2.1 PAC学习模型
我们首先介绍几种定义和表示PAC模型所需的符号,这也将在这本书的大部分内容中使用。
定义2.1 泛化误差
假设h∈H,目标概念c∈C,潜在分布D,则h的泛化误差或风险定义为
R(h)=x∼DPr[h(x)=c(x)]=x∼DE[1h(x)=c(x)](2.1)
由于潜在分布D和目标概念c都是未知的,所以学习者无法直接了解假设的泛化误差。然而,我们可以在标记样本S上测量假设的经验误差。
定义2.2 经验误差
假设h∈H,目标概念c∈C,样本S = (x1,…,xm),则h的经验误差或经验风险定义为
R^(h)=m1i=1∑M1h(xi)=c(xi)(2.2)
因此,h∈H的经验误差是其平均误差样本,而泛化误差的预期错误基于分布误差D。我们会看到的本章及以下各章提供了与这两个方面有关的若干保证在某些假设下高频率出现。我们已经注意到,对于固定的h∈H,是基于i.i.d的经验误差期望。
样本S等于概化误差:
E[R^(h)]=R(h)(2.3)
事实上,根据期望的线性度和样本是通过i.i.d.提取的事实,对于样本S中的任意x,我们可以认为
S∼DmE[R^(h)]=m1i=1∑MS∼DmE[1h(xi)=c(xi)]=m1i=1∑MS∼DmE[1h(x)=c(x)]
因此:
S∼DmE[R^(h)]=S∼DmE[1h(xi)=c(xi)]=S∼DmE[1h(x)=c(x)]=R(h)
下面介绍PAC学习框架。我们通过成本上限O(n)的计算来表示任何元素x ∈X和按大小(c)的最大成本的计算在c ∈C。例如,Rn中的x可能是一个向量,而基于数组表示的成本在O (n)。
定义2.3 PAC学习
如果存在算法A和一个多项式函数poly(⋅,⋅,⋅,⋅),则称概念C是可学习的PAC,使得对于任何ϵ > 0和δ > 0上的分布D和任何目标概念c的分布c ∈ C, 以下适用于任何样本量m ≥ poly(1/ϵ,1/δ,n,size(c)):
S∼DmPr[R(hs)≤ϵ]≥1−δ(2.4)
如果A在poly(1/ϵ,1/δ,n,size(c)),那么C被认为是有效的可学习的PAC。当存在这样的算法A时,称为C的PAC学习算法。
因此,如果算法返回的假设1/ϵ和1/δ,近似正确(出错最多ϵ)且概率高(至少1 - δ),这证明了PAC。δ > 0 用来定义1−δ和ϵ > 0,精确度为1−ϵ。注意,如果算法的运行时间是1/ϵ和1/δ中的多项式,则如果算法接收到完整样本,则样本大小m也必须是多项式。
关于PAC的定义有几个要点需要强调。首先,PAC框架是一个无分布模型:对于抽取示例的分布D没有特别的假设,如图2.1所示。其次,根据相同的分布D绘制出用于定义误差的训练样本和测试样本。在大多数情况下,这是一般化的必要假设。
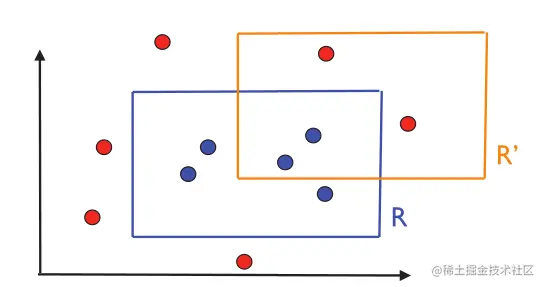
图2.1:目标概念R和可能的假设R'。圆圈表示训练实例。蓝色圆圈位于矩形R内是标记为1的点。其他则为红色并标记为0。
最后,PAC框架解决的是一个概念C的易学性问题,而不是一个特定的概念。注意,概念C是算法已知的,但目标概念c ∈ C是未知的。
在许多情况下,特别是当概念的计算没有很明确或很直接时,我们可能会忽略PAC定义中对n和大小(c)的多项式依赖,而只关注样本复杂度。
现在我们用一个具体的学习问题来说明PAC的可学习性。
例2.3 学习轴向矩形
考虑一组实例是平面中的点,x = R2,概念类C是位于R2中的所有轴对齐矩形的集合。因此,概念c是一个特定的轴对齐矩形内的点的集合。学习问题包括使用标记的训练样本以较小的误差确定一个轴对齐的目标矩形。我们将展示概念类的轴对齐矩形是PAC可学习的。
