

ML.NET是一个面向.NET开发者的开源、跨平台的机器学习框架,它能够将自定义的机器学习集成到.NET应用程序中。
我们很高兴地宣布ML.NET和Model Builder的新版本,它们带来了大量令人赞叹的更新。
在这篇文章中,我们将介绍以下内容:
ML.NET发布
此次发布的ML.NET为该框架带来了一个期待已久的功能。支持ARM!
ARM上的ML.NET
现在,您可以在 ARM64 和 Apple M1(除 Linux 和 macOS 外)设备上使用 ML.NET 进行培训和推理,这使得移动和嵌入式设备以及基于 ARM 的服务器获得平台支持。
下面的视频显示了在运行Manjaro ARM Linux发行版的Pinebook Pro笔记本电脑上的训练和推理。
<!--[if lt IE 9]>document.createElement('video')。 devblogs.microsoft.com/dotnet/wp-c…
在ARM上使用ML.NET进行训练和推理时,仍有一些限制:
- 符号SGD、TensorFlow、OLS、TimeSeries SSA、TimeSeries SrCNN和ONNX目前不支持用于训练或推理。
- 目前支持LightGBM用于推理,但不支持训练。
- 你可以通过为ARM编译来增加对LightGBM和ONNX的支持,但是它们并没有为ARM/ARM64提供预编译的二进制文件。
这些都会抛出一个DLL not found 异常。如果您受到这些限制的阻碍,或者希望在遇到这些限制时看到不同的行为,请在我们的GitHub repo中提出问题,让我们知道。
