如果我们只考虑X=xi的实例,则这样的实例分分数为Y=yj写成p(Y=yj∣X=xi),并称为Y=yj给定X=xi的条件概率。它是通过查找列i中落在单元格i,j中的点的分数获得的,因此下式给出
p(Y=yj∣X=xi)=cinij(1.8)
从(1.5)、(1.6)和(1.8)中,我们可以得出以下关系
p(Y=yj∣X=xi)=cinij=cinij⋅Nci=p(Y=yj∣X=xi)p(X=xi)(1.9)
这是概率的乘积法则。
到目前为止,我们已经非常小心地区分了随机变量,例如水果示例中的盒子B,以及随机变量可以采用的值,例如如果盒子是红色的,则是R。因此,B取R的概率表示为p(B=r)。虽然这有助于避免歧义,但它会导致一种相当麻烦的符号,在许多情况下,不需要这种迂腐。相反,我们可以简单地写p(B)来表示随机变量B上的分布 ,或P(r)来表示为特定值r计算的分布,前提是上下文中的解释是清楚的。
有了这个更紧凑的符号,我们可以用下面的形式写出概率论的两条基本规则。
概率法则
加法规则
p(X)=Y∑p(X,Y)(1.10)
乘法规则
p(X,Y)=p(Y∣X)p(X)(1.11)
这里p(X,Y)是一个联合概率,用“X和Y的概率”表示。类似的,数量p(Y∣X)是一个条件概率,表示为“给定X的Y的概率”,而数量p(X)是一个边缘概率,只是“X的概率”。这两条简单的规则构成了我们在本书中使用的所有概率机制的基础。
从乘积规则,再加上对称性质p(X,Y)=p(Y,X),我们立即 得到条件概率之间的以下关系
P(Y∣X)=p(X)p(X∣Y)p(Y)(1.12)
它被称为贝叶斯定理,在模式识别和机器学习中起着核心作用。使用求和规则,贝叶斯定理中的分母可以用分子中出现的量来表示
p(X)=Y∑p(X∣Y)p(Y)(1.13)
我们可以将贝叶斯定理中的分母视为标准化常数,以确保(1.12)左侧 的条件概率之和在Y的所有值上等于 1。
在图1.11中我们展示了一个简单的例子,涉及两个变量的联合分布,以说明边缘分布和条件分布的概念。此处,从节理分布中提取了N=60个数据点的有限样本,如左上角所示。右上角是两个Y值各有一个的数据点分数的直方图 。根据概率的定义,这些分数等于极限N中 相应的概率p(Y)→∞。我们可以将柱状图视为一种简单的建模概率分布的方法,只要从该分部中提取有限数量的点。从数据建模分布是统计模式识别的核心,本书将详细讨论。图1.11中剩下的两个图显示了p(X)和p(X∣Y=1)的相应直方图估计。
现在让我们回到我们的例子,涉及到水果盒。目前,我们将再次明确区分随机变量及其实例化。我们已经看到,选择红色或蓝色盒子的概率由
p(B=r)=4/10(1.14)
p(B=b)=6/10(1.15)
分别给出。注意,这些满足p(B=r)+p(B=b)=1。
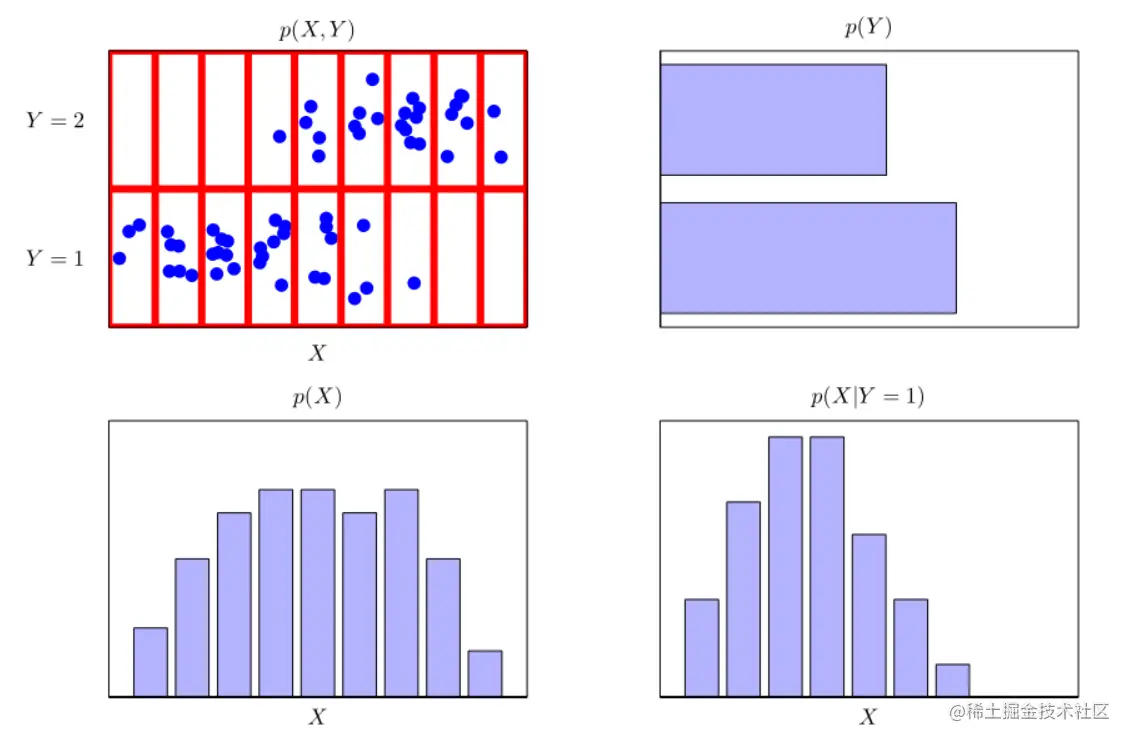
图 1.11 两个变量的分布图,X取9个可能值,Y取两个可能值。左上图显示了从这些变量的联合概率分布中得出的60个点的样本。其余的图显示了边缘分布p(X)和p(Y)的直方图估计,以及与左上角图中底行对应的条件分布p(X∣Y=1)。


