并发和并行区别
1.并发
- 简单来说就是同一时间有多个事情要做,比如:一个web server同一时刻需要处理100个请求
2.并行
- 同一时刻处理多个事情,比如:一个web server同一时刻开100个线程处理100个请求
3.并发并行区别
- 可以看到并行是并发到处理方法,并发还有其他处理方法,比如加服务器
4.生活中的例子
- 高速路口堵了100辆车,这是一个并发问题,高速路口需要处理这100辆车,解决方法是开辟多个高速路口,同时处理,这是并行。
进程和线程
1.进程
- 可以理解为申请操作系统资源的最小单位。我们写的程序是存在硬盘中,当加载到内存后运行就是进程。
2.线程
- 是操作系统调度的最小单位,代码执行是由线程执行,一个进程中最少有一个线程,要不然代码跑不起来
3.线程的状态
| 状态 | 含义 |
|---|
| 就绪 | 线程准备好代码所需要的资源,等待操作系统分配时间片运行 |
| 运行 | 正在运行代码 |
| 阻塞 | 线程等待其他事件完成,比如IO操作 |
| 终止 | 线程停止运行 |
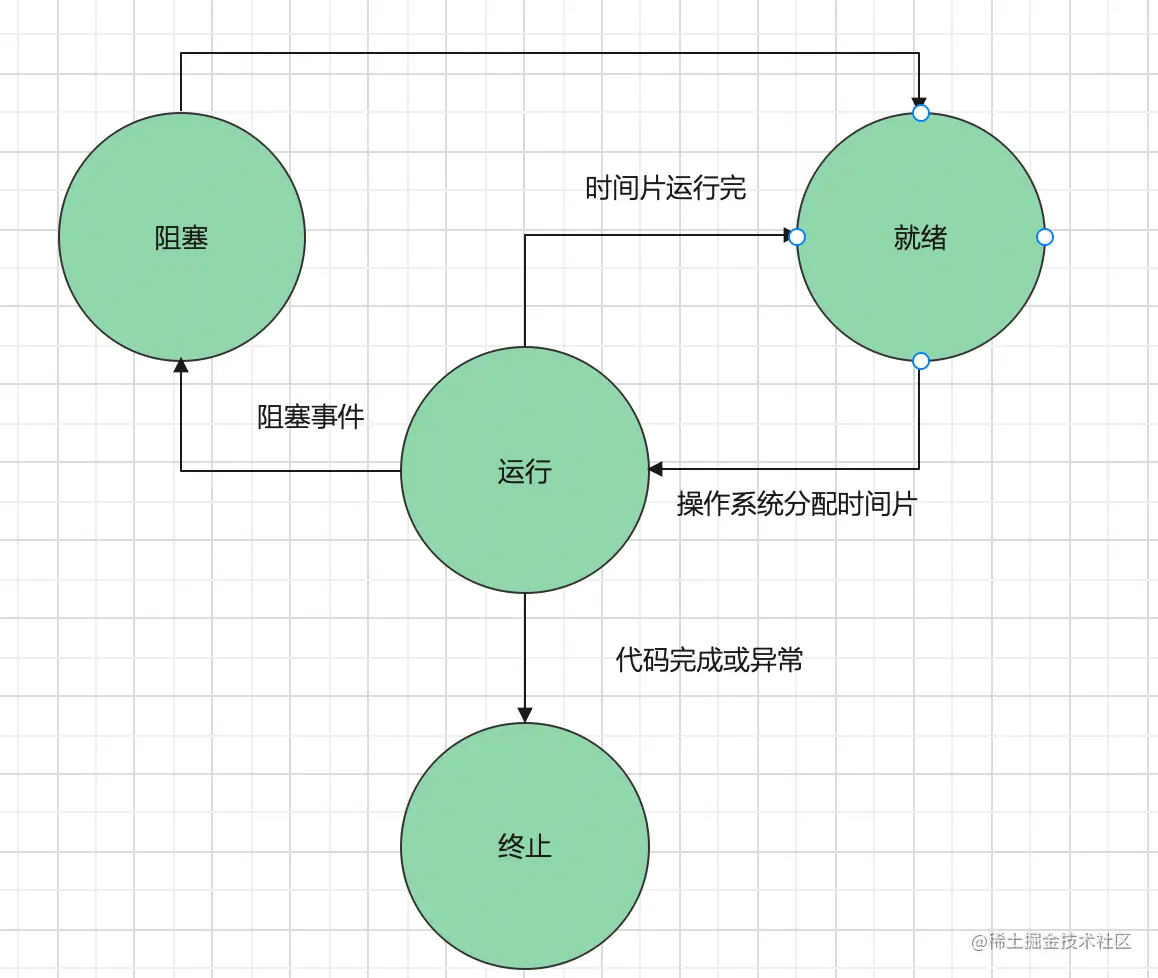
- 从上图来看,终止态的线程是无法在转换到其他状态
- 运行态和就绪态可以相互转换,就绪态线程分配时间片就变成运行态,运行态线程时间片用完就变成就绪态
- 运行态的线程遇到阻塞事件就会变成阻塞态,会让出cpu,所以阻塞态只能先转换成就绪态,然后等待操作系统分配时间片
python线程开发
1.Thread类
- def _init_(self, group=None, target=None, name=None,
args=(), kwargs=None, *, daemon=None):
- group没啥用,设置为None,target指向运行的函数对象,name是给线程取个名字,args传一个元祖,是target指向的函数的参数,kwargs传一个字典,和args同样用处,deamon True或False,设置线程是否为daemon线程,daemon线程会在主线程退出后退出,不是daemon线程,当主线程退出时会等待其他线程退出后再退出
import threading
def worker():
print("i am worker thread")
print("done")
t = threading.Thread(target=worker, name="worker")
print("i am main thread")
print("done")
t.start()
- 上面代码会在worker线程执行完后退出,要想worker线程一直工作,提供一个死循环就好,因为默认是非deamon线程,所以主线程执行完后需要等待其他非daemon线程执行完后退出
import threading
import time
def worker():
while True:
print("i am worker thread")
print("done")
time.sleep(0.5)
t = threading.Thread(target=worker, name="worker")
print("i am main thread")
print("done")
t.start()
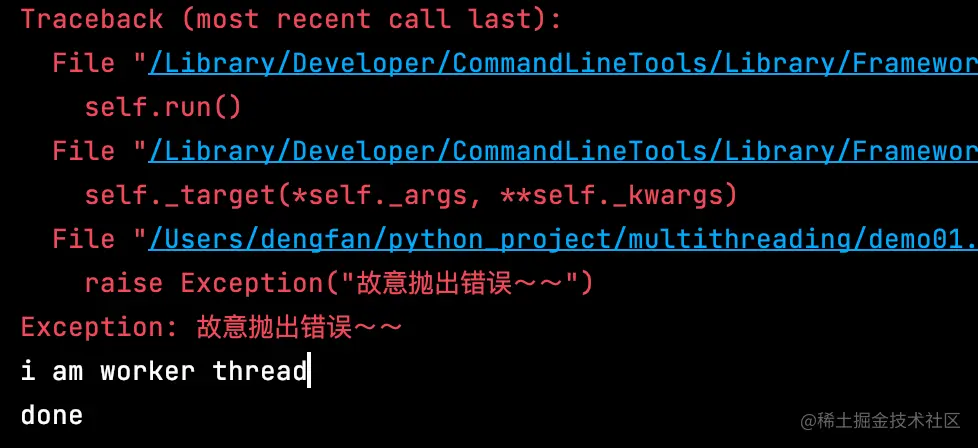
- thread类没有退出的方法,所以只能执行完代码或抛出异常才能退出
import threading
import time
def worker():
count = 0
while True:
print("i am worker thread")
print("done")
count += 1
if count == 5:
raise Exception("故意抛出错误~~")