Blazor网络组件上的ML.NET
通过.NET 6,您现在也可以在Blazor Web Assembly(WASM)上进行一些训练和推理。它具有与ARM相同的限制,但增加了以下内容:
- 目前,您必须将
EnableMLUnsupportedPlatformTargetCheck标志设为false,才能在Blazor中安装。 - 不支持LDA和矩阵分解法。
请查看机器学习棒球预测repo(以及相关的社区Standup视频),其中有在Blazor Web Assembly中使用ML.NET的例子。
关于这个版本的ML.NET的更多细节,请参见发布说明。
模型生成器更新
作为预览版的一部分,我们最近宣布了Model Builder的几项重大变化,包括:
- 基于配置的训练与生成的代码后台文件
- 调整了高级数据选项的结构
- 重新设计的耗费步骤

这些功能和改进,你可以从我们之前的博文中了解更多,现在可以在公共频道上看到。更新您的模型生成器的版本以获得最新的功能。
项目模板
在Model Builder的Consume步骤中,有一个新的_项目模板_部分,允许你生成消耗你的模型的项目。这些项目是模型部署和消费的起点。
有了这个版本,你现在可以在你的解决方案中添加一个控制台应用程序或一个最小的Web API(如这篇博文中所述)。
我们计划在得到更多的反馈后,增加对更多项目/应用类型的支持,如Azure Functions(你可以在Model Builder GitHub repo中留言)。
新的和改进的AutoML
