

用投票、装袋、提升和堆叠来改进你的模型
照片:Justin RoyonUnsplash
集合学习 是机器学习中使用的一种技术,它将多个模型组合成一个群体模型,换句话说,是一个_集合模型_。集合模型的目标是比每个模型单独的表现更好,或者如果不是,至少要和组内最好的单个模型表现一样好。
在这篇文章中,你将学习流行的合集方法。 投票, 袋法, 升压。和 堆叠以及它们的Python实现。我们将使用一些库,如 [scikit-learn](https://scikit-learn.org/stable/index.html)用于投票、装袋和提升,以及 [mlxtend](http://rasbt.github.io/mlxtend/)用于堆叠。
在关注文章的同时,我鼓励你查看我GitHub上的Jupyter笔记本,了解完整的分析和代码。🌻
简介
集合学习背后的直觉经常被描述为一种叫做 "人群智慧"的现象 ,这意味着由一群人做出的聚合决策往往比个人决策更好。有多种方法可以创建集合模型(或集合体),我们可以将其分为异质和同质集合体。
在异质合集中,我们将在同一数据集上训练的多个 异在异质集合中,我们将在同一数据集上训练的多个微调模型结合起来,生成一个集合模型。这种方法通常涉及_投票_、_平均_或_堆叠_技术。另一方面,在同质的集合体 中**,** 我们使用 同模型,我们称之为 "弱模型",并通过_袋化_和_提升_等技术将这个弱模型转换为强模型。
让我们从异质合集的基本合集学习方法开始。投票法和平均法。
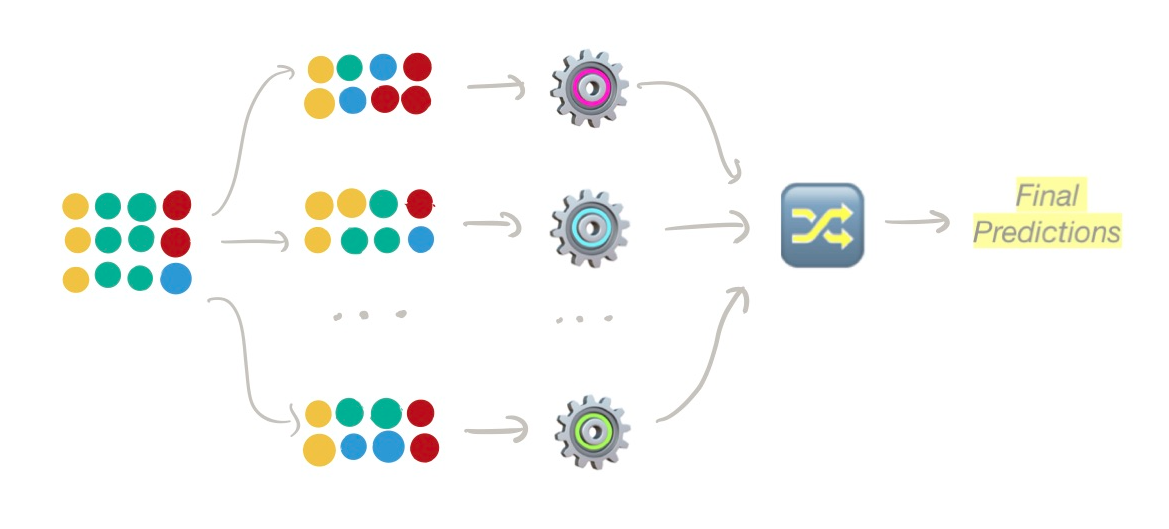
1.投票法(硬投票法
硬投票合集用于分类任务,它将基于多数投票原则在相同数据上训练的多个微调模型的预测结果结合起来。例如,如果我们将3个预测为 "A类"、"A类"、"B类 "的分类器进行合集,那么合集模型将根据多数票预测输出为 "A类",或者换句话说,根据单个模型预测的分布模式。正如你所看到的,我们倾向于拥有奇数的单个模型(如3、5、7个模型)以确保我们不会有相同的投票。
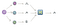
