

JVM运行机制(整体脉络)
Java代码是如何运行的
假设我们开发一个Java Web系统,然后部署到Tomcat中运行。
- 首先是通过IDEA去编写DemoService.java源文件(很多)
- 然后将多个 .java源文件打包成WAR包或者JAR包,部署到Tomcat这样的Web容器中
- 启动Tomcat,当Tomcat成功启动后,Web系统即可对外提供服务
- Connector : Http(Technology)
- Container: Servlet(Business)
我们也可以通过java -jar XX.jar 命令 来启动web程序
图示
课后习题
既然"java”文件可以编译成".class”文件再运行,那么也肯定可以将“.class"文件反编译成"java”文件。
但是这样的话,如果你们公司的系统代码编译好之后,都是.class”的格式,但是被别人拿到了,反编译回来不就可以窃取你们公司的核心系统的源代码了?对这个问题,大家觉得应该怎么解决呢?
其实就是问一些安全措施了:如何对".class"文件处理保证不被人拿到以后反编译获取公司源代码?
-
首先你编译时,就可以采用一些小工具对字节码加密,或者做混淆等处理
现在有很多第三方公司,都是专门做商业级的字节码文件加密的,所以可以付费购买他们的产品。
-
然后在类加载的时候,对加密的类,考虑采用自定义的类加载器来解密文件即可,这样就可以保证你的源代码不被人窃取。
JVM类加载机制
什么情况下,JVM会去加载一个类
在你的代码里用到这个类的时候,就回去加载这个类。(用时加载)
加载过程
加载 -> 验证 > 准备 -> 解析 -> 初始化 -> 使用 -> 卸载
1. 验证、准备、解析
1.1 验证
根据Java虚拟机规范,校验你的.class文件中的内容,是否合乎指定的规范。
假如说,你的“.class”文件被人篡改了,里面的字节码压根儿不符合规范,那么JVM是没法去执行这个字节码的!
1.2 准备
-
给类分配一定的内存空间。
-
然后会给类的static变量(类变量)分配内存空间,并且设置一个默认的初始值
public static int flushInterval;- 给
flushInterval变量分配一定的内存空间 - 设置默认的初始值:0
- 给
1.3 解析
将符号引用替换为直接引用
2. 初始化(核心阶段)
public static int flushInterval = Configuration.getInt("replica.flush.interval");
我们知道在准备阶段时,是不会给flushInterval类变量执行Configuration.getInt()这个赋值操作的。
Configuration.getInt("replica.flush.interval")赋值操作在初始化阶段完成。
同时会执行static 静态代码块。
public static Map<String, Replica> replicas;
static {
loadReplicaFromDish();
}
private static void loadReplicaFromDish() {
replicas = new HashMap<>();
}
初始化规则
什么情况下会初始化一个类?
一般来说有以下一些时机:
- 比如“
new ReplicaManager()"来实例化类的对象了,此时就会触发类的加载到初始化的全过程,把这个类准备好,然后再实例化一个对象出来;(对象实例化) - 或者是包含“
main()”方法的主类,必须是立马初始化的。 - 此外,这里还有一个非常重要的规则,就是如果初始化一个类的时候,发现他的父类还没初始化,那么必须先初始化他的父类
图示
类加载器与双亲委派机制
类加载器
顾名思义,类加载器用来加载类。
Java自带的类加载器有以下几种:
启动类加载器(BootStrap ClassLoader)
负责加载Java目录下的核心类。
一旦你的JVM启动,那么首先就会依托启动类加载器,去加载你的Java安装目录下的“lib”目录中的核心类库。
扩展类加载器(Extension ClassLoader)
Extension ClassLoader,这个类加载器其实也是类似的,就是你的Java安装目录下,有一个"lib\ext”目录这里面有一些类,就是需要使用这个类加载器来加载的,支撑你的系统的运行。
JVM一旦启动,也得从Java安装目录下,加载这个‘“lib\ext”目录中的类。
应用程序类加载器(Application ClassLoader)
负责去加载“ClassPath”环境变量所指定的路径中的类。
可以大致理解为去加载你写好的Java代码,这个类加载器就负责加载你写好的那些类到内存里。
自定义类加载器
开发者自定义类加载器,根据自己的需求去加载类,可能会打破双亲委派机制。
双亲委派机制
当应用程序类加载器需要加载一个类时,首先会委托自己的父类加载器去加载,最后会传导到顶层的类加载器去加载;
如果父类加载器在自己负责加载的范围内,没找到这个类,那么就会下推加载权利给自己的子加载器。
通俗说明
比如你的JVM现在需要加载“ReplicaManager”类,此时应用程序类加载器会问问自己的爸爸,也就是扩展类加载器,你能加载到这个类吗?
