

我们可以用简单的方法,也可以用困难的方法来做这件事

照片:Pablo ArroyoonUnsplash
注意:为了格式化,所介绍的代码是以图片形式出现的,但都可以在这里找到。
动机
虽然Pandas是数据科学和数据分析师工作流程中最常见的Python工具,但它在处理大数据集时的规模并不大,因为它一次只使用一个内核。它还使用了令人惊讶的内存量。在Wes McKinney的博文中,他提到经验法则是要有5倍或10倍于数据集大小的内存。
当数据处理在Pandas上变得低效时,数据科学家就开始接触分布式计算框架,如Spark。这些框架通过使用单台机器甚至整个集群上的可用内核来加快计算速度。缺点是,为了利用Spark的优势,Pandas和Python代码通常要经过处理才能与Spark兼容。
在这篇文章中,我们将介绍一个用Fugue将Pandas和Python代码无缝移植到Spark的例子,Fugue是一个开源的分布式计算抽象层。在经历了Fugue方法之后,我们将把它与使用Spark 3.0中的mapInPandas方法的传统方法进行比较。
示例问题
在这个示例问题中,我们有一个机器学习模型,已经用Pandas和scikit-learn训练过了。我们想在一个数据集上运行预测,这个数据集太大,Pandas无法使用Spark有效处理。本教程也将适用于转换数据的操作。我们并不局限于机器学习的应用。
首先,我们先做一个简单的LinearRegression模型。
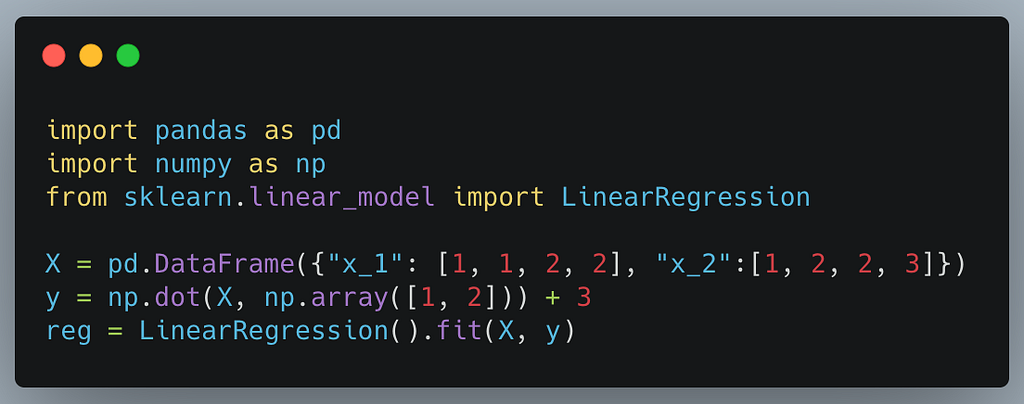
简单的线性回归
然后我们做一个简单的预测函数,它将接收一个DataFrame并创建一个名为 "**predicted "**的新列来预测。这一部分对于Pandas用户来说并不陌生。

