文/阿里云 - 秦奇
熟悉大数据的同学应该对 数据资产 和 数据资产管理 这两个名词不会陌生,但是加上 “智能化领域” 是不是就有点懵了? 数据资产 跟 智能化有关系吗?不要急,让我们先看下这两个关键词。
数据资产和数据资产管理
- 数据资产 (Data Assets)是拥有数据权属(勘探权、使用权、所有权)、有价值、可计量、可读取的网络空间中的数据集。 -- 维基百科
- 那么数据资产管理呢?数据资产管理(Data asset management 简称DAM)是规划、控制和提供数据及信息资产的一组业务职能,包括开发、执行和监督有关数据的计划、政策、方案、项目、流程、方法和程序,从而控制、保护、交付和提高数据资产的价值。 -- 数据资产管理实践白皮书
两个词的定义有点官方,简单理解一下, 数据资产 主体是数据,强调数据是“自己”的数据,并且有价值,可衡量;而数据资产管理呢,就是利用一些方法 尽可能让数据价值最大化。总结就是两个关键词: 数据、价值。
智能化领域的探索
说了这么多,跟 智能化领域有啥关系呢?还是别急,我们先想想当前的智能化存在哪些问题呢?在我看来,有个两个问题亟待解决:
- 上手难度大,缺乏基础的数据基建和资料,这样每个开发者都得依据机器学习解决问题的一般步骤进行,历经问题定义、准备数据、特征工程、选择模型、训练调优以及模型评估各个步骤。那么有没有可能让用户快速上手,聚焦在核心问题的解决上,不考虑数据、不考虑评估,仅仅关心模型的选择和调优呢?
- 数据的可复用性差。差不多每个任务,第一步都是数据的收集和处理,而一般机器学习所需的数据体量都很大,最小也是万级别,并且需要进行预处理,针对不同的问题具备不同的处理方式。那么在指定问题模型训练结束之后呢?除非后续还有相同的问题,否则这部分数据就是一次性的,用完就相当于废弃了。想想我们花了大力气收集和处理之后的数据,迎来这样的结局,想想是不是挺憋屈的?
那么为了解决上述的两个关键问题,因为刚好在负责数据资产相关的业务,因此我们想尝试下,采用 数据资产管理的方法能否解决这两个问题。一句话,我们想通过将 智能化相关的数据 通过使用 数据资产管理的系统化、标准化的方式进行管理,以达到 数据有标准、数据可信赖 和 数据可共享的目的。具体的思路有以下几个:
数据管理
一句话,将智能化领域用到的数据管理起来,比如 常见的任务、通用数据集、常见的模型、评估指标等等。这样开发者可以看到 感兴趣的任务,以及现有模型的一些实践,并且这些任务已经包含了 对应的数据集。开发者需要考虑的仅仅是 模型的选择 和 调优,这样节省了大量时间,并且大大降低了 开发者的上手难度。类似于Kaggle的形式,我们会聚焦在常见的一些任务,比如 代码智能相关的任务,并基于这些任务来构建我们的通用数据集和模型算法。
这里不得不提一下数据管理的部分了,我们会建立一套代码智能相关的数据仓库,而原始数据会经过ETL转化为 各个任务所需的数据集,同时基于此,我们可以观察到 数据的血缘分布 和 影响分析,这样后续步骤出现问题,我们可以进行快速的分析和定位。
数据共享
发掘数据间的关联关系,方便用户进行数据共享。这里的共享包含两部分,一部分是 数据集共享,另一部分是模型共享。
对于数据共享,我们想建立基于 指定任务的通用数据集。 比如对于 代码智能领域,同样一份带注释的原始代码,经过标准化的处理之后,可被应用于不同的代码任务。最常见的 代码生成( Code Completion)可以用它进行预测后续的代码生成;结合代码的注释之后,又可以被用来训练 代码搜索(Code Search)、 文本转代码(Text-to-Code Translation) 和 代码转文本(Code-to-Text Translation)。对于数据使用方来说,可能一句 select * from code where comment is not null就能得到处理之后的文本转代码任务的训练数据了,完全不需要额外收集数据、处理数据等。而对于数据提供方的我们来说,唯一考虑的就是 数据样本是否足够丰富,是否在时效以内,数据是否安全等。
而对于模型共享,由于一般深度模型的不可解释性,我们至少可以建立统一、标准的模型输入输出接口,这样不同的模型可以进行很简单的插拔,以对比和衡量不同模型的效果,
数据质量

数据质量主要考虑以下数据指标:
- 完整性:数据是否缺失;
- 规范性:数据是否按照要求的规则存储;
- 一致性:数据的值是否存在信息含义上的冲突;
- 准确性:数据是否错误;
- 唯一性:数据是否是重复的;
- 时效性:数据是否按照时间的要求进行上传。
每项深度学习任务都离不开 数据获取和处理这一步,并且需要花费大量时间,因为这一步的质量和最后训练的效果强相关。所以在我们的数据基建中,数据质量是我们尤其重点建设的部分。在数据获取以及数据共享的过程中我们会设立严格的数据校验规则 来保证我们数据的准确性。比如还是上面的原始代码,在经过最初的处理,比如去空行、加入头尾识别字符等之后,在存储的过程中,会基本校验 各字段值是否为空,枚举值是否符合要求等。再到 具体的代码任务,比如 文本转代码中,首先文本和代码不能为空,严格一些,比如校验 文本的长度等等。当然不同的任务有不同的数据规范和要求,我们要做的是 抽象常见任务的数据要求,尽可能覆盖所有常见任务的 数据处理,并支持一些特定要求的处理,保证数据的有效性。
写在最后
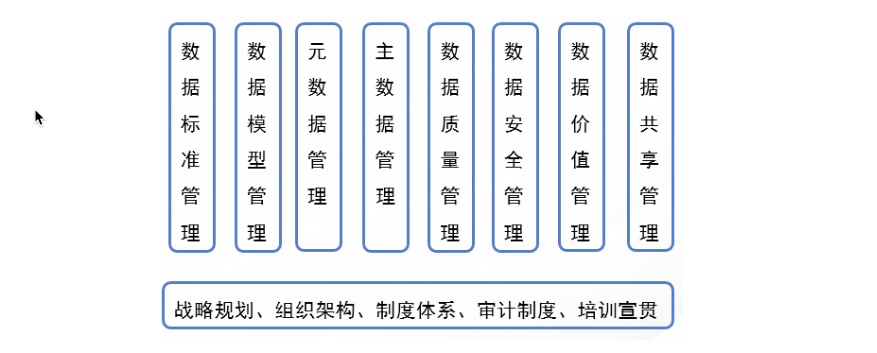
数据资产管理是一系列方案和标准的结合,而上述几条仅仅是我们选取了其中和 智能化领域表面最相关的部分。而其他还包括 数据标准、领域建模等。其中数据标准主要 解决数据的一致性 和 准确性的问题;数据模型是现实世界数据特征的抽象,用于描述一组数据的概念和定义。这些概念和方法都可以对我们智能化的过程形成参考,具备还需后续的研究和实践。
本文尝试将数据资产等标准化的流程方法应用在 智能化领域,希望两个领域能够产生跨界的碰撞,核心目标还是 提升数据效能和价值,希望能够对机器学习开发者能够提供一定的帮助。
参考资料