然后扩展类加载器直接问自己的爸爸,启动类加载器,你能加载到这个类吗?启动类加载器心想,我在Java安装目录下,没找到这个类啊,自己找去!
然后,就下推加载权利给扩展类加载器这个儿子,结果扩展类加载器找了半天,也没找到自己负责的目录中有这个类。 这时他很生气,说:明明就是你应用程序加载器自己负责的,你自己找去。
然后应用程序类加载器在自己负责的范围内,比如就是你写好的那个系统打包成的jar包吧,一下子发现,就在这里!然后就自己把这个类加载到内存里去了。
这就是所谓的双亲委派模型:先找父亲去加载,不行的话再由儿子来加载。 这样的话,可以避免多层级的加载器结构重复加载某些类。
图示
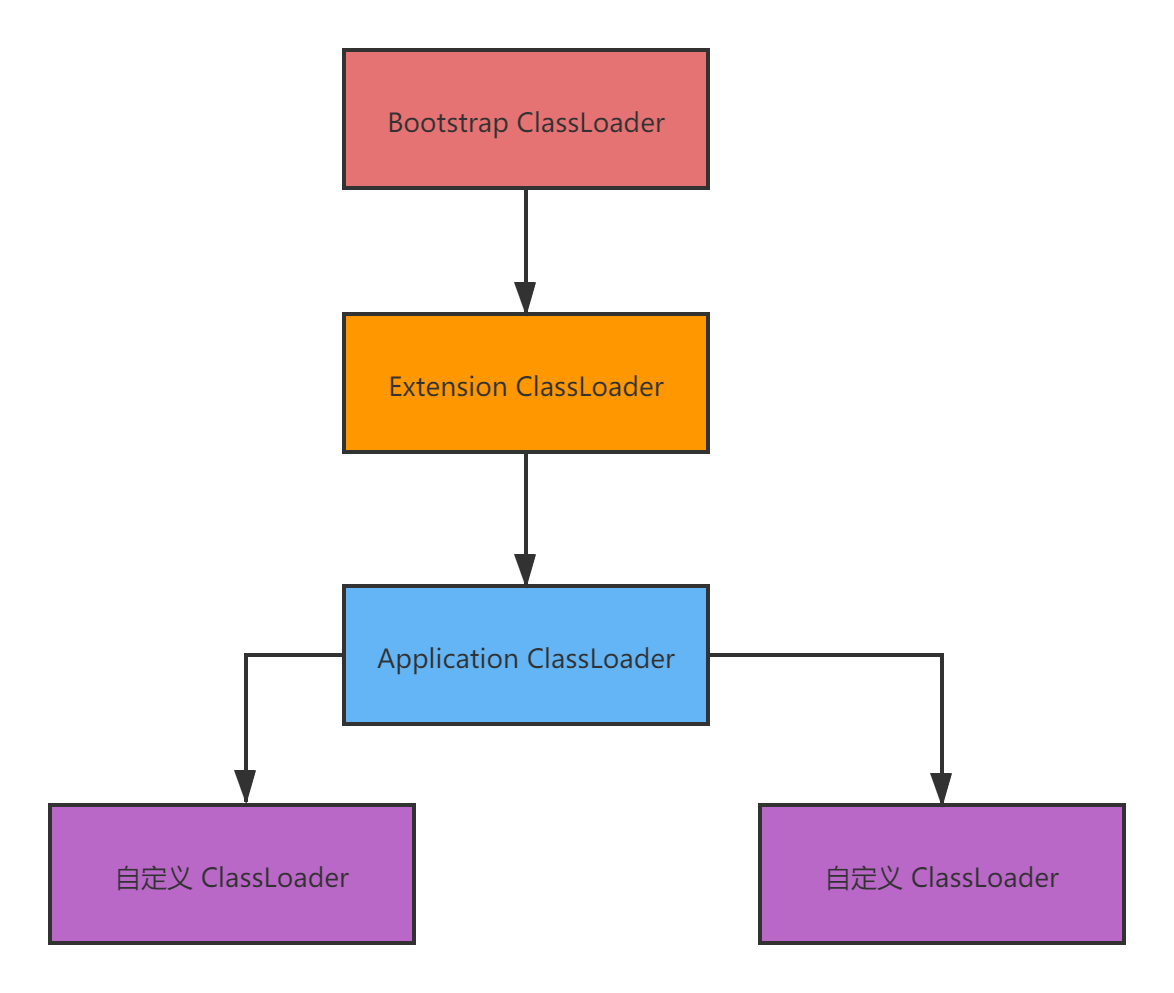
类加载器的层级
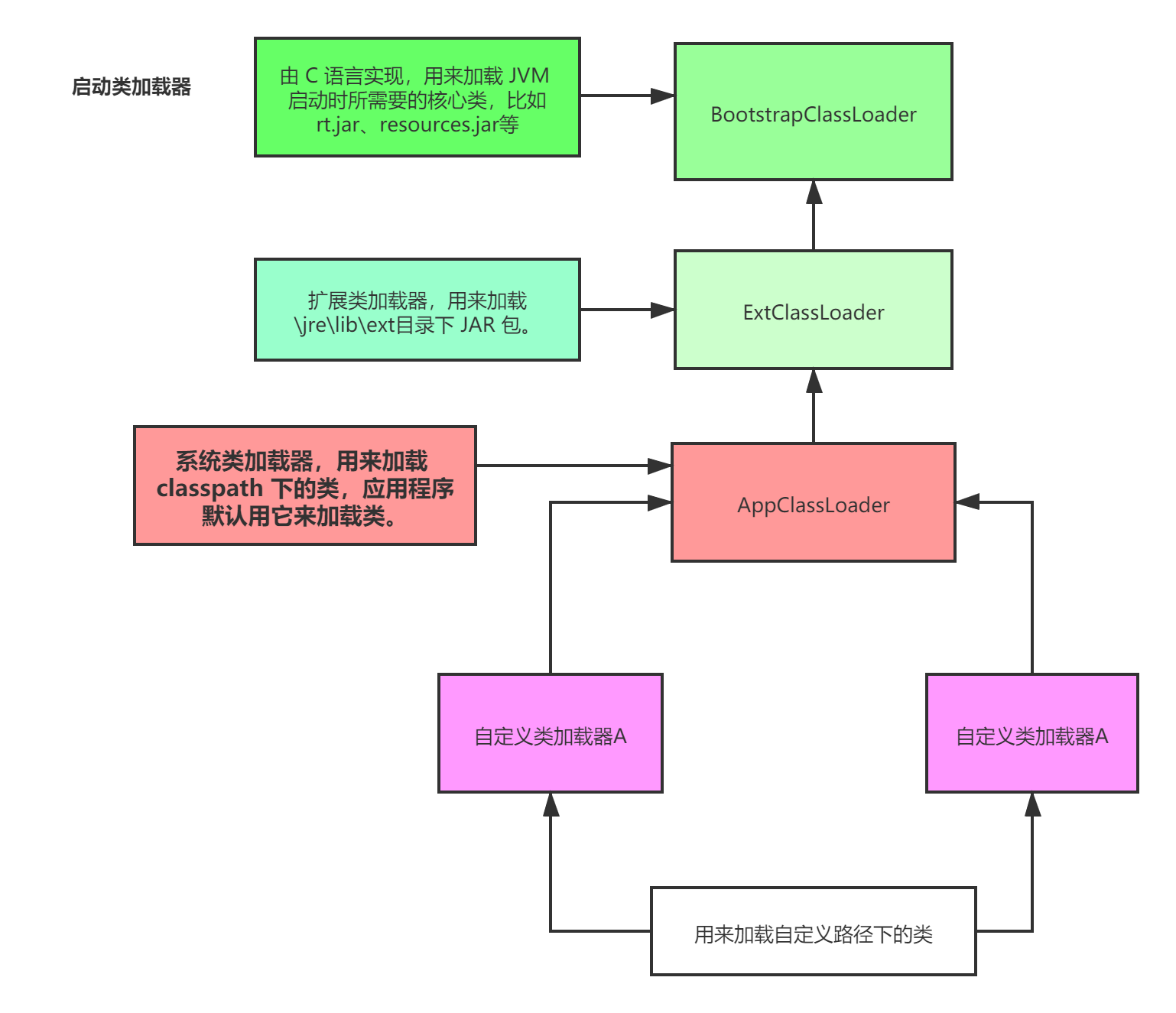
思考题(Tomcat的类加载机制)
