0. 前言
第一次看吴恩达老师机器学习视频时, 在9.2节卡住。看到评论区别人解答(Arch725 的解答)发现有一些疏漏,而且缺少一些铺垫,所以进行了一些修改补充。
本文的反向传播算法的推导过程根据的是交叉熵代价函数,并非二次代价函数。不同代价函数的求导结果不同所以结果略有差异,但本质都是相同的。
交叉熵代价函数:
J(Θ)=−m1i=1∑m(y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i))))
二次代价函数:
J(Θ)=2m1i=1∑m(hθ(x(i))−y(i))2
本文参考自Arch725 的 github。如果读完后觉得有所收获, 请在里点个 star 吧~
1. 潜在读者
这篇文章的潜在读者为:
- 学习吴恩达机器学习课程, 看完9.1节及以前的内容而在9.2节一脸懵逼的同学
- 知道偏导数是什么, 也知道偏导数的求导法则
这篇文章会帮助你完全搞懂9.2节是怎么回事, 除9.1节及以前的内容外, 不需要任何额外的机器学习的知识.
2. 铺垫
2.1 复合函数求导的链式法则
这里只提供公式方便大家回忆,若没有学习相关知识,请学习相关内容(偏导数)。
(链式法则)设u=f(x,y),x=φ(s,t),y=ϕ(s,t),此时f在点(x,y)可微,又x和y都在点(s,t)关于s,t的偏导数存在,则
∂s∂u=∂x∂u∗∂s∂x+∂y∂u∗∂s∂y
∂t∂u=∂x∂u∗∂t∂x+∂y∂u∗∂t∂y
2.2 神经网络的各种记号
约定神经网络的层数为L, 其中第l层的的神经元数为sl, 该层第i个神经元的输出值为ai(l), 该层的每个神经元输出值计算如下:
a(l)=⎣⎡a1(l)a2(l)⋯asl(l)⎦⎤=sigmoid(z(l))=1+e−z(l)1(1)
其中sigmoid(z(l))是激活函数, z(l)是上一层神经元输出结果a(l−1)的线性组合Θ(l−1)是参数矩阵,k(l−1)为常数向量:
z(l)=Θ(l−1)a(l−1)+k(l−1)(2)
Θ(sl×sl−1)(l−1)=⎣⎡θ11(l−1)θ21(l−1)⋮θsl1(l−1)θ12(l−1)θ22(l−1)⋮θsl2(l−1)⋯⋯⋱⋯θ1sl−1(l−1)θ2sl−1(l−1)⋮θslsl−1(l−1)⎦⎤(3)
参数(权重)矩阵Θ(l−1)的任务就是将第l−1层的sl−1个参数线性组合为sl个参数, 其中θijl−1表示aj(l−1)在ai(l)中的权重(没错, 这里的i是终点对序号, j是起点的序号), 用单一元素具体表示为:
zi(l)=θi1(l−1)∗a1(l−1)+θi2(l−1)∗a2(l−1)+⋯+θisl−1(l−1)∗asl−1(l−1)+ki(l−1)=(k=1∑sl−1θik(l−1)∗ak(l−1))+ki(l−1)(4)
另外, 在logistic回归中, 定义损失函数如下:
cost(a)={log(a)log(1−a)y=1y=0=ylog(a)+(1−y)log(1−a),y∈{0,1}(5)
记不住那么多符号可以看看下面的神经网络示例图。
3. 正式推导
据此, 我们的思路是, 计算出神经网络中的损失函数J(Θ), 然后通过梯度下降来求J(Θ)的极小值.
以一个3∗4∗4∗3的神经网络为例.图如下:
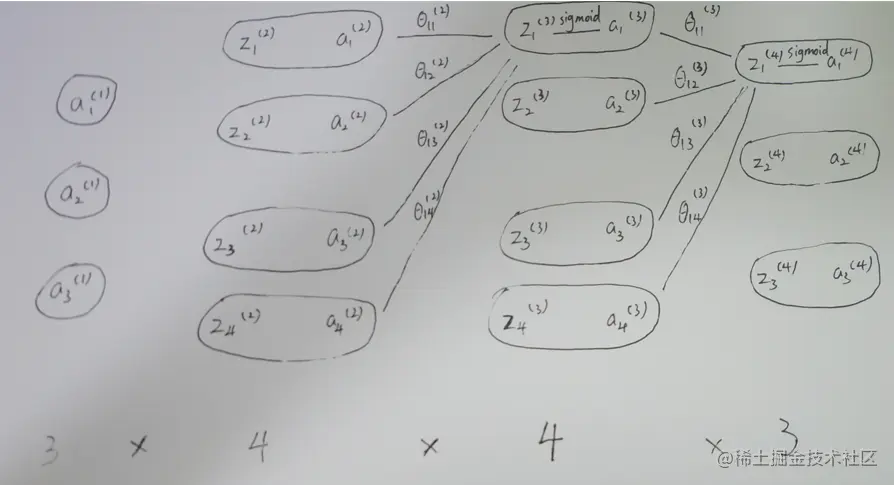
在该神经网络中, 损失函数如下:
J(Θ)=y1log(a1(4))+(1−y1)log(1−a1(4))+y2log(a2(4))+(1−y2)log(1−a2(4))+y3log(a3(4))+(1−y3)log(1−a3(4))(6)
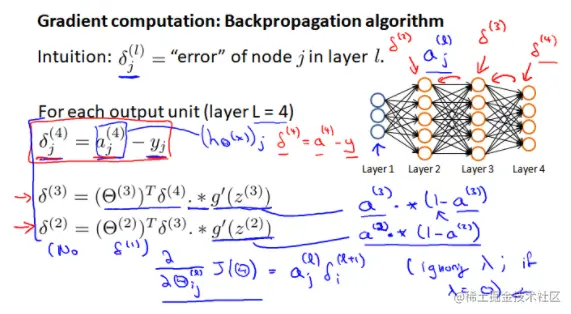
反向算法的精髓就是提出了一种算法, 让我们能快速地求出J(Θ)对Θ的各个分量的导数(这就是9.2和9.3节在做的工作). 相信大家在看到误差公式那里和我一样懵, 我们接下来就从根本目标——求偏导数入手, 先不管”误差”这个概念. 在求导的过程中, “误差”这一概念会更自然的浮现出来.