我们也开始与微软研究团队NNI(Neural Network Intelligence)和FLAML(Fast and Lightweight AutoML)合作,更新ML.NET的AutoML实现。
与这些团队的合作在短期和长期都很重要,对ML.NET的一些好处包括:
- 为所有的ML.NET方案启用AutoML支持
- 允许对超参数搜索空间进行更精确的控制
- 启用更多的训练环境,包括本地、Azure和企业内部的分布式训练
- 在先进的ML技术上开启未来的合作,如网络架构搜索(NAS)。
在第一次实施迭代中,也就是这次Model Builder发布的一部分,我们的团队致力于降低训练失败率,在给定的时间和CPU资源中增加探索的模型数量,并提高整体训练性能。
基准测试
团队进行了基准测试,以确保对AutoML的修改能够改善体验。请注意,这是对短运行时间的分析;对于大多数将被用于训练生产级模型的数据集,我们建议延长运行时间,以使AutoML收敛于最佳模型。
这些基准在一台标准的D32s_v4机器上运行,训练限制是1m1c、10m1c和30m1c(m代表分钟,c代表核心)。对每个试验的内存使用限制没有限制,允许的最大并行实验是30个。
虽然每个AutoML版本都评估了51个数据集,但评估指标(AUC、Log loss和R-Squared)只根据两个版本中共同成功的数据集来计算。
下面是到目前为止的基准测试的总结。
探索的模型数量
AutoML的新实现大大增加了1分钟训练时间、10分钟训练时间和30分钟训练时间所探索的模型数量:
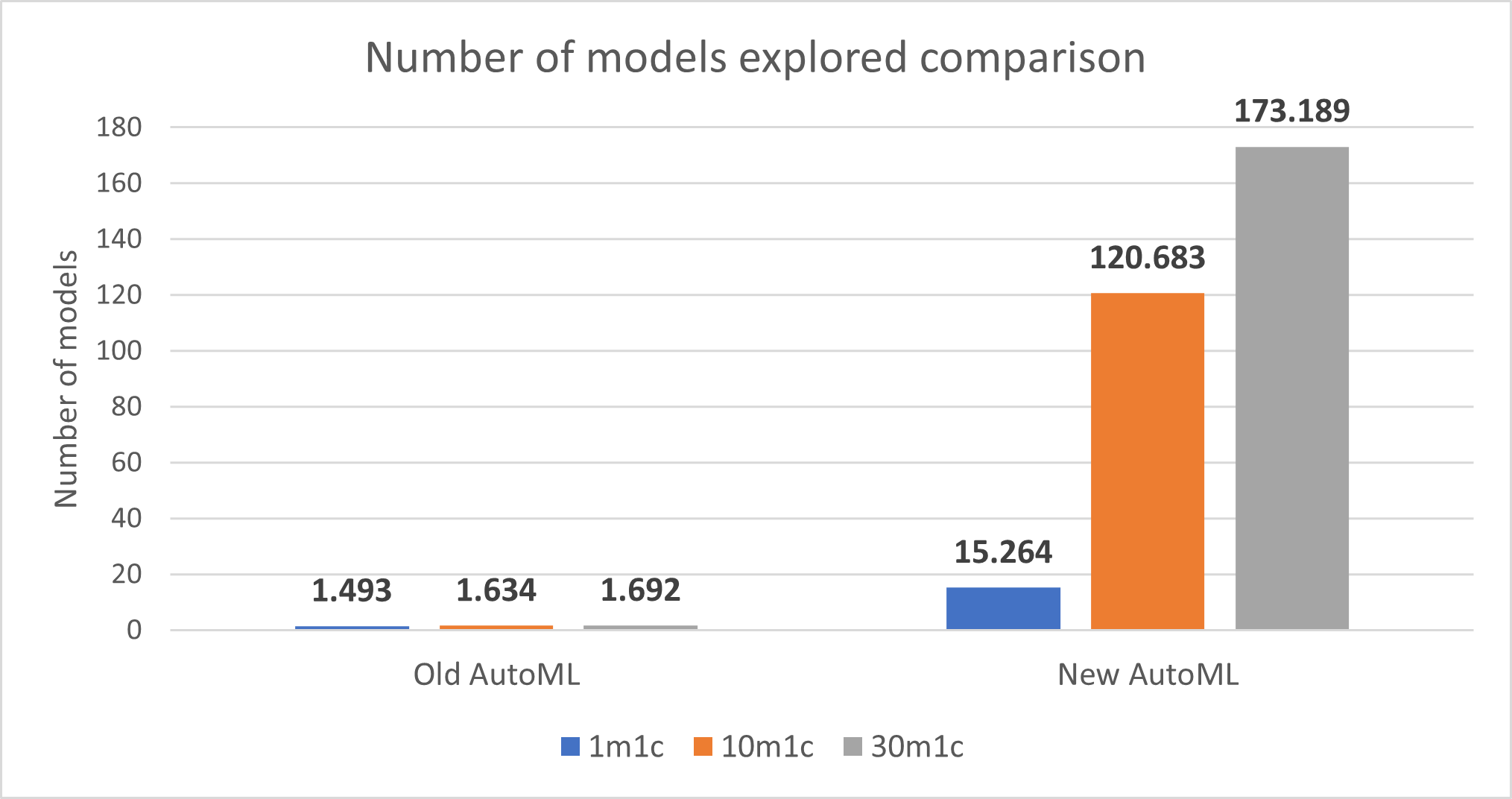
注:探索的模型越多越好。
平均超时错误率
AutoML的新实现改善了1分钟火车时间、10分钟火车时间和30分钟火车时间的超时错误率。