一般用Java开发的Web系统,除非是基于Java写中间件,一般都是采用Tomcat之类的Web容器来部署的。
那么大家想想,Tomcat本身就是用Java写的,他自己就是一个JVM。
我们写好的那些系统程序,说白了,就是一堆编译好的.class文件放入一个war包,然后在Tomcat中来运行的。
那么,Tomcat的类加载机制应该怎么设计,才能把我们动态部署进去的war包中的类,加载到Tomcat自身运行的JVM中,然后去执行那些我们写好的代码呢?
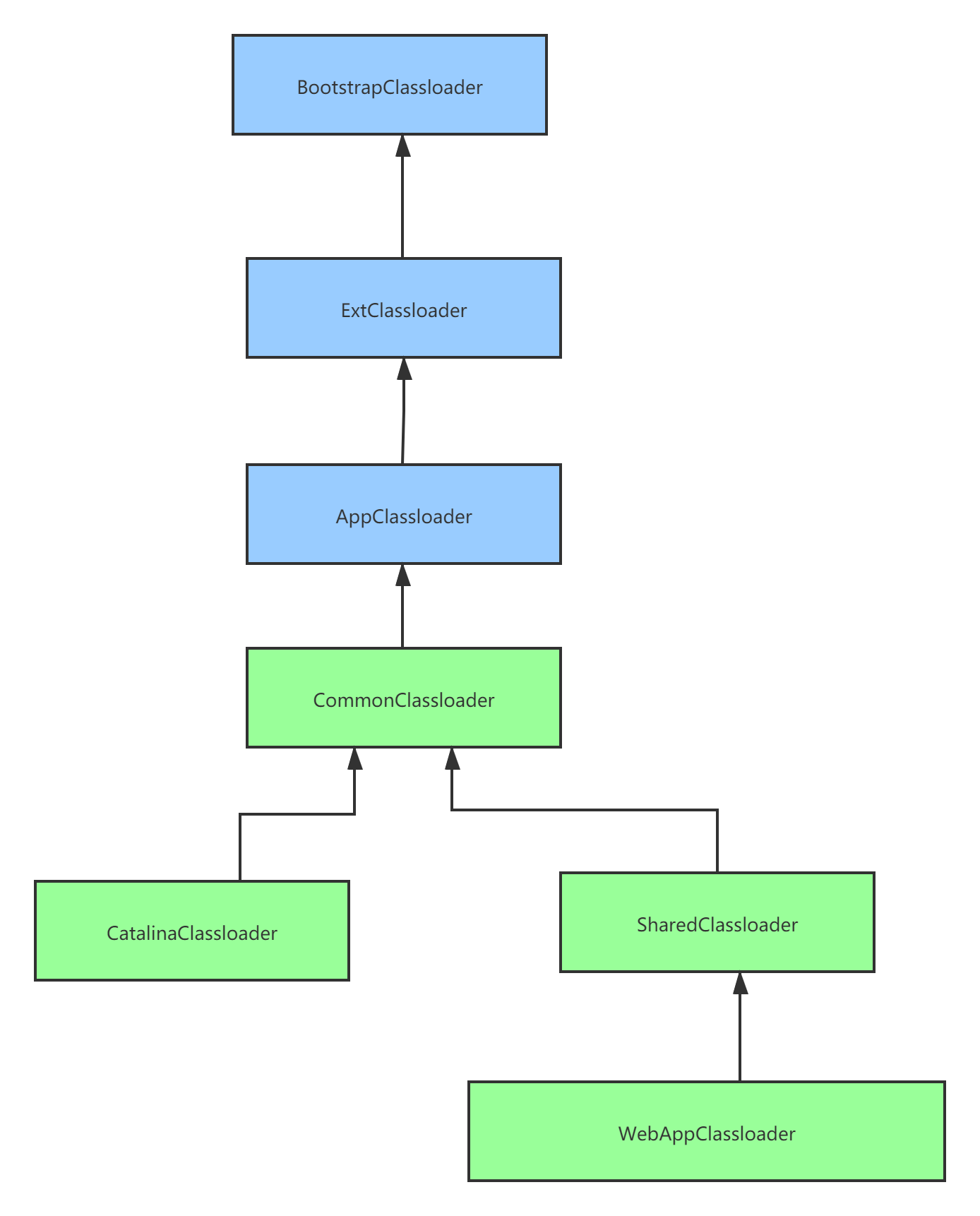
- Tomcat自定义了Common、Catalina、Shared等类加载器,其实就是用来加载Tomcat自己的一些核心基础类库的。
- 然后Tomcat为每个部署在里面的Web应用都有一个对应的WebApp类加载器,负责加载我们部署的这个Web应用的类
- 至于Jsp类加载器,则是给每个JSP都准备了一个Jsp类加载器。