硬投票。用多个模型对新实例进行预测,并通过多数投票对最终结果进行集合投票- 图片来自作者
# Instantiate individual models
准确率得分。
KNeighborsClassifier 0.93
LogisticRegression 0.92
DecisionTreeClassifier 0.93
VotingClassifier 0.94 ✅
我们可以看到,投票分类器的准确率是最高的!由于合集将结合各个模型的预测,每个模型应该已经被微调过,并且已经表现良好。在上面的代码中,我只是为了演示的目的而初始化了它。
2.平均化(软投票
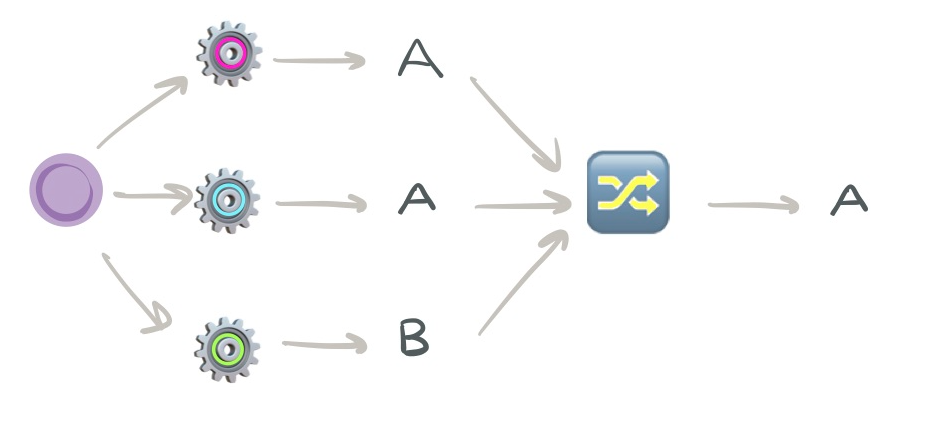
软投票用于分类和回归任务,它通过平均 来结合在同一数据上训练的多个微调模型的预测。对于分类,它使用预测_的概率_,对于回归,它使用预测_的值_。我们不需要像硬投票那样有奇数的单个模型,但我们需要至少有两个模型来建立一个集合。

软投票。用同等权重的模型(w)对新实例进行预测,合奏通过平均方式选择最终结果 - 图片由作者提供
软投票的一个优点是你可以决定是否要对每个模型进行平均加权(平均值)或按分类器的重要性加权,这是一个输入参数。如果你喜欢使用加权平均,那么集合模型的输出预测将是加权概率/值的最大总和。
# Instantiate individual modelsreg1 = DecisionTreeRegressor()reg2 = LinearRegression()
平均绝对误差。
DecisionTreeRegressor 3.0
LinearRegression 3.2
VotingRegressor 2.5 ✅
重要的是要明白,投票合集 (硬投票和软投票)的性能 ,严重依赖于单个模型的性能。如果我们将一个好的模型和两个表现一般的模型进行合集,那么合集模型将显示出与平均模型接近的结果。在这种情况下,我们要么需要改进平均表现的模型,要么就不应该进行合集,而是使用表现好的模型。📌
