0/前言
参考网址:
https://zhuanlan.zhihu.com/p/60059869,
https://blog.csdn.net/yanjiangdi/article/details/100939969
统计学中的三大相关性系数:pearson, spearman, kendall(肯达尔),
他们反应的都是两个变量之间变化趋势的方向以及程度,
其值范围为[-1,+1]
0表示两个变量完全不相关,正值表示正相关,负值表示负相关,值越大表示相关性越强。
1/什么是相关性
相关性分析就是对总体中确实具有联系的标志进行分析,其主体是对总体中具有因果关系标志的分析。
它是描述客观事物相互间关系的密切程度,并用适当的统计指标表示出来的过程。
在一段时期内,出生率随经济水平上升而上升,这说明这2个变量之间是正相关关系;
而在另一段时期内,随着经济水平进一步发展,出现出生率下降的现象,两变量之间是负相关关系。
简单来说:
相关性就是看2个变量之间是否具有某种关系
如果一个变量变大,另一个也跟着变大,这就是正相关,
如果一个变量变大,另一个变量变小,则这是负相关。
如果2个变量之间没有关系,则说明这2个变量之间是没有相关性的,也就是说2个变量是独立的。
2/相关系数r
衡量2个变量之间的相关性大小的指标是相关系数r。
相关系数r的取值范围是[-1,+1],可以是此范围内的任何值。
r值在0和1之间,这是正相关,散点图是斜向上的,这时一个变量变大,另一个变量也变大;
r值在-1和0之间,这是负相关,散点图是斜向下的,此时一个变量减小,另一个变量将减少。
r的绝对值越接近1,两变量的相关性越强(正相关性越强,负相关性越强),
r的绝对值越接近0,两变量的相关性越弱。
相关系数r大于0.4小于0.7叫弱相关,大于0.7叫强相关,
相关系数不管多大,只要Pvalue>0.05都无意义,pvalue>0.05说明得到的结果可能是偶然的
r<0.2 不相关
0.2<r<0.4 关系一般
0.4<r<0.7 关系密切
r>0.7 关系非常密切
p_value,即p值,也就是Sig值。
如果P值<0.01即说明某件事情的发生至少有99%的把握,
如果P值<0.05,则说明某件事情的发生至少有95%的把握。
当P<0.05,则说明水平显著,这样得到的相关性才有意义
相关系数r回答的问题是相关程度强弱,显著性回答的问题是他们之间是否有关系,说明得到的结果是不是偶然因素导致的,是否具有统计学意义。
假如说我得到p<0.05 相关系数r=0.279,意味着二者之间确实存在一定的正相关性,但相关性并不高。
但如果相关系数r=0.85,但是pvalue > 0.05,则意味着二者之间相关性很强,而这个高相关的结果可能是偶然因素导致的,不具有统计学意义。
3/如何计算相关性
只有数值类的变量,才可以计算相关性。
类别变量,不能计算相关性。
<1>dataframe.corr()
.corr()方法是pandas的dataframe数据对象独有的方法
该方法可以计算dataframe数据对象中任意2个变量(列)之间的相关系数,
但是只能计算相关系数r,不能计算pvalue,也就是说即使计算出来了r值,也没有参考意义。
而且只能对数值类型的列计算相关系数r,不是数值类型的列会被自动过滤掉。
DataFrame.corr(method="pearson",min_periods=500)
参数说明:
method:可选值为{‘pearson’,‘spearman’,‘kendall’}
1)pearson:又称积矩相关系数,Pearson相关系数来衡量两个数据集合是否在一条线上面,
即适用于线性数据的相关系数计算,对非线性数据会有误差。
2)spearman:又称秩相关系数,非线性的,非正态分析的数据的相关系数
3)kendall:也是秩相关系数,用于反映分类变量相关性的指标,即针对无序序列的相关系数,非正态分布的数据。
min_periods:样本最少的数据量
返回值:各类型之间的相关系数构成的DataFrame表格,不能给出pvalue值
<2>pearson 又称积矩相关系数
1)适用条件,只有满足以下条件,用pearson计算相关系数才有意义。
<1>两个变量都服从正态分布(不一定是标准正态分布),也可以是接近正态的单峰分布
<2>两个变量的标准差都不为零时,因为pearson相关系数是协方差与标准差的比值,所以分母不能是0
<3>两个变量之间是线性关系
<4>两个变量都是连续变量(不是离散变量)
<4>两个变量的观测值是成对的,每对观测值之间相互独立,样本量最好是在500以上
2)为什么pearson需要数据是呈正态分布的??