Tomcat是打破了双亲委派机制的。
- 每个WebApp负责加载自己对应的那个Web应用的class文件,也就是我们写好的某个系统打包好的war包中的所有class文件(WEB-INF/classes目录下的class文件),不会传导给上层类加载器去加载。
Tomcat打破双亲委派机制
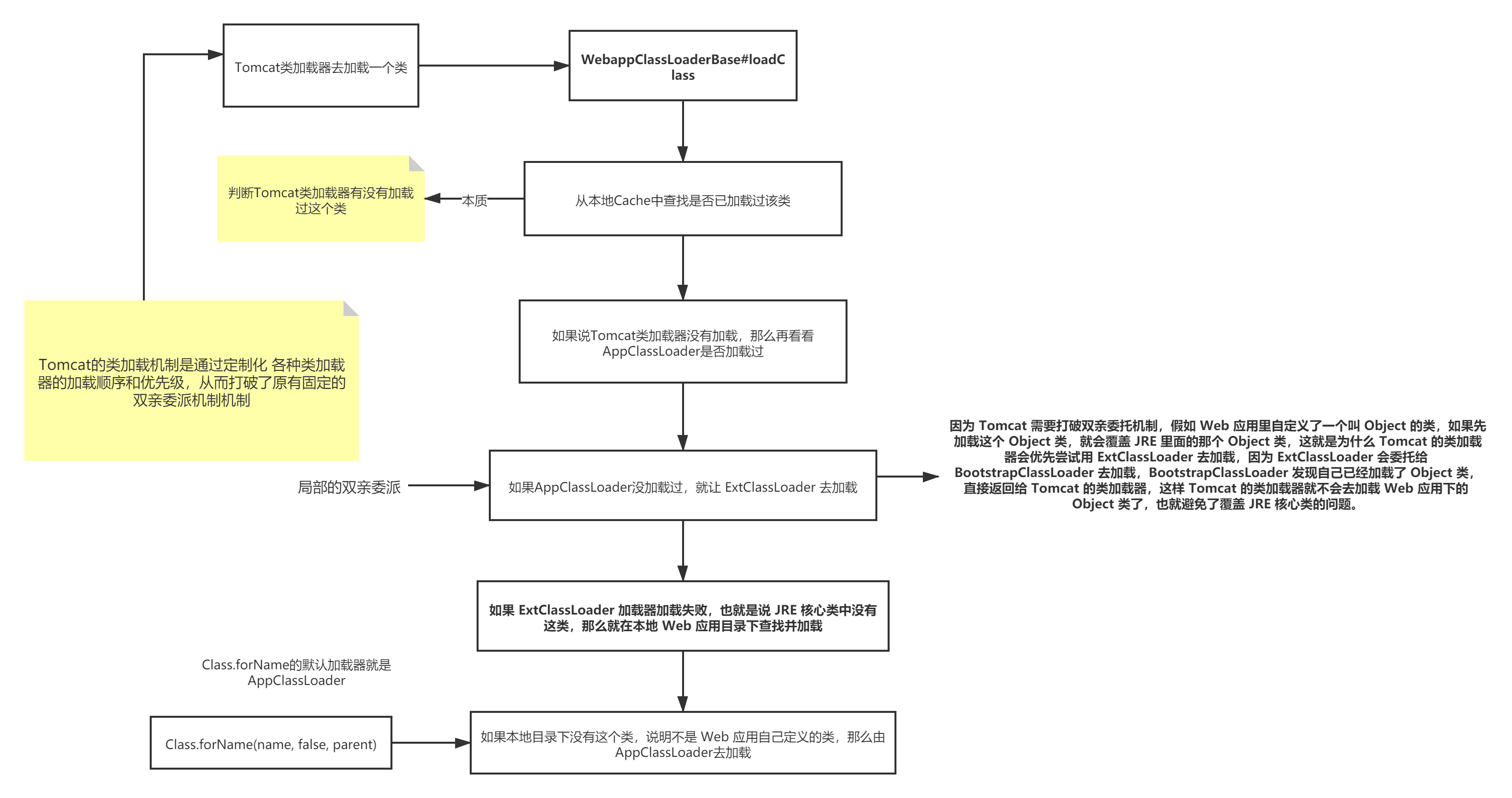
Tomcat类加载器的层次结构
JVM内存划分(大厂面试题)
程序计数器(线程私有)
.java 源文件 (计算机理解不了)编译成 .class字节码文件后,JVM会去执行字节码指令(基于字节码执行引擎)
字节码文件 -> 字节码 -> 字节码指令
字节码指令:一条条的机器指令,计算机只有在读取到机器指令时,才知道要干什么。
程序计数器就是用来记录当前执行的字节码指令的位置,就是说记录 执行到哪一行字节码指令了。