图2.1说明了这个问题。R表示目标轴对齐矩形,R'是一个假设。从图中可以看出,R'的误差区域由矩形R内但在矩形R'外的区域和R'内但在矩形R外的区域构成。第一个区域对应的是假阴性,即标记为0或R'为负的点,实际上是为正或标记为1的点。第二个区域对应于假阳性,也就是说,用R'正标记的点实际上是负标记的点。
为了证明概念类是PAC是可学习的,我们用一个简单的PAC学习算法A来描述。给定一个标样本S,该算法包括返回最紧的轴对齐矩形 R' = Rs,其中包含标记为1的点。图2.2给出了算法返回的假设。根据定义,其点必须包含在目标概念R中,所以Rs不会产生任何假阳性。因此,Rs的误差区域包括在R中。
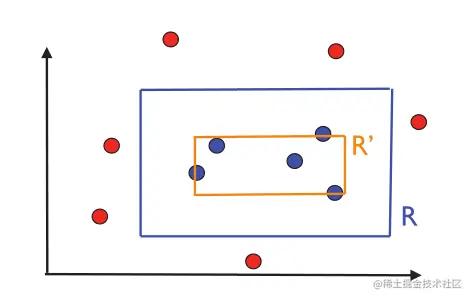
图2.2:算法返回的假设R' = Rs的说明。
设R∈C为目标概念。其中ϵ > 0。设Pr[RS]表示被RS罚款的概率质量,即根据D随机绘制的点落在RS范围内的概率。由于我们的算法所产生的误差可能只由落在RS内的点引起,我们可以假设Pr[RS] > ϵ;否则,RS的误差小于或等于ϵ,与接收到的训练样本 S 无关。
现在,由于Pr[RS] > ϵ,我们可以沿着RS的边定义四个矩形区域r1,r2,r3和r4,每个区域的概率至少是ϵ/4。这些区域可以沿着一条边从空矩形开始并增加其大小,直到其分布质量至少为ϵ/4。图2.3说明了这些区域的定义。
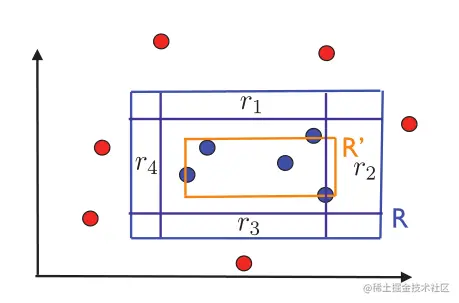
图2.3:区域r1,…,r4的说明。
注意,如果RS满足所有这四个区域,由于它是一个矩形,它将在这四个区域中各有一条边(几何参数)。它的误差区域,即R中没有覆盖的部分,包含在这些区域中,其概率不可能大于ϵ。通过对位,如果R(RS)>ϵ,则RS必须至少错过一个区域ri,i∈[1,4]。因此,我们可以认为
S∼DmPr[R(Rs)>ϵ]≤S∼DmPr[Ui=14{Rs⋂ri=∅}](2.4)
≤i=1∑4S∼DmPr[{Rs⋂ri=∅}](受联合约束)
≤4(1−ϵ/4)m(从Pr[ri]>ϵ/4)
≤4exp(−mϵ/4)(从Pr[ri]>ϵ/4)
在最后一步中,对于所有x∈R2我们使用一般恒等式1−x≤e−x。对于任何δ > 0,确保RrS∼Dm[R(RS)>ϵ]≤δ,我们可以进一步认为
4exp(−ϵm/4)≤δ⇔m≥ε4logδ4(2.6)
因此,对于任何ϵ>0和δ>0,如果样品尺寸m大于ε4logδ4,那么RrS∼Dm[R(RS)>ϵ]≤1−δ。此外,R2和轴对齐矩形中点表示的计算成本可通过以下公式定义,他们的四个角,是不变的。这证明了轴向矩形的概念类是可学习的PAC,且可学习的PAC轴向矩形样本复杂度为O(ε1logδ1)。
在本书中,我们经常会看到类似于(2.6)的示例复杂性结果的等效方法,是给出泛化界限。它表示概率至少为1−δ、R(RS)的上界取决于样本量m和δ。它表明,在概率至少为1−δ的情况下,R(RS)的上限是取决于样本大小m和δ的某个量。为了得到这一点,如果满足δ等于(2.5)中推导出的上界,即δ=4exp(−mϵ/4),就可解出ϵ。当概率至少为1−δ时,算法的有界误差为:
R(RS)≤m4logδ4(2.7)
在这个例子中可以考虑其他PAC学习算法。例如,一种替代方法是返回不包含负值的最大轴对齐矩形。本文所给出的最紧轴对齐矩形的PAC学习,可以很容易地应用于其他这类算法的分析。
注意,我们在这个例子中考虑的假设集H与概念类C相符的情况,其基数是无限的。尽管如此,这个问题还是证明了PAC学习是简单的。然后我们可能会问,类似的证明是否可以轻易地应用于其他类似的概念类。这并不是很简单,因为证明中使用的具体几何参数才是关键。将证明扩展到其他概念类是很重要的,就比如非同心圆的概念类。因此,我们需要更普遍的证明技术和更普遍的结果。接下来的两部分将在有限假设集的情况下为我们提供这些工具。


