

NLP——可在任何语言中分割自由文本数据
将文本转化为句子的语言不可知模型
将文本数据分割成句子可以说是一项简单的任务,文本可以通过'.'或'/n'字符分割成句子。然而,在自由文本数据中,这种模式并不一致,作者可以在句子中间断开一行,或者在错误的地方使用"."。这种现象在医疗访问摘要文本和对话/消息文本中很常见,例如。
为了克服这个问题,并为了开发一个可用于任何语言的通用模型,我们将在这篇文章中分享一个深度学习模型,以决定两个句子是否需要合并。
首先,我们将按照所有常见的字符来分割文本,例如'.'和'/n',然后给定两个句子,模型将决定它们是否必须合并。因此,该模型将给我们一个新的文本分句子的划分。
创建数据集
为了创建用于训练的数据集,考虑一个文章/案例/对话的列表,例如,来自维基百科的文章列表。我们将把正向对定义为一对应该被分割的句子,并保持两个不同的句子,在它们之间有"."。负数对是一对应该被合并的句子,并被视为一个句子,它们之间没有"."。我们将使用_nltk.send_tokenize_ 函数来创建正数对,用'.'来分割文本,这在大多数情况下都是真实的,并且会让模型学习'.'字符的机制和作用。我们将通过在中间分割句子来创建负数对,这意味着我们实际上不想分割句子。我们使用_min_sentence_length_for_splitting_ 参数来定义我们希望为负数对分割的最小句子长度(我们不希望分割太短的句子)。一个创建数据集的代码示例。
正面对的例子。
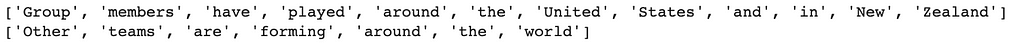
负面对的例子。

模型
我们训练了一个深度学习模型,将两个句子作为输入。对于第一句话,我们应用一个前向LSTM层,对于第二句话,我们应用一个后向LSTM层。我们使用一个前向层和一个后向层来预测中间是否应该有一个'.',所以我们希望第一句的前向层能嵌入第一句末尾的模式,第二句的后向层能嵌入第二句开头的模式。
然后,我们将这两个嵌入连接起来,以表示这两个句子的结束和开始的含义,从而预测它们是否应该被拆分(它们之间是否应该有一个'.')。
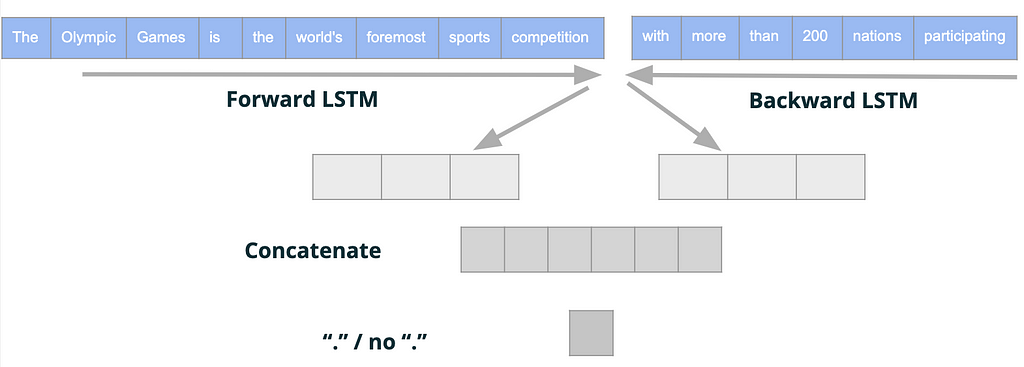
模型结构
下面的代码准备了语料库,并训练了一个标记器,用来将不同大小的句子转化为同等大小的序列。
X数据集是一个大小为_[样本数,2,句子长度]_ 的numpy数组_,_ y是一个数组,其中1-代表分割的句子,0-代表合并的句子。
然后我们训练深度学习模型。
最后,我们想把我们的模型应用于新的未见过的文本。我们使用_奥林匹克运动会_的维基百科页面,并从中提取句子。
下面的转换函数,得到一个分离的句子列表,并将合并后的句子作为一个新的文本划分的句子列表返回。
例如,我们随机地分割句子,并期望模型将它们合并成一个句子。
输出结果是。
意味着该模型正确地决定合并所有三个句子。
另一个例子,我们给了模型两个分离的句子,我们希望它能保持它们的分裂。
输出结果是:。

意味着该模型正确地决定将这两个句子分开。
结论
上述模型可以在任何语言中进行训练,所需要的只是创建数据集。然后,该模型被训练来决定是否需要将两个句子合并成一个句子,或者保持为两个分离的句子。该模型可用于预测新的一对句子的分裂/合并,并可应用于任何被共同字符分割成句子的文本,并提供新的句子划分。
我们将上述所有的代码总结在一个SentenceSplitter类中。
请欣赏!