每个线程都有属于自己的程序计数器,专门记录当前线程执行到哪一条字节码指令了。(线程私有)
Java虚拟机栈(线程私有)
Java代码执行时,是被某一个线程执行的。
Java虚拟机栈主要用于保存每个方法内部的局部变量表等数据。
-
每个线程都有属于自己的Java虚拟机栈
-
一个线程在执行一个方法时,就会为该方法创建一个栈帧,并且压入线程的Java虚拟机栈
栈桢里包含这个方法的局部变量表、操作数栈、动态链接、方法出口等内容
本地方法栈
public native int hashCode()
堆
保存对象
方法区
用于存放从".class"文件里加载过来的类,同时包含常量池区域。
在Java 1.8以后,这块区域改成了MetaSpace(元数据空间),叫做元空间,不过还是存放各种类相关的信息。
常量池
堆外内存(不属于JVM管理)
通过NIO中的allocateDirect这种APl,可以在Java堆外分配内存空间。
然后,通过Java虚拟机里的DirectByteBuffer来引用和操作堆外内存空间。
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
ByteBuffer
说说这段代码执行时JVM发生了什么
public class Kafka{
public static void main(String[] args){
ReplicaManager replicaManager = new ReplicaManager();
replicaManager.loadReplicasFromDish();
}
}
public class ReplicaManager{
private long replicaCount;
public void loadReplicasFromDish(){
Boolean hasFinished = false;
if(isLocalDataCorrupt()){
// ...