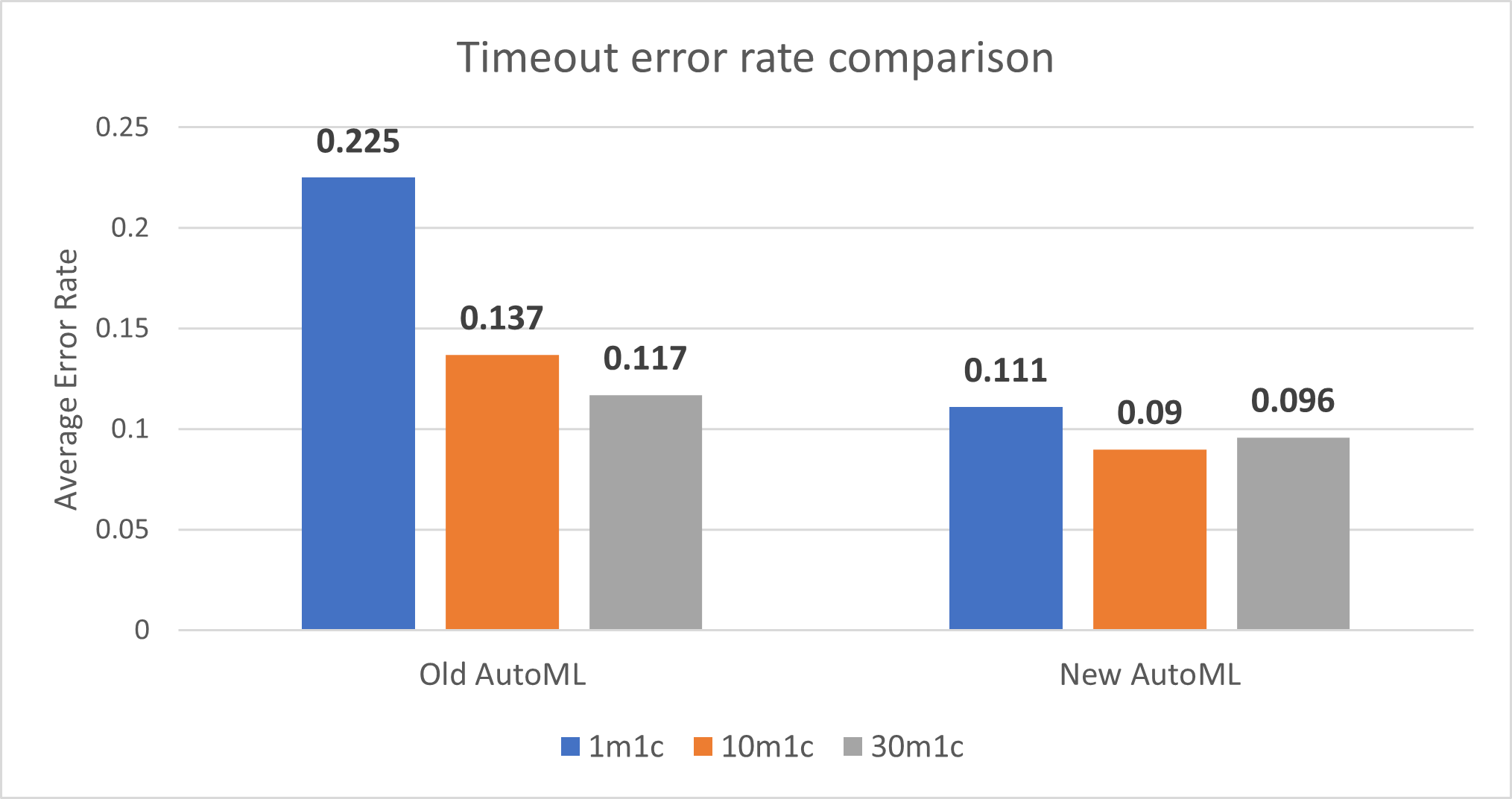
注:_错误_是指在给定的训练时间内,AutoML训练超时而没有探索到任何模型;_错误率_或失败率是指完成AutoML训练而没有发现任何模型的数据集的百分比。错误率越小越好。
该团队在AutoML训练过程中使用了几种方法来更快地找到第一个模型,包括。
- 从一个较小的模型开始
- 从更具成本效益的参数开始
- 次抽样(对于大数据集)。
二元分类模型的性能(曲线下面积,或AUC)。
AutoML的新实现降低了1分钟训练时间的AUC,但提高了10分钟训练时间和30分钟训练时间的AUC:
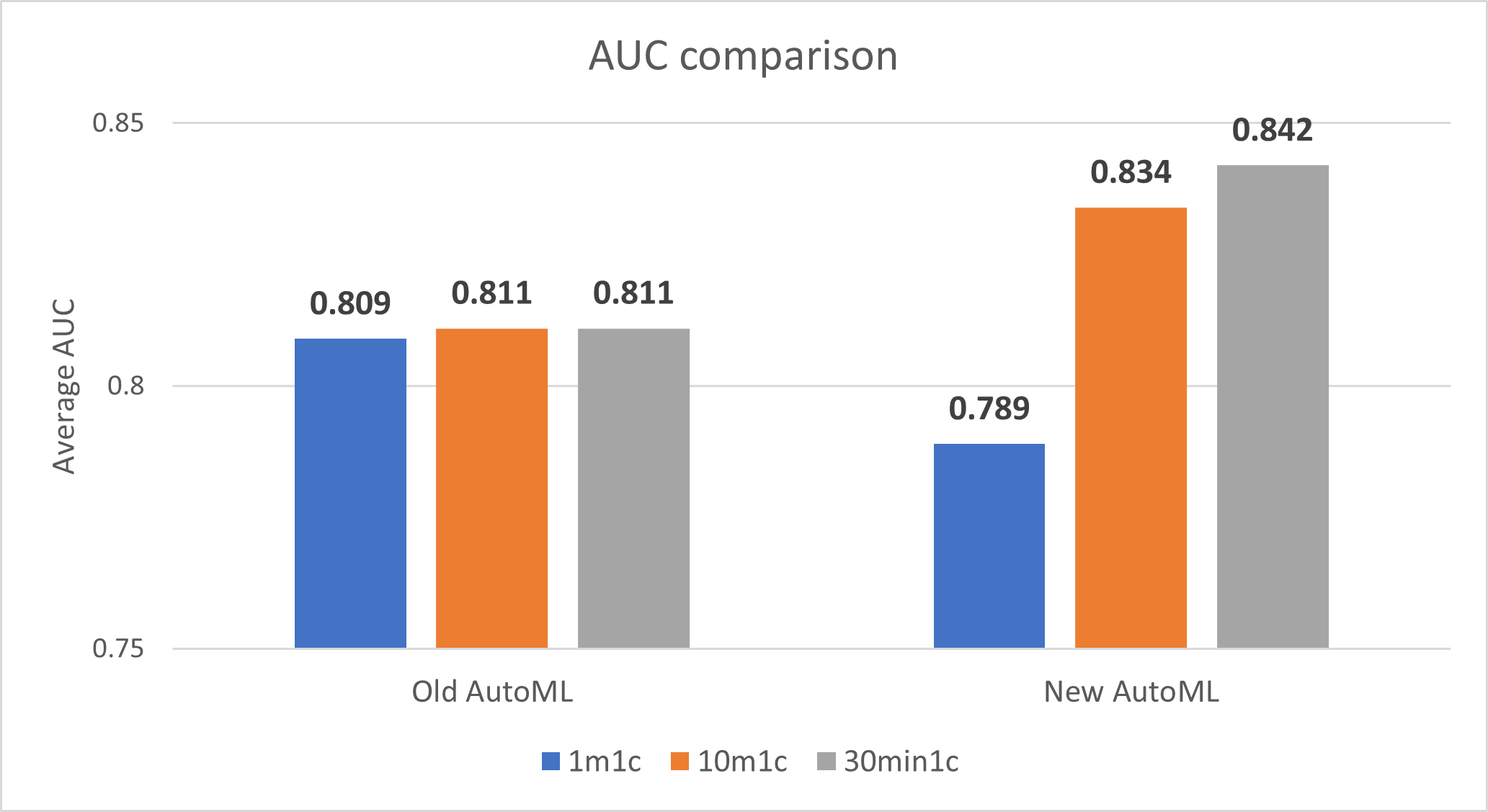
注:AUC越接近1越好。
多类分类模型性能(准确率
AutoML的新实现降低了1分钟训练时间的准确性,但提高了10分钟训练时间和30分钟训练时间的准确性。
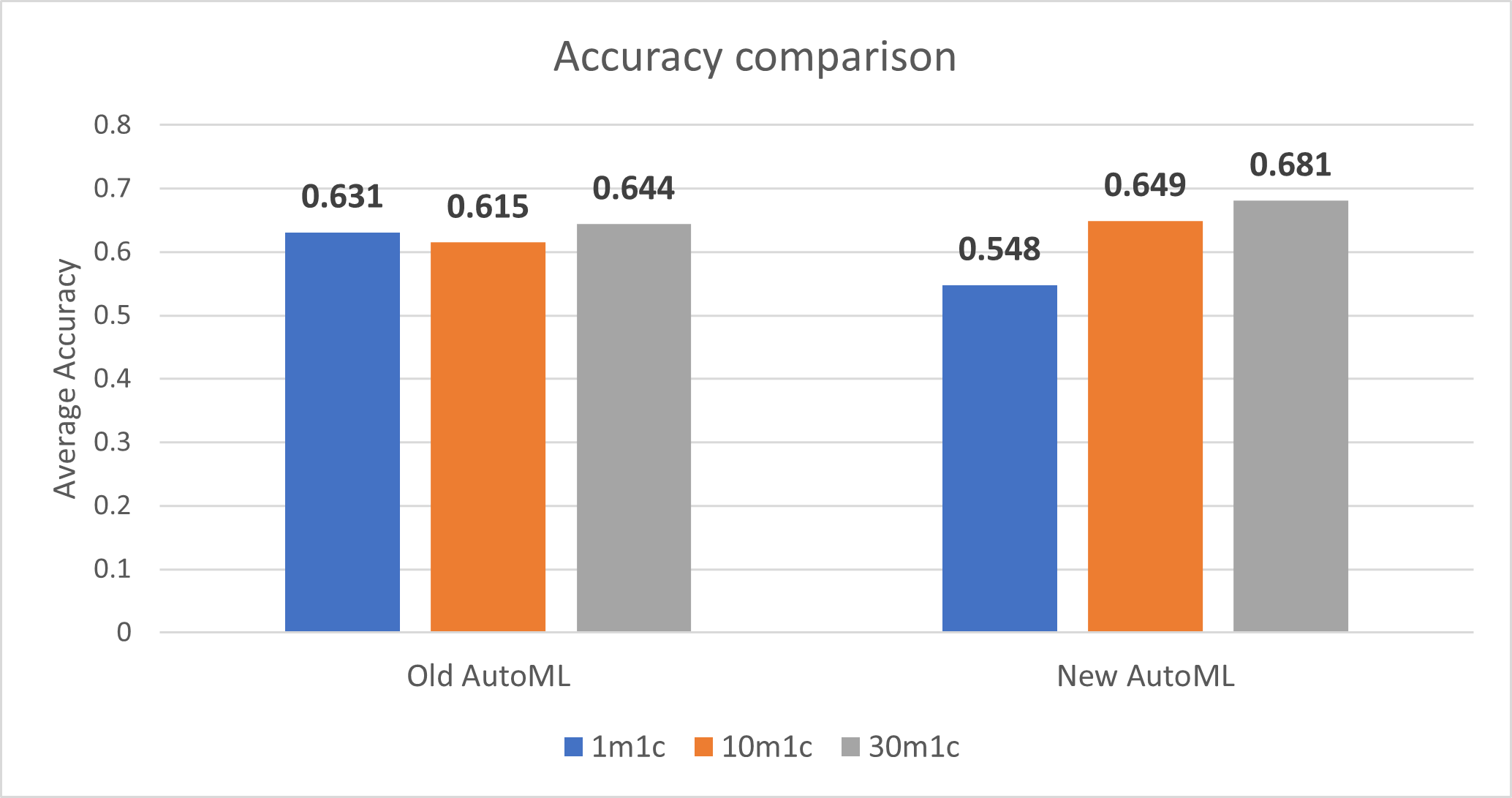
注:准确率越接近1越好。
回归模型性能(R-Squared)
AutoML的新实现提高了1分钟训练时间、10分钟训练时间和30分钟训练时间的R-Squared:
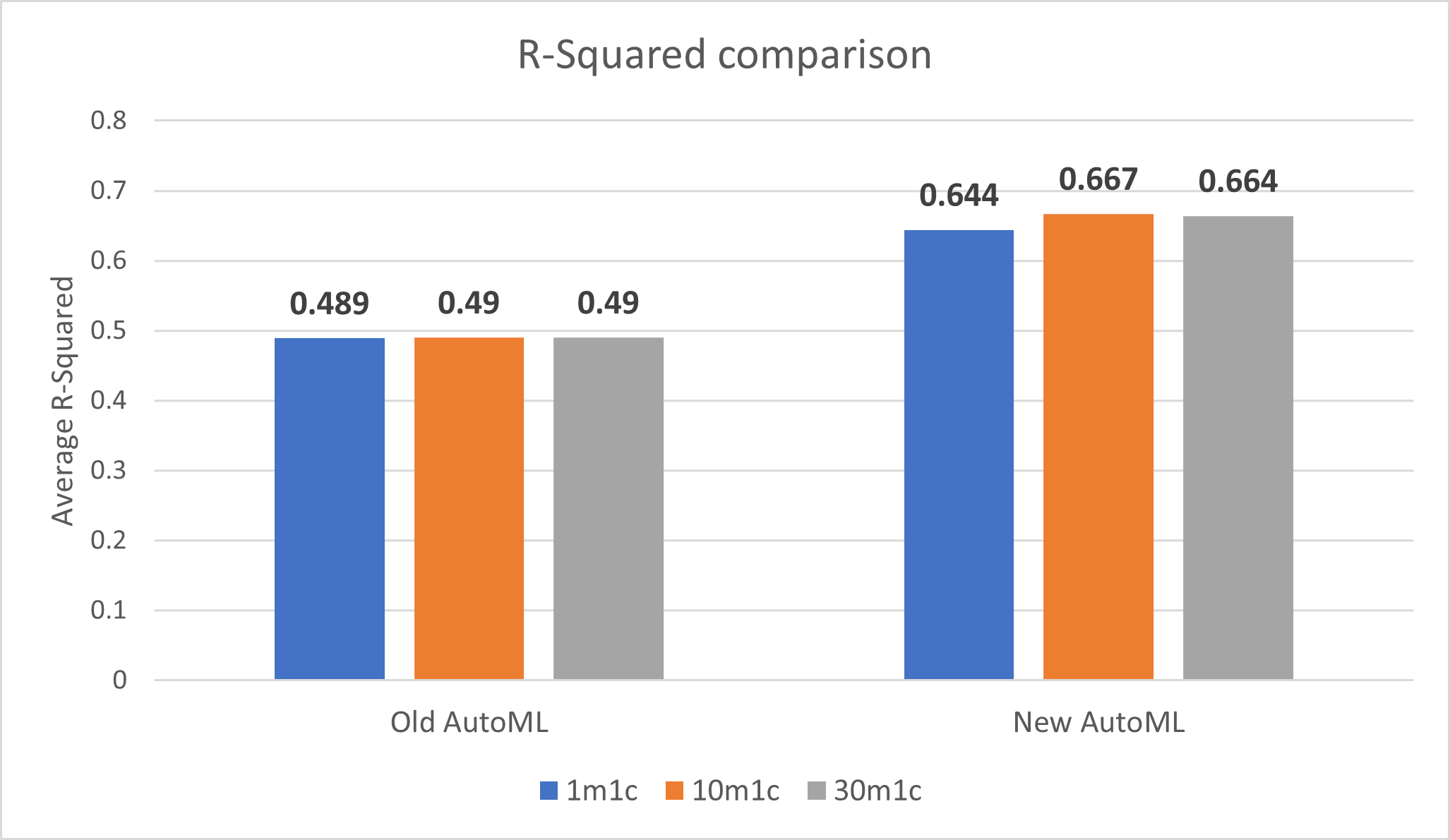
注:R-Squared越接近1越好。
错误修正
感谢每一位试用过预览版并留下反馈意见的人!根据这次预览的反馈和提交的错误,我们能够进行大量的修复和改进,其中一些包括:
- 取消训练不会丢弃当前结果(问题697
- GPU扩展失败(问题1268)