time.sleep(0.5)
t = threading.Thread(target=worker, name="worker")
print("i am main thread")
print("done")
t.start()
import threading
def testAdd(x, y):
print(f"{x} + {y} = {x + y}")
t1 = threading.Thread(target=testAdd, name="t1", args=(1, 2))
t2 = threading.Thread(target=testAdd, name="t1", kwargs={"x": 10, "y": 20})
t3 = threading.Thread(target=testAdd, name="t1", args=(100,), kwargs={"y": 200})
t1.start()
t2.start()
t3.start()
| 方法 | 含义 |
|---|
| current_thread() | 返回当前的线程对象 |
| main_thread() | 返回主线程对象 |
| activ_count() | 当前处于alive状态线程个数 |
| enumerate() | 存活的线程列表,只针对运行态 |
| get_ident() | 返回当前线程id |
import threading
import time
def showThreadInfo():
print(f"当前线程对象:{threading.current_thread()}, alive线程个数:{threading.activeCount()},运行线程列表:{threading.enumerate()}")
def work():
showThreadInfo()
for i in range(10):
time.sleep(0.5)
t1 = threading.Thread(target=work, name='worker')
showThreadInfo()
t1.start()
time.sleep(1)

| 名称 | 含义 |
|---|
| name | 线程名 |
| ident | 线程id |
| is_alive() | 线程是否存活 |
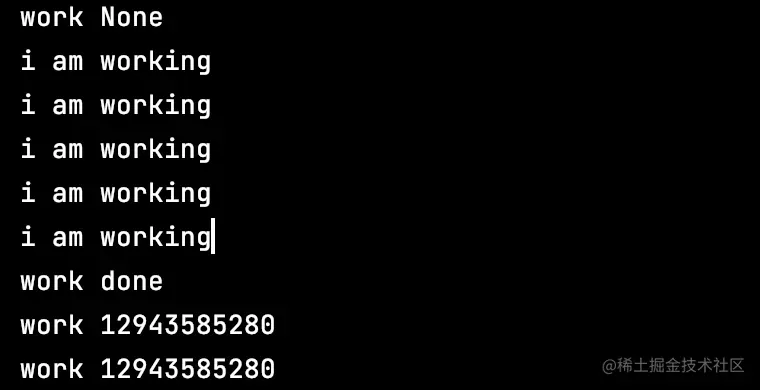
import threading
import time
def work():
for i in range(5):
print("i am working")
print("work done")
t = threading.Thread(target=work, name="work")
print(t.name, t.ident)
t.start()
while True:
print(t.name, t.ident)
time.sleep(1)
2.多线程
import threading
import time
def work(f=sys.stdout):
t = threading.currentThread()
for i in range(5):
print(t.name, t.ident, file=f)
time.sleep(1)
t1 = threading.Thread(target=work, name="t1")
t2 = threading.Thread(target=work, name="t2", args=(sys.stderr, ))
t1.start()
t2.start()

- 多线程的特点就是不确定性,因为线程获取操作系统时间片并不是按照顺序来的
- 每一个进程至少有一个主线程用来启动程序,然后程序可以创建其他线程使用
3.daemon线程