}
}
public Boolean isLocalDataCorrupt(){
Boolean isCorrupt = false;
return isCorrupt;
}
}
-
首先会加载Kafka类
-
有一个main线程,准备执行Kafka.main方法,main线程关联了一个程序计数器,记录执行到哪一条字节码指令
-
然后开始执行main方法,main线程首先关联了一个Java虚拟机栈,会将main()方法的栈桢 压入虚拟机栈
ReplicaManager replicaManager = new ReplicaManager(); -
JVM打算创建ReplicaManager对象,但是发现ReplicaManager类尚未加载,则加载ReplicaManager Class
-
在堆内存中创建ReplicaManager对象,在main方法栈桢的局部变量表中加入replicaManager变量,让它引用ReplicaManager对象在Java堆内存中的地址
replicaManager.loadReplicasFromDish() -
创建loadReplicasFromDish方法对应的栈桢,压入 main线程关联的 Java虚拟机栈,以此类推
-
当Java虚拟机栈栈顶 的栈桢 对应方法执行完毕后,就会让栈桢出栈
JVM的垃圾回收机制
堆内存中的对象是占用内存资源的,内存资源是有限的。
不需要的对象,要进行垃圾回收。
垃圾回收线程
JVM本身是有垃圾回收机制的,他是一个后台自动运行的线程。
你只要启动一个JVM进程,他就会自带这么一个垃圾回收的后台线程。
这个线程会在后台不断检查JVM堆内存中的各个实例对象。
那么这个垃圾回收线程,就会把没人指向的实例对象给回收掉,从内存里清除掉,让它不再占用任何内存资源。
这样的话,这些不再被人指向的对象实例,即JVM中的“垃圾”,就会定期的被后台垃圾回收线程清理掉,不断释放内存资源。
创建的对象,到底在Java堆内存里会占用多少内存空间呢?
一个对象对内存空间(堆内存)的占用:
- 对象本身的一些信息
- 对象(包含)的实例变量作为数据占用的空间
-
比如对象头,如果在64位的linux操作系统上,会占用16字节
-
然后如果你的实例对象内部有个int类型的实例变量,他会占用4个字节,如果是long类型的实例变量,会占用8个字节。
-
如果是数组、Map之类的,那么就会占用更多的内存
加载到方法区中的类会被垃圾回收吗
什么时候被回收?为什么?
个人思考:
- 类 对应的ClassLoader被回收
- 类 对应的 实例对象 全部被回收
- 类 Class Object 不再被引用
JVM知识补充
-
方法走完,引用消失,堆内存还未必消失。好多人在做报表导出的时候,就会在for循环里不断的创建对象,很容易造成堆溢出,请问这种大文件导出怎么破?
建议不要在for里创建对象,可以在外面搞一个对象,for循环里对一个对象修改数据即可
-
新建的实例对象在堆内存,实例变量也是在堆内存
-
存在父类的情况下,如何加载?
加载父类就是父类,除非用到子类才会加载子类;但是加载子类要初始化之前,必须先加载父类,初始化父类
-
Java对象占用内存
Object Header(4字节) + Class Pointer(4字节)+ Fields(看存放类型),但是jvm内存占用是8的倍数,所以结果要向上取整到8的倍数。
-
为什么必须要一级一级类加载器的往上找,直接从顶层类加载器开始找不就行了吗?
每一层类加载器对某个类的加载,上推给父类加载器,到顶层类加载器,如果发现自己加载不到,再下推回子类加载器来加载,这样可以保证绝对不会重复加载某个类。
为什么不直接从顶层类加载器开始找,那是因为类加载器本身就是做的父子关系模型。
你想一下Java代码实现,他最底下的子类加载器,只能通过自己引用的父类加载器去找。如果直接找顶层类加载器,不合适的,那么顶层类加载器不就必须硬编码规定了吗?
这就是一个代码设计思想,保证代码的可扩展性。
-
双亲委派可以解决类重复加载的问题。按照文章中介绍每个类加载器有不同的类加载路径,这些类加载路径是否可能重叠?
不同类加载器的路径,一般是不会重叠的
-
类的初始化需要执行静态代码块,给静态成员变量赋值,是因为这些数据是在方法区吗?
没错,类在方法区,他在内存里,所以你必须给他初始化,赋值
-
Tomcat 类加载机制的图示
