对于集群来说,什么是客户端
可以理解为:
客户端是一台可以去访问集群,向集群发送/获取数据文件,可以执行分布式作业的机器(服务器)。
客户端就像是一个抓手,有了这个抓手,我们就可以去使用集群.
在Hadoop和Spark(或者mapreduce,或者storm)集群搭建好了之后,
如果我们需要向集群中发送、获取文件,或者执行MapReduce、Spark作业,
我们的做法通常是搭建一个外围的、集群的客户端,在这个客户端上进行操作。
而不是直接在集群的NameNode或者DataNode上进行。
此时,集群和客户端的结构如下图(简化图,没有考虑NameNode的高可用),本文将介绍如何快速搭建一个集群客户端(有时也叫gateway)。
下图就是hadoop集群和客户端的结构。
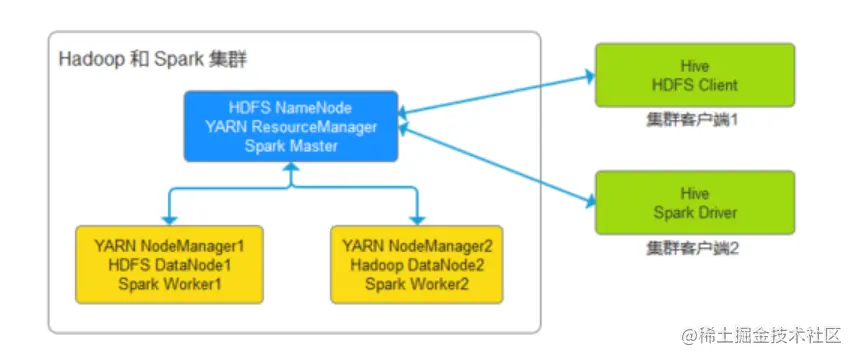
在上图的网络配置方面,可以遵循集群仅开放内网访问(因为集群内的服务器一般不需要同外部环境有交流),
而客户端开放外网访问,所有对集群的访问和管理,均通过客户端来完成。
配置集群客户端的步骤
<1>配置hosts
客户端的主机名是dc1(DataClient1的缩写,192.168.0.150),
Hadoop集群中的NameNode主机名hadoop01(192.168.0.34)。
我们只需要让客户端和namenode这两台机器认识就可以了,不需要让客户端和集群中的所有机器都认识。
首先配置hosts让两台机器相互“认识”一下:
修改dc1的hosts,把hadoop001添加进去,这样客户端就认识了namenode节点
#vim /etc/hosts
添加:192.168.0.34 hadoop01
修改hadoop01的hosts,把客户端添加进去,这样namenode就认识了客户端了。
#vim /etc/hosts
添加:192.168.0.150 dc1
当数据中心的服务器很多时,配置hosts可能不够方便,此时可以部署一台DNS(Domain Name Service)服务器,用于解析主机名。
<2>配置ssh免密登录
把客户端的.ssh目录下的公钥文件中的公钥,添加到namenode服务器的.ssh/authorized_keys文件中。
<3>复制~/.bashrc文件(环境变量配置文件)
接下来,还要配置一下$HADOOP_HOME、$JAVA_HOME等环境变量,
实际就是拷贝一下~/.bashrc文件
就是把namenode机器上的.bashrc文件复制到客户端上
<4>安装java和hadoop
安装java和hadoop的操作很简单,只需要将hadoop01上的Hadoop和Java文件夹复制到dc1就可以了。
此时,可能会疑惑,这样不是就和安装和配置Hadoop集群节点一样了,好像又往集群中添加了一台机器一样。
这里最大的不同是:不需要运行hadoop进程(DataNode、NameNode、ResourceManager、NodeManager等),既不需要执行start-dfs.sh/start-yarn.sh。同时,也没有修改$HADOOP_CONF_DIR/slaves文件,因此并没有加入集群。而只是作为集群的客户端使用。
因为我们上面是将整个$HADOOP_HOME拷贝到了dc1,其中包含了所有的配置文件,因此,也无需配置。
<5>验证安装
因为我在Hadoop集群上已经放有一些测试文件,
通过命令行界面,对文件进行一下获取和发送,可以验证客户端与集群工作良好。
1.从集群下载文件到客户端
#hdfs dfs -get /user/root/tmp/file1.txt ~/tmp
2.在客户端重命名后上传到集群
#mv ~/tmp/file1.txt ~/tmp/file1_2.txt
#hdfs dfs -put ~tmp/file1_2.txt /user/root/tmp
<6>
至此,一个简单的Hadoop集群客户端就搭建好了。
除了在客户端上执行HDFS的文件操作以外,还可以运行Hive,Hive本身就是一个客户端的工具。
同时,也可以运行Spark的Driver程序,它是Spark集群的客户端。
而Spark集群中的Worker通常是和HDFS的DataNode部署在同一台服务器上,以提升数据访问效率。