- 为GPU训练检测CUDA和cuDNN版本(第1152期)。
- 高级数据选项黑暗主题修复(问题1264)。
- 非故意的页面导航(问题1276)。
模型生成器的下一步是什么
我们正在为Model Builder开发很多很棒的功能和改进,下面是我们概述的其中一些。
更容易的协作和Git
这个版本的Model Builder只支持训练数据集的绝对路径。这意味着对Git功能的支持是有限的,在电脑或账户之间共享mbconfig文件将需要重新设置本地数据集位置。我们正在跟踪问题1456中的这个修正,它将为共享和检入/检出mbconfig文件增加更好的支持。
性能改进
团队正在努力改善用户界面的性能,特别是与大型数据集的交互。
进一步改进 AutoML
团队将继续对AutoML进行改进,包括改进当前的调谐算法,使其在更大的搜索空间上搜索得更快,进行更高级的训练(例如通过高级featurizers和更多的训练器),并为AutoML增加更多的场景,包括时间序列预测和异常检测。
继续训练
当你在Model Builder中开始训练时,你必须等待整个训练时间,以便得到一个模型。这意味着在训练过程中,如果你得到了,例如,一个准确率为95%的模型,你想使用它,但还有10分钟的训练时间,你必须等待剩下的10分钟,才能得到和使用这个模型。如果你在任何时候 "取消训练",你会失去所有的进展。
此外,如果你花了10分钟训练,却没有得到任何模型,或者只得到几个精度不高的模型,你必须用更多的训练时间重新开始训练,希望下一轮能给你更好的模型。