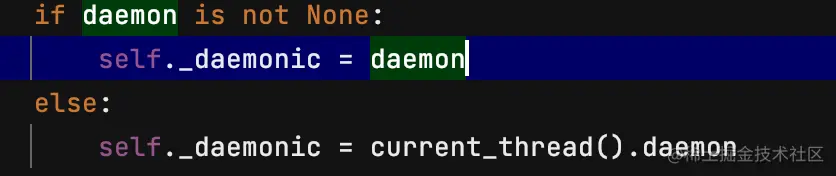
- 从源码来看如果没有设置daemon属性就会继承当前线程的daemon熟悉,主线程默人不是daemon线程,也就是说在主线程中创建线程默认不是daemon线程,当主线程代码执行完后会等待其他线程执行完成。
import threading
import time
def work():
for i in range(10):
print("i am working")
time.sleep(1)
t1 = threading.Thread(target=work, name="worker", daemon=True)
t1.start()
time.sleep(1)
print("end")

| 名称 | 含义 |
|---|
| daemon | 表示是否是daemon线程 |
| isDaemon() | 是否是daemon线程 |
| setDaemon() | 设置为daemon线程,必须在start之前 |
4.join()方法
import threading
import time
def work():
for i in range(5):
print(f"{threading.current_thread().name} is working")
time.sleep(0.5)
t1 = threading.Thread(target=work, name="worker1", daemon=True)
t1.start()
t1.join()
print("end")
- 没有执行t1.join()方法,那么当主线程打印完end后退出程序
- 执行t1.join()后,主线程会阻塞,等待t1线程执行完成

- 也可以设置一个join的超时时间,当超过指定时间会继续执行当钱线程代码
import threading
import time
def work():
for i in range(5):
print(f"{threading.current_thread().name} is working")
time.sleep(0.5)
t1 = threading.Thread(target=work, name="worker1", daemon=True)
t1.start()
t1.join(1)
print("end")

GIL
- 简单来说就是CPython解释器中有一把全局锁,保证改进程中只有一个线程执行代码,其他线程处于阻塞状态。
- 如果线程是io密集性工作,那么线程会释放GIL锁,其他线程获取GIL锁就会执行代码,较好使用多线程
- 如果线程是cpu密集型工作,线程不会释放GIL锁,其他线程几乎无法使用cpu,所以python多线程执行io操作比较合适,如果是cpu操作,那么和单线程一样,并且还有线程安全的问题。
import datetime
import threading
def work():
num = 0
for i in range(100000000):
num += 1
start = datetime.datetime.now().timestamp()
for i in range(2):
work()
end = datetime.datetime.now().timestamp()
print(f"单线程时间{end - start}")
t1 = threading.Thread(target=work, name="t1")
t2 = threading.Thread(target=work, name="t2")
start = datetime.datetime.now().timestamp()
t1.start()
t2.start()
t1.join()
t2.join()