求pearson相关系数以后,通常还会用t检验之类的方法来进行pearson相关性系数的检验,
而t检验是基于数据呈正态分布的假设的,所以用pearson做相关性分析的时候,数据必须是满足或者近似正态分布的。
3)语法:
from scipy import stats
stats.pearsonr(x,y)
4)python3.6应用
Dataframe.corr(method='pearson'), 返回相关关系矩阵,但不能给出pvalue值。
from scipy.stats import normaltest, probplot
normaltest(a)返回统计数和检验P值, 样本要求>20。
probplot(np.array(x,y), dist="norm", plot=pylab) 化PP图,若在对角线,则相关性强。
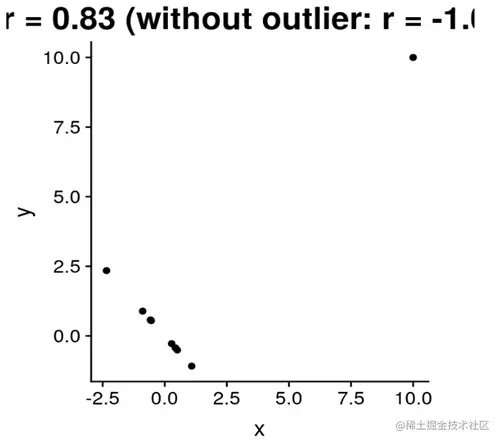
5)pearson相关系数对异常值非常敏感,甚至会改表r的符号。
如下图所示
如果没有右上角的异常值,那么x和y之间是负相关。
但是如果考虑右上角的异常值,则x和y之间变成了正相关。
<3>spearman rank 秩相关系数(也是等级相关系数)
1)spearman是无参数的等级相关系数,即r与两个变量的具体值无关,
而仅仅与其值之间的大小关系有关。di表示两个变量分别排序后成对的变量位置差,N表示N个样本,减少异常值的影响。
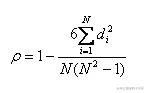
2)spearman对数据条件的要求没pearson相关系数严格,
只要两个变量的观测值是成对的等级评定资料,
或者是由连续变量观测资料转化得到的等级资料,
不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。
3)语法
from scipy import stats
stats.spearmanr(x,y)
4)python3.6应用 :
a) Dataframe.corr(method='spearman'), 返回相关关系矩阵,但是
b) from scipy.stats import spearmanr
spearmanr(array)返回 Spearman 系数(系数矩阵)和检验P值, 样本要求>20。
<4> Kendall rank 秩相关系数(也是等级相关系数)
肯德尔相关性系数,又称肯德尔秩相关系数,它也是一种秩相关系数,不过它所计算的对象是分类变量。
分类变量可以理解成有类别的变量,可以分为:
无序的,比如性别(男、女)、血型(A、B、O、AB);
有序的,比如肥胖等级(重度肥胖,中度肥胖,轻度肥胖,正常,偏瘦),绩效(s,a,b,c,d)
通常需要求相关性系数的都是有序(有大小关系的)分类变量。
python3.6应用 :
a) Dataframe.corr(method='kendall'), 返回相关关系矩阵
b) from scipy.stats import kendalltau
kendalltau(x,y) 返回相关系数r和pvalue值
<5>什么情况下采用pearson,什么情况下用spearman
1)两个连续变量间呈线性相关时(线绘制散点图,看是否是线性相关),使用pearson积矩相关系数,
不满足积矩相关分析的适用条件时,使用Spearman秩相关系数来描述.
2)利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围更广。
对于服从Pearson相关系数的数据亦可计算Spearman相关系数,但统计效能要低一些。
spearman相关系数的计算公式可以完全套用pearson相关系数计算公式,但公式中的x和y用相应的秩次代替即可。
3)二者共同的地方是:2个变量必须都是连续变量,不能是离散变量