团队正在努力增加对能够 "继续 "训练的支持,这意味着能够在停止(或在此情况下暂停)训练后再次开始训练。有了这个功能,在你暂停训练后,训练进度不会被重置,相反,训练将从你停止训练的点恢复。然后,Model Builder可以使用训练历史来潜在地选择更好的算法超参数,并选择性能更好的管道,从而产生更好的模型。这也使得能够提前暂停训练并获得最佳模型的场景成为可能,而不必再次重新开始训练。
Azure ML数据集
目前,当你在Model Builder中使用Azure ML训练环境进行训练时,你的数据会被上传到与Azure ML工作区相关的Azure Blob存储。这意味着你只能选择本地数据进行训练。
ML.NET团队正在与Azure ML团队合作,增加对Azure ML数据集的支持,这样你就可以选择在Azure中已有的数据集上进行训练。另外,你也可以在模型生成器中从本地数据创建新的Azure ML数据集。
ML.NET调查的结果
在上一篇文章中,我们征求了大家对.NET中机器学习的反馈意见。
我们收到了约900份回复(谢谢!),并在机器学习.NET社区研讨会上介绍了一些结果。
这一轮调查的主要观点包括:
- 与过去两年的调查相比。
- 更多的受访者已经尝试或正在使用ML.NET
- 更多来自大公司的受访者正在使用ML.NET(相对于小公司)。
- 更多的受访者已经在生产中使用ML(相对于学习阶段)。
- ML.NET用户正变得越来越高级,并希望获得高级功能(如模型的可解释性、数据准备、深度学习
- 受访者中最大的障碍/痛点/挑战都是。
- 小型ML.NET社区
- 文档和样本(数量、质量、真实世界)。
- 对深度学习的支持不充分
- ML.NET不支持特定的ML场景或算法
- 担心微软会放弃它