end = datetime.datetime.now().timestamp()
print(f"多线程时间{end - start}")

多进程
- 和多线程使用类似,不过使用的是multiprocessing模块的Process类
import datetime
import multiprocessing
def work():
n = 0
for i in range(100000000):
n += 1
if __name__ == "__main__":
start = datetime.datetime.now().timestamp()
work()
work()
end = datetime.datetime.now().timestamp()
print(f"单进程花费时间:{end - start}")
p1 = multiprocessing.Process(target=work, name="p1")
p2 = multiprocessing.Process(target=work, name="p2")
start = datetime.datetime.now().timestamp()
p1.start()
p2.start()
p1.join()
p2.join()
end = datetime.datetime.now().timestamp()
print(f"多进程花费时间:{end - start}")

- 这一次程序就发挥了多核cpu的优势,只用了一半多时间完成代码
concurrent.futures包
1.ThreadPoolExecutor对象
| 方法 | 含义 |
|---|
| ThreadPoolExecutor(max_workers=1) | 线程池线程个数,返回Executor实例 |
| submit(fn, *args, **kwargs) | 提交函数和参数,返回Future类的实例 |
| shutdown(wait=True) | 线程关闭,wait为True表示等待线程执行完 |
| 方法 | 含义 |
|---|
| done() | 如果调用被成功的取消或者执行完成,返回True |
| cancelled() | 如果调用被成功的取消,返回True |
| running() | 如果正在运行且不能被取消,返回True |
| cancel() | 尝试取消调用。如果已经执行且不能取消返回False,否则返回 True |
| result(timeout=None) | 取返回的结果,timeout为None,一直等待返回;timeout设置到 期,抛出concurrent.futures.TimeoutError |
| exception(timeout=None) | 取返回的异常,timeout为None,一直等待返回;timeout设置到 期,抛出concurrent.futures.TimeoutError |
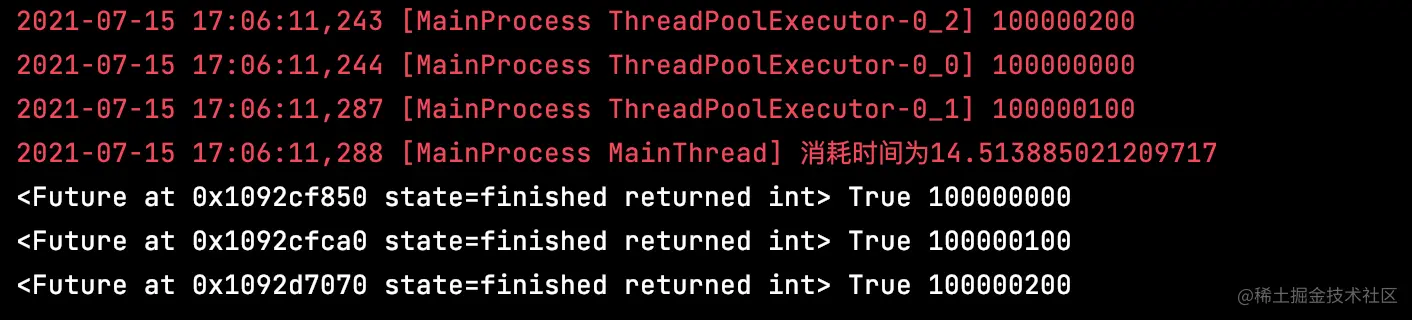
import datetime
import logging
from concurrent.futures import ThreadPoolExecutor, wait
FORMAT = "%(asctime)s [%(processName)s %(threadName)s] %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
def calc(base):
for i in range(100000000):
base += 1
logging.info(base)
return base
start = datetime.datetime.now().timestamp()
executor = ThreadPoolExecutor(3)