我们首先对于最后一层参数求导, 即Θ(3). 首先明确, Θ(3)是一个3∗4的矩阵(Θ(3)a(4×1)(3)=z(3×1)(4)), ∂Θ(3)∂J也是一个3∗4矩阵, 我们需要对Θ(3)的每一个分量求导. 让我们首先对θ12(3)求导:
∂θ12(3)∂J=(7.1)∂a1(4)∂J∗(7.2)∂z1(4)∂a1(4)∗(7.3)∂θ12(3)∂z1(4)(7)
分别由式(6), (1),(4)知:
(7.1)=∂a1(4)∂J=a1(4)y1−1−a1(4)1−y1(8)
(7.2)=∂z1(4)∂a1(4)=(1+e−z1(4))2−e−z1(4)=1+e−z1(4)1∗(1−1+e−z1(4)1)=a1(4)(1−a1(4))(9)
(7.3)=∂θ12(3)∂z1(4)=a2(3)(10)
代入(7)知:
∂θ12(3)∂J=(y1(1−a1(4))−(1−y1)a1(4))a2(3)=(y1−a1(4))a2(3)(11)
同理可知J(Θ)对Θ(3)其他分量的导数. 将∂Θ(3)∂J写成矩阵形式:
∂Θ(3)∂J=⎣⎡(y1−a1(4))a1(3)(y2−a2(4))a1(3)(y3−a3(4))a1(3)(y1−a1(4))a2(3)(y2−a2(4))a2(3)(y3−a3(4))a2(3)(y1−a1(4))a3(3)(y2−a2(4))a3(3)(y3−a3(4))a3(3)(y1−a1(4))a4(3)(y1−a1(4))a4(3)(y1−a1(4))a4(3)⎦⎤(12)
如果我们定义一个“误差”向量为δ(4)=[(y1−a1(4))(y2−a2(4))(y3−a3(4))]T, 衡量最后一层神经元的输出与真实值之间的差异, 那么(12)可以写成两个矩阵相乘的形式:
∂Θ(3)∂J=δ(4)[a1(3)a2(3)a3(3)a4(3)]=δ(3×1)(4)(a(3))(1×4)T(13)
让我们先记下这个式子, 做接下来的工作: 计算∂Θ(2)∂J. 和计算∂Θ(3)∂J一样, 让我们先计算θ12(2)∂J:
∂θ12(2)∂J=(14.1)∂a1(3)∂J∗(14.2)∂z1(3)∂a1(3)∗(14.3)∂θ12(2)∂z1(3)(14)
θ12(2)对J(Θ)求导,根据偏导数的求导法则,要找到J(Θ)中所有与θ12(2)有关的项进行链式求导。由上式可以看出θ12(2)只是a1(3)的变量,所以只需要考虑J(Θ)有多少项和a1(3)相关。
z1(4)=θ11(3)∗a1(3)+θ12(3)∗a2(3)+θ13(3)∗a3(3)+θ14(3)∗a4(3)+k1(4)
z2(4)=θ21(3)∗a1(3)+θ22(3)∗a2(3)+θ23(3)∗a3(3)+θ24(3)∗a4(3)+k2(4)
z3(4)=θ31(3)∗a1(3)+θ32(3)∗a2(3)+θ33(3)∗a3(3)+θ34(3)∗a4(3)+k3(4)
上面三式是最后一层z(4)的求和过程,可以看到z1(4),z2(4),z3(4)中都包含a1(3),所以(14.1)式还可以做如下拆分:
(14.1)=∂a1(3)∂J=(15.1)∂a1(4)∂J∗∂z1(4)∂a1(4)∗∂a1(3)∂z1(4)+(15.2)∂a2(4)∂J∗∂z2(4)∂a2(4)∗∂a1(3)∂z2(4)+(15.3)∂a3(4)∂J∗∂z3(4)∂a3(4)∗∂a1(3)∂z3(4)(15)
注意到(15.1), (15.2)与(15.3)式都和(7)式类似, 三式子可分别化为:
(15.1)=∂a1(4)∂J∗∂z1(4)∂a1(4)∗∂a1(3)∂z1(4)=(y1−a1(4))θ11(3)(16)
(15.2)=∂a2(4)∂J∗∂z2(4)∂a2(4)∗∂a1(3)∂z2(4)=(y2−a2(4))θ21(3)(17)
(15.3)=∂a3(4)∂J∗∂z3(4)∂a3(4)∗∂a1(3)∂z3(4)=(y3−a3(4))θ31(3)(18)