用Fugue在Spark中执行
这就是奇迹发生的地方。Fugue是一个抽象层,旨在使用户能够将Pandas和Python代码移植到Spark。稍后,我们将展示如何在没有Fugue的情况下手动操作,但首先,我们要看看Fugue是如何完成的。
Fugue有一个转换函数,可以接收Pandas或Spark数据帧和一个函数。当我们指定一个ExecutionEngine时,Fugue就会应用必要的转换,在该引擎(本例中为Spark)上运行代码。如果没有指定引擎,它将在Pandas上运行。请看下面的代码片断。
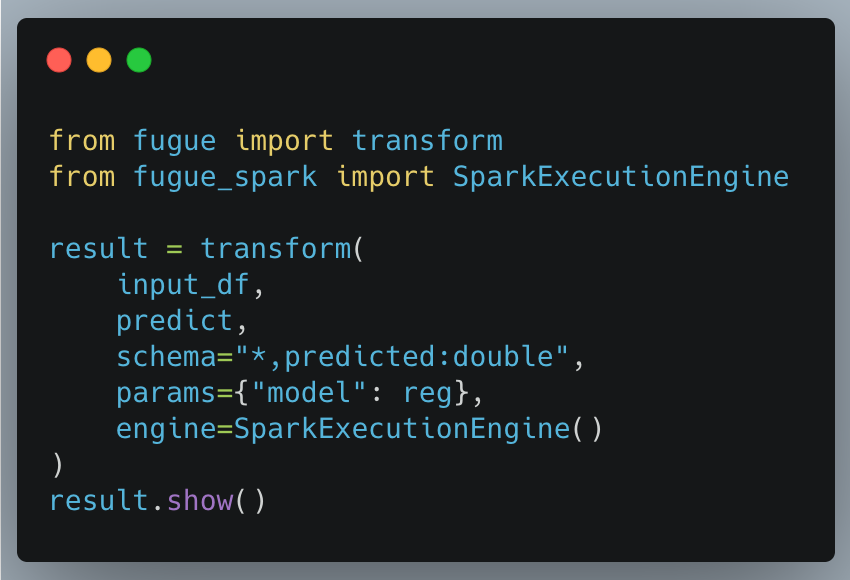
而这就是字面上的意思了。这将在Spark上运行。代码块中的大多数东西都很容易理解。input_df 可以是Pandas或Spark DataFrame。predict函数就是我们之前定义的那个,params参数包含了传递给该函数的内容。在这种情况下,我们传递的是我们之前训练的回归模型。因为我们选择了SparkExecutionEngine,所有的代码都将以并行的方式在Spark上运行。
最后要理解的是模式参数。这是因为模式在Spark中是严格执行的,需要明确。通过**"*, predicted:double",我们指定保留所有的列,并添加一个新的名为predicted的**double类型的列。这是对Spark方法的一个巨大的简化语法,我们将在后面看到。
使用Fugue的转换函数,我们能够在Spark上使用Pandas函数,而无需对原始函数定义进行任何修改。让我们看看如何在没有Fugue的情况下做同等的事情。没有必要在下一节中完全理解所有的东西,重点只是要说明Fugue的接口是多么的简单。
Spark的实现
本节是为那些想比较各种方法的人准备的。下面的代码片段是如何使用Spark的mapInPandas来实现的。
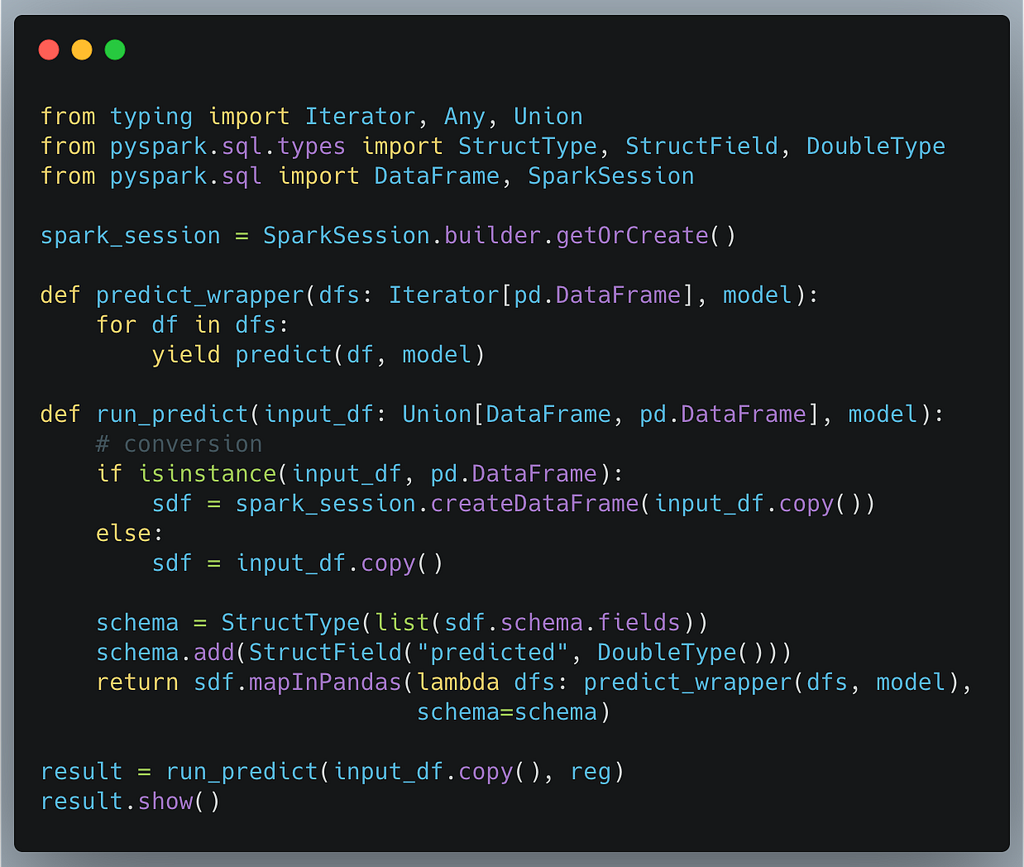
按顺序,步骤是。
- 创建SparkSession(Fugue的SparkExecutionEngine在引擎盖下做这个工作
- 包裹预测函数,使其在数据帧的迭代器上工作。这是因为该函数将接收多个DataFrames(分区)并预测每一组。
- 创建一个run_predict函数,接收Spark或Pandas DataFrame。如果DataFrame还没有被转换为Spark DataFrame,则将其转换为Spark DataFrame。
- 拉动模式并添加新的**"预测 "**列,类型为双倍。
- 使用mapInPandas方法将该操作映射到分区中。
Fugue的转换为用户处理了所有这些。
总结
在这篇文章中,我们比较了两种将Pandas和Python函数引入Spark的方法。第一种是使用Fugue,我们只需在SparkExecutionEngine上调用转换函数,所有的转换都为我们处理。第二种是使用vanilla Spark,在那里我们必须创建辅助函数。
对于一个函数,我们已经不得不在Spark实现中写了很多模板代码。对于一个有几十个函数的代码库来说,从业者最终要写大量的模板代码,使代码库变得混乱。虽然使用Fugue最简单的方式是转换函数,但这种编写与Pandas和Spark都兼容的代码的概念可以扩展到完整的工作流程。欲了解更多细节,请随时联系(信息如下)。
联系我们
如果你有兴趣了解更多关于Fugue、分布式计算或如何以更简单的方式使用Spark的信息,请随时联系我们!这里所涉及的内容只是一个起点。Fugue团队正在为数据团队提供完整的研讨会和演示,并希望能与您交谈。
电子邮件:hello@fugue.ai
将Python和Pandas函数无缝移植到Spark上》最初发表于Towards Data Science的Medium上,人们在这里通过强调和回应这个故事来继续对话。