with executor:
fs = []
for i in range(3):
f = executor.submit(calc, i * 100)
fs.append(f)
wait(fs)
end = datetime.datetime.now().timestamp()
logging.info(f"消耗时间为{end-start}")
for f in fs:
print(f, f.done(), f.result())
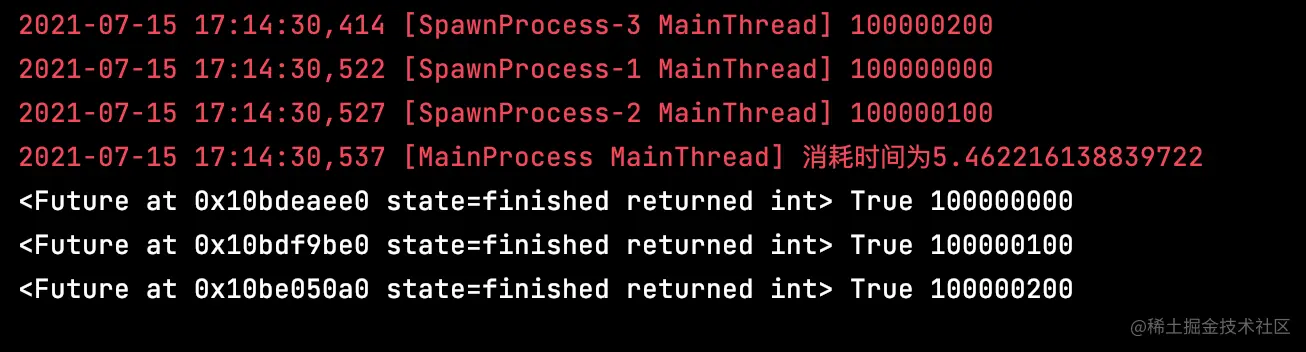
2.ProcessPoolExecutor对象
import datetime
import logging
from concurrent.futures import wait, ProcessPoolExecutor
FORMAT = "%(asctime)s [%(processName)s %(threadName)s] %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
def calc(base):
for i in range(100000000):
base += 1
logging.info(base)
return base
if __name__ == "__main__":
start = datetime.datetime.now().timestamp()
executor = ProcessPoolExecutor(3)
with executor:
fs = []
for i in range(3):
f = executor.submit(calc, i * 100)
fs.append(f)
wait(fs)
end = datetime.datetime.now().timestamp()
logging.info(f"消耗时间为{end - start}")
for f in fs:
print(f, f.done(), f.result())
线程同步
- 线程同步,线程间协同,通过某种技术,让一个线程访问某些数据时,其他线程不能访问这些数据,直到该线程完成对数据的操作。
1.event
| 方法 | 含义 |
|---|
| set() | 标志符设置为True |
| clear() | 标志符设置为False |
| is_set() | 是否设置为True |
| wait(timeout=None) | 设置等待标记为True的时长,None为无限等待。等到返回True,未等到 超时了返回False |
import logging
import threading
import time
FORMAT = "%(asctime)s [%(processName)s %(threadName)s] %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
def boss(event):
logging.info("i am watching you working")
event.wait()
logging.info("good job")
def worker(event, count):
logging.info("i am working for boss")
cups = []
while True:
logging.info("1 cup was make")
time.sleep(0.5)
cups.append(1)
if len(cups) == count:
event.set()
break
event = threading.Event()
t1 = threading.Thread(target=boss, name="boss", args=(event,))
