斯分布的。但有时候数据集可能像下图左边一样,这时直接用异常检测算法也是可以得出结果,但一般我们可以对数据进行一些转换如取对数操作,将其转换为高斯分布。
误差分析
有时候,我们可能发现某个异常样本的p(x) 值高于ϵ,我们对此进行分析,观察是哪些异常数据被预测为正常。下面以监测机房中的服务器异常为例:
假设我们选取如下特征:
x1=网络流量;x2=CPU负载
当出现一个异常:CPU负载很高,而网络流量很低,服务器卡死,无法通信。如下图:
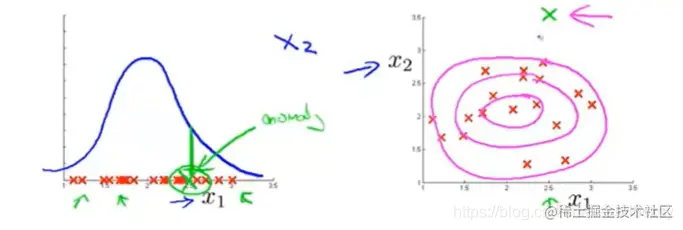
此时的p(x) 值也会很高,为了识别这一异常状况,我们可以构建新的特征:x3=网络流量CPU负载 ,当上述异常发生时,这个特征便会变得很大,有利于我们识别出来。
多元高斯分布
一般的高斯模型因为是同时累乘每个特征的偏差,所以会创造出一个较大的判定边界。
模型定义:
p(x,μ,Σ)=(2π)2n∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
- μ=m1i=1∑mx(i)
- Σ=m1i=1∑m(x(i)−μ)(x(i)−μ)T=m1(X−μ)T(X−μ)
其中,μ 是一个向量,表示样本均值,Σ 表示样本协方差矩阵。
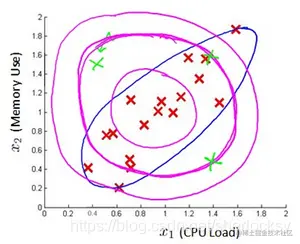
先考虑各个维度不相关,各个维度之间不相关的多元正态分布概率密度其实就是各个维度的正态分布概率密度函数的乘积,其实是因为各变量之间互不相关,因此联合概率密度等于各自概率密度的乘积。
p(x)==2πσ11exp(−2σ12(x1−μ1)2)2πσ21exp(−2σ22(x2−μ2)2)...2πσn1exp(−2σn2(xn−μn)2)(2π)2nσ1σ2...σn1exp{−21[(σ12(x1−μ1)2)+(2σ22(x2−μ2)2)+...+(2σn2(xn−μn)2)]}
右边项:
(σ12(x1−μ1)2)+(σ22(x2−μ2)2)+...+(σn2(xn−μn)2)=[x1−μ1,x2−μ2,...,xn−μn]⎣⎡σ1210⋮00σ221⋮0⋯⋯⋱⋯00⋮σn21⎦⎤⎣⎡x1−μ1x2−μ2⋮xn−μn⎦⎤=(X−μ)TΣ−1(X−μ)
如果各个维度是相关的,那怎么办呢?
实际上我们可以利用化归的思想,把相关变成不相关,
方向变换:u1=[u1(1)u1(2)],u2=[u2(1)u2(2)],使得各个维度之间不相关,下面是推导:
X^=[u1Tu2T]X=UTX=[X^1X^2]
σX^X^−uX^====⎣⎡σX^1X^1−uX^1σX^2X^2−uX^2⎦⎤⎣⎡σX^1100σX^21⎦⎤[X^1−uX^1X^2−uX^2]D(X^−μX^)D(UTX−UTμX)=DUT(X−μX)=Z
UDTDUT=UΣX^−1UT=ΣX−1
最后的概率:
p(x)=(2π)2n∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
应用到异常检测的算法,首先对各个样本进行参数估计:
- μ=m1i=1∑mx(i)
- Σ=m1i=1∑m(x(i)−μ)(x(i)−μ)T
当新样本x到来时,计算p(x):
p(x)=(2π)2n∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
多元高斯分布与一般高斯分布对比
一般高斯分布模型:p(x)=p(x1,μ1,σ12)×p(x2,μ2,σ22)×...×p(xn,μn,σn2)
可见一般高斯模型是多元高斯模型的一个特例,也就是当协方差矩阵 Σ 的上三角和下三角为0的时候。即Σ=⎣⎡σ120000σ2200......⋱...000σn2⎦⎤
两者的区别:
| 一般高斯分布模型 | 多元高斯分布模型 |
|---|
| 需要创建一些特征(比如组合x1,x2)来描述某些特征的相关性 | 自动描述了各个特征的相关性 |
| 计算复杂度低,适于高维特征 | 计算较复杂,计算量大 |
| 即使样本数m较小也适用 | 必须满足m>n,且各个特征必须线性无关,否则协方差矩阵将不可逆 |