在了解了投票和平均数之后,我们可以继续学习最后一个异质合集技术。堆叠。
3.堆叠
堆积是 "堆积概括 "的意思,它将多个单独的模型(或基础模型)与一个最终的模型(或元模型)结合起来,该模型是用基础模型的预测值训练出来的。它可以用于分类和回归任务,可以选择使用数值或概率进行分类任务。
与投票集合的不同之处在于,在堆叠中,元模型也是一个可训练的模型,事实上,它是用基础模型的预测值来训练的。由于这些预测是元模型的输入特征,它们也被称为元特征。我们可以选择将初始数据集纳入元特征或只使用预测结果。

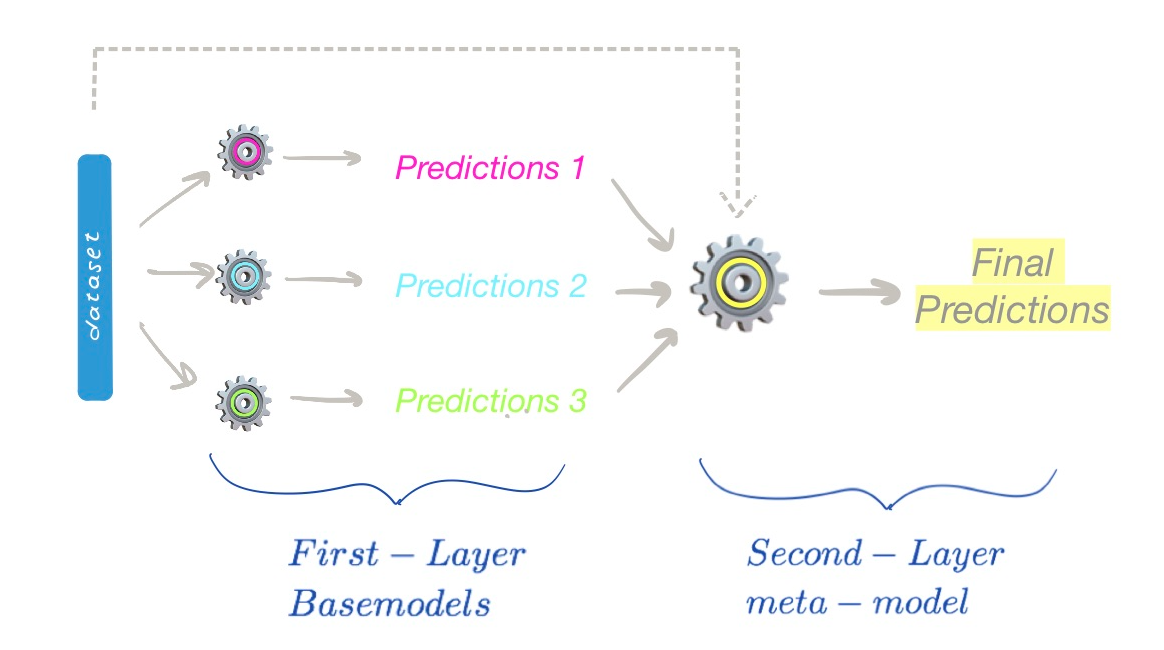
叠加。基准模型的预测用于元模型的训练,以预测最终的输出 - 图片由作者提供
堆叠可以用两层以上来实现:多层堆叠,我们定义基础模型,与另一层模型聚合,然后是最后的元模型。即使这能产生更好的结果,我们也应该考虑到由于复杂性而带来的时间成本。
为了防止过度拟合,我们可以使用交叉验证的堆叠来代替标准的堆叠,mlxtend库有这两个版本的实现。下面,我将实现。
1.分类任务的标准堆叠
from mlxtend.classifier import StackingClassifier
KNeighborsClassifier 0.84
GaussianNB 0.83
DecisionTreeClassifier 0.89
LogisticRegression 0.85
StackingClassifier 0.90 ✅。
2.用交叉验证法对回归任务进行堆叠
from mlxtend.regressor import StackingCVRegressor
平均绝对误差。
DecisionTreeRegressor 3.3
SVR 5.2
LinearRegression 3.2
StackingCVRegressor 2.9
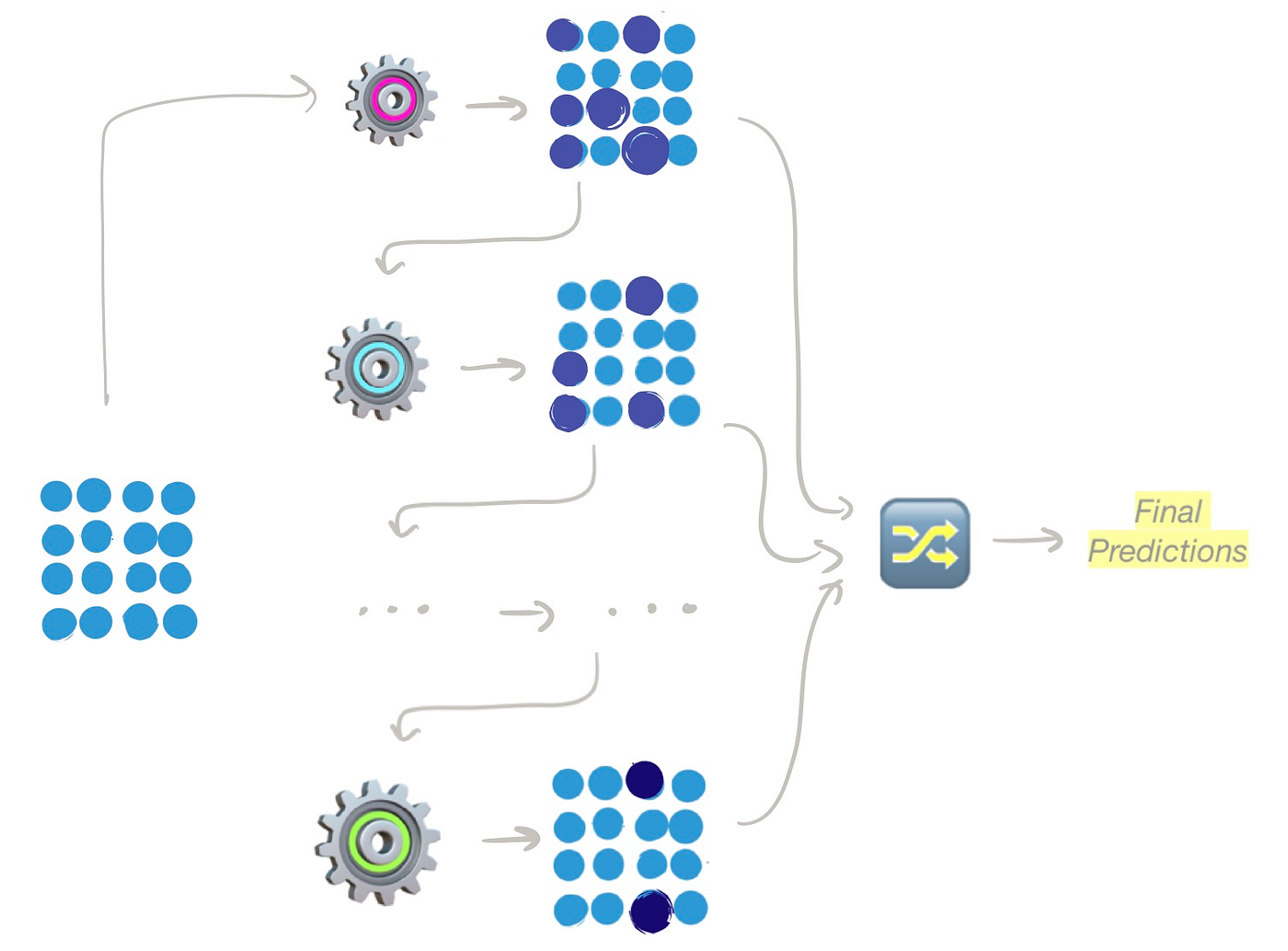
4.袋装化
Bootstrap聚合或简称 "Bagging "聚合了多个估计器,这些估计器使用_相同的_算法,用不同的训练数据子集训练。Bagging使用自举 法为每个估计器创建随机抽样的训练数据。