t2 = threading.Thread(target=worker, name="worker", args=(event, 10))
t1.start()
t2.start()
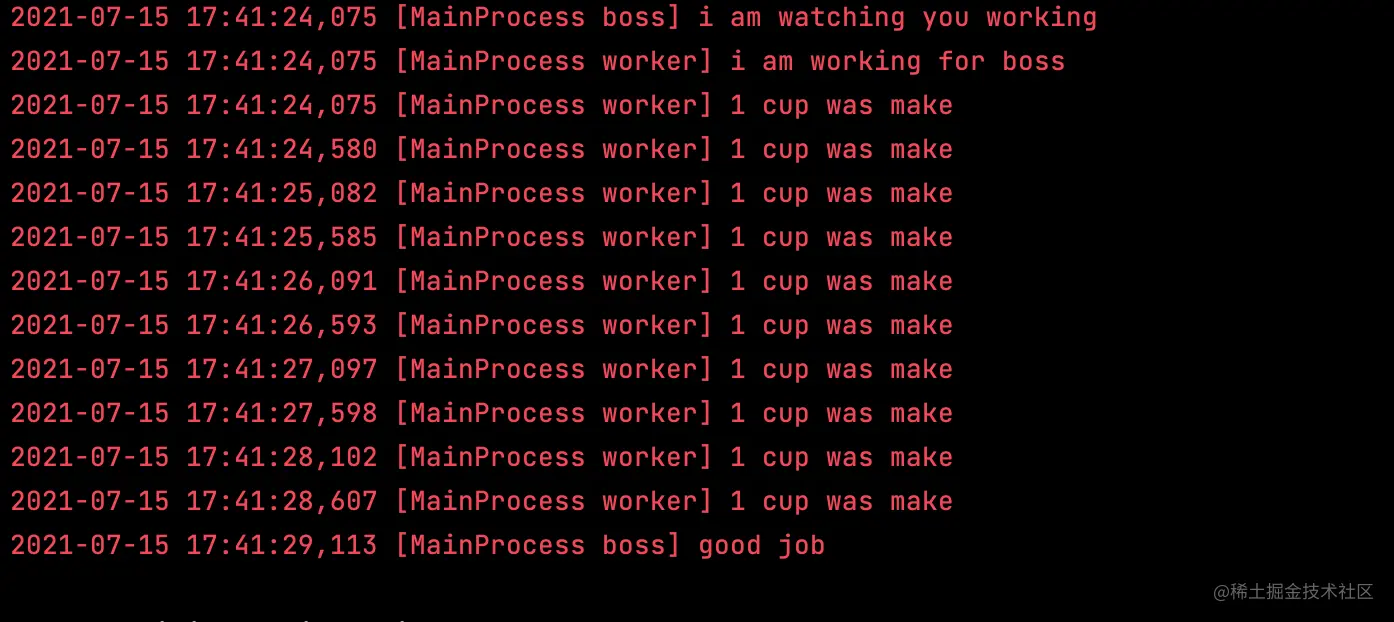
- 还是非常简单的,生产完被子后,把标志符设置为True,boss线程就接着执行,可以有多个wait线程
import logging
import threading
FORMAT = "%(asctime)s [%(processName)s %(threadName)s] %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
def boss(event):
logging.info("i am watching you working")
event.wait()
logging.info("good job")
def worker(event, count):
logging.info("i am working for boss")
cups = []
while not event.wait(0.5):
logging.info("1 cup was make")
cups.append(1)
if len(cups) == count:
event.set()
event = threading.Event()
t1 = threading.Thread(target=boss, name="boss1", args=(event,))
t2 = threading.Thread(target=boss, name="boss2", args=(event,))
t3 = threading.Thread(target=worker, name="worker", args=(event, 10))
t1.start()
t2.start()
t3.start()

2.Lock
- Lock类是mutex互斥锁 一旦一个线程获得锁,其它试图获取锁的线程将被阻塞,只到拥有锁的线程释放锁 凡是存在共享资源争抢的地方都可以使用锁,从而保证只有一个使用者可以完全使用这个资源。
| 名称 | 含义 |
|---|
| acquire(blocking=True, timeout=-1) | 默认阻塞,阻塞可以设置超时时间。非阻塞时,timeout禁止 设置。成功获取锁,返回True,否则返回False |
| release() | 释放锁。可以从任何线程调用释放。 已上锁的锁,会被重置为unlocked 未上锁的锁上调用,抛RuntimeError异常。 |
from threading import Thread, Lock
import time
import logging
FORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)
cups = []
lock = Lock()
def worker(count=1000):
logging.info("I'm working")
while True:
lock.acquire()
if len(cups) >= count:
lock.release()
break
time.sleep(0.0001)
cups.append(1)
lock.release()
logging.info('I finished my job. cups = {}'.format(len(cups)))
for i in range(1, 11):
t = Thread(target=worker, name="w{}".format(i), args=(1000,))
t.start()