将(16), (17), (18)代入(19):
(14.1)=∂θ12(2)∂J=(y1−a1(4))θ11(3)+(y2−a2(4))θ21(3)+(y3−a3(4))θ31(3)(19)
另外, 与(9), (10)类似, 可以得到(14.2)和(14.3):
(14.2)=∂z1(3)∂a1(3)=a1(3)(1−a1(3))(20)
(14.3)=∂θ12(2)∂z1(3)=a2(2)(21)
将(19), (20), (21)共同代入(14), 得到θ12(2)∂J:
∂θ12(2)∂J=[(y1−a1(4))θ11(3)+(y2−a2(4))θ21(3)+(y3−a3(4))θ31(3)]a1(3)(1−a1(3))a2(2)(22)
同理也可知J(Θ)对Θ(2)其他分量的导数. 将∂Θ(2)∂J写成矩阵形式:

(23)只是看起来很复杂, 实际上只是一个普通的(4∗4)矩阵. 让我们先参考(13)将a(2)T拆出来:
∂Θ(2)∂J4×4=24.1⎣⎡{[(y1−a1(4))θ11(3)+(y2−a2(4))θ21(3)+(y3−a3(4))θ31(3)]∗a1(3)(1−a1(3))}{[(y1−a1(4))θ12(3)+(y2−a2(4))θ22(3)+(y3−a3(4))θ32(3)]∗a2(3)(1−a2(3))}{[(y1−a1(4))θ13(3)+(y2−a2(4))θ23(3)+(y3−a3(4))θ33(3)]∗a3(3)(1−a3(3))}{[(y1−a1(4))θ14(3)+(y2−a2(4))θ24(3)+(y3−a3(4))θ34(3)]∗a4(3)(1−a4(3))}⎦⎤4×1∘24.2[a1(2)a2(2)a3(2)a4(2)]1×4(24)
其中(24.2)是我们熟悉的a(2)T, 而我们先暂时定义(24.1)为δ(3)(先不管它的实际意义), 引入Hadamard积的概念(就是9.2节视频中的⋅∗符号), 对δ(3)进一步拆分:
δ(3)=⎣⎡{[(y1−a1(4))θ11(3)+(y2−a2(4))θ21(3)+(y3−a3(4))θ31(3)]}{[(y1−a1(4))θ12(3)+(y2−a2(4))θ22(3)+(y3−a3(4))θ32(3)]}{[(y1−a1(4))θ13(3)+(y2−a2(4))θ23(3)+(y3−a3(4))θ33(3)]}{[(y1−a1(4))θ14(3)+(y2−a2(4))θ24(3)+(y3−a3(4))θ34(3)]}⎦⎤∘⎣⎡a1(3)(1−a1(3))a2(3)(1−a2(3))a3(3)(1−a3(3))a4(3)(1−a4(3))⎦⎤=⎣⎡θ11(3)θ12(3)θ13(3)θ14(3)θ21(3)θ22(3)θ23(3)θ24(3)θ31(3)θ32(3)θ33(3)θ34(3)⎦⎤∘⎣⎡y1−a1(4)y2−a2(4)y3−a3(4)⎦⎤∘⎣⎡a1(3)(1−a1(3))a2(3)(1−a2(3))a3(3)(1−a3(3))a4(3)(1−a4(3))⎦⎤=Θ(3)Tδ(4)∘∂z(3)∂a(3)(25)
综合(24), (25)式可以得到:
∂Θ(2)∂J=δ(3)a(2)T(26)
其中
δ(3)=Θ(3)Tδ(4)∘∂z(3)∂a(3)(27)
至此, 基本大功告成. 让我们将(26), (27)与(13)对照观察:
∂Θ(3)∂J=δ(4)a(3)T
∂Θ(2)∂J=δ(3)a(2)T
δ(3)=Θ(3)Tδ(4)∘∂z(3)∂a(3)(28)
归纳总结即可推广到L层的神经网络:
∂Θ(l)∂J=δ(l+1)a(l)T
δ(l)=⎩⎨⎧0Θ(l)Tδ(l+1)∘∂z(l)∂a(l)y−a(l)l=01⩽l⩽L−1l=L(29)
其中∂z(l)∂a(l)就是sigmoid(x)求导.
根据(29), 我们就可以顺利、轻松、较快速地迭代求出J(Θ)对Θ的各个分量的导数.
对比吴恩达课程中的结果可以发现是完全相同的。