Bootstrapping 是一种从原始数据中创建替换样本的方法。它是用 替换 来使每个数据点被选中的概率相等。由于用替换法进行选择,一些数据点可能会被多次选中,而一些数据点可能从未被选中。我们可以 _用下面的公式_计算 出在大小 为n的 引导样本中,一个数据点未被选中的概率 。 (最好n是一个大数字)。
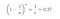
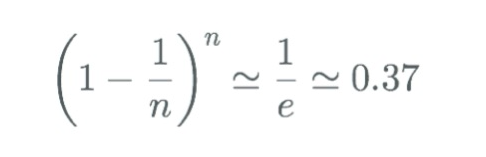
这意味着每个装袋估计器是用大约63%的训练数据集训练的,我们把剩下的37%称为袋外(OOB) 样本**。**
总而言之,bagging从_n个_估计器的原始训练数据中用替换法抽取_n个_训练数据集。每个估计器都在其抽样的训练数据集上进行平行训练以进行预测。然后,袋法使用硬投票或软投票等技术对这些预测进行汇总。

装袋。估算器使用的Bootstrapped训练样本和预测与投票技术相结合- 图片来自作者
在scikit-learn中,我们可以定义参数n_estimators ,等于_n_--我们想产生的估计器/模型的数量,如果我们想评估每个估计器在其袋外样本上的表现,oob_score ,可以设置为 "真"。通过这样做,我们可以很容易地学习估计器在未见过的数据上的性能,而无需使用交叉验证或单独的测试集。oob_score_ 函数计算所有 noob_scores的平均值,默认情况下,分类使用度量精度 分数,回归使用R^2。
from sklearn.ensemble import BaggingClassifier
分数:0.918
# Compare with test setpred = clf_bagging.predict(X_test)print(accuracy_score(y_test, pred))
准确度_分数: 0.916
随机抽样的训练数据集使训练不容易在原始数据上出现偏差,因此袋化技术减少了单个估计器的方差。