下表列出了调查中最重要的痛点,以及我们计划如何解决每个痛点:
小型ML.NET社区
- 继续社区工作(例如,虚拟ML.NET社区会议、机器学习.NET社区研讨会、ML.NET Discord频道)。
- 分享更多的ML.NET使用案例/案例研究的故事
- 在Stack Overflow、GitHub等网站上保持活跃,并鼓励社区贡献。
深度学习支持不足
- 支持Torch(在ML.NET中消耗PyTorch模型
- 增加类似Keras的功能,从头开始构建神经网络
- 根据需要添加场景(例如,NLP和物体检测的本地和Azure培训)。
文档和样本的缺失/质量问题
- 更新文档计划,增加专用资源
- 保持文档和样本库的更新
- 增加更多的实际使用案例和更复杂的E2E样本和教程
ML.NET不支持的特定ML场景或算法
- 增加NLP和本地物体检测训练
- 继续与用户合作并分析市场,以了解哪些场景和算法需要在ML.NET中得到支持
担心微软会放弃它
- 进入.NET的发布时间表
- 积极开展API+工具的工作/开发功能/跟上ML的发展趋势
- 公共战略和路线图
- 在大型.NET会议的主题演讲中宣布和演示ML.NET的内容
如果你有反馈,想法,或其他你想从ML.NET团队看到的东西,请让我们知道!
开始和资源
在Microsoft Docs中了解更多关于ML.NET和Model Builder的信息。
如果你遇到任何问题、功能请求或反馈,请在GitHub上的 ML.NET APIs repo或ML.NET Tooling(Model Builder & ML.NET CLI)repo中提交问题。