一个非常流行的袋化技术是随机森林,其中估计器被选为决策树。随机森林使用自举法来创建有替换的训练数据集,它还选择一组特征(无替换)来最大化每个训练数据集的随机性。通常情况下,选择的特征数量等于总特征数量的平方根。
5.提升法
提升法使用渐进式学习 ,这是一个迭代的过程,重点是最小化前一个估计器的误差。它是一种连续的方法,每个估计器都依赖于前一个估计器来提高预测结果。最流行的提升方法是自适应提升(AdaBoost)和梯度提升。
AdaBoost对每个_n个_估计器使用整个训练数据集,并进行一些重要的修改。第一个估计器(弱模型)是在原始数据集上用同等权重的数据点进行训练。在进行第一次预测并计算误差后,与正确预测的数据点相比,错误预测的数据点被赋予更高的权重。通过这样做,下一个估计器将专注于这些难以预测的实例。这个过程将一直持续到所有的_n个_ 估计器(比如1000个)依次训练完毕。最后,集合体的预测将通过加权多数投票或加权平均法获得。

AdaBoost。在训练数据中进行权重更新的顺序模型训练--图片来自作者
from sklearn.ensemble import AdaBoostRegressor
RMSE:4.18
梯度提升,与AdaBoost非常相似,用顺序迭代的方式改进以前的估计器,但不是更新训练数据的权重,而是将新的估计器与以前的估计器的残余误差 相适应。XGBoost、LightGBM和CatBoost是流行的梯度提升算法,特别是XGBoost是许多比赛的赢家,因其非常快速和可扩展而受到欢迎。
总结
在这篇文章中,我们已经学习了主要的集合学习技术来提高模型的性能。我们涵盖了每种技术的理论背景,以及相关的Python库来展示这些机制。
集合学习在机器学习中占有很大的比重,它对每个数据科学家和机器学习从业者都很重要。你可能会发现有很多东西需要学习,但我相信你永远不会后悔!!💯
如果你需要复习一下自举,或者你想了解更多的抽样技术,你可以看看我下面的文章。
我希望你喜欢阅读关于集合学习方法的文章,并发现这篇文章对你的分析很有帮助!
如果你喜欢这篇文章,你可以 在这里阅读我的其他文章 和 在Medium上关注我。 如果你有任何问题或建议,请告诉我。✨
