

又是一篇最佳实践和准则的文章

几天前,我在工作中安排了一次与队友的会议,在会上我介绍了一些关于良好开发实践的准则。这一切都是因为我在一个特性分支上做的Angular 12迁移。
把事情放在背景上,我目前工作的公司有几个项目安排在NX Monorepo中。当新的Angular版本发布时,我们会在git仓库上开一个特性分支,在那里我们会对应用程序进行所有的调整和改变,使其能够与新的Angular版本一起工作。
Angular 12与Angular 11没有 "那么大的区别",所以迁移几乎是无痛的。但是......代码验证更严格一些,所以出现了一些问题,我在很多地方发现了一些缺陷,这就是我打算写的东西,希望看到这篇文章的人不要犯同样的错误。
重要说明
正如我已经提到的,参与迁移的项目是在一个NX风味的monorepo上结构的,这意味着几个应用程序生活在一个单一的仓库里。这些应用既有前端也有后端,所以有些问题是在Angular前端项目上发现的,但也有在Typescript后端项目上发现的。
变量类型
当使用Typescript进行任何函数编程时,如果我们使用的变量没有类型,我们的代码就容易出现错误。Typescript在运行时不做任何类型验证,所以如果有错误,它就会抛出一个错误,如果你不注意处理错误,可能会有大的爆炸和火灾。
例如。
export interface User { name: string; age: number; birthDate: Date; isActive: boolean;}
而这种执行是 "正确的",只是因为我们没有检查变量类型。如果我们只是做一些调整,同样的代码会显示一些错误(在编码的时候)。
export function editUser(originalUser: User, newUserInfo: User) { let updatedUser = Object.assign({}, originalUser, newUserInfo); return updatedUser;}const oUser: User = { name: 'Jose Santa Cruz', age: 44, birthDate: new Date('April 5, 1977'), isActive: true};const uUser = editUser(oUser, { fullName: 'Jose I Santa Cruz', birthDate: new Date('April 5, 1977'), isActive: 'false'});
这段代码立即显示了这个错误(在VS代码上)。

类型字符串不能被分配到布尔类型。而这是有道理的。'false' !== false
纠正这个问题会显示另一个错误。
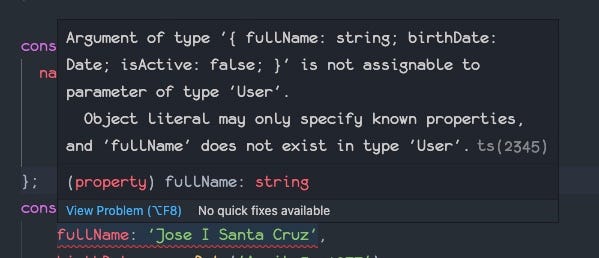
这也是正确的,因为在开始时定义的用户界面没有fullName属性。只要将fullName属性改为name即可。你还必须添加age属性,因为它是必须的。如果你希望它是可选的,只需在界面上编辑一下,这样就可以了。age?: number;
正如我所说的,这在编程时是很有帮助的,你不会因为漏打变量而犯编程错误,但没有人说这种错误不会在运行时发生。所有这些错误都会在编译阶段出现。
但是,具有泛型的类型也需要有足够的希望,以避免一些类似的错误,我将在下一节中尝试解释。
诺言
承诺是一个不同的故事。为了总结一下什么是承诺,我们假设你问我明天的气候。我会回答:"_好的,我会告诉你明天的气候...... "_答案不一定会马上出现,你仍然可以去给自己泡杯咖啡,多码一会儿,在某个时间段我会说:"明天将是一个晴天"。
你通常需要能够注意这个答案,否则它就会丢失,你永远无法知道我什么时候回答了,或者我什么时候重启了自己,忘记了回答,或者出现了错误。
在代码中。
function randomError() { return ( Math.random() * 1000 ) >= 499;}
我知道,我在这里跳过了很多思考(而且为我感到羞耻,_零_文档)。但我会尽力补偿你的。
- askForClimate。我们的主要功能。你问气候,我告诉你我会回答(有时间)。由于我们没有使用API来真正获得气候,我将模拟随机错误和随机延迟。
- randomError。基于一个随机数,生成一个 "随机 "错误或无错误状态。是的!可以有一个更好的随机函数,但我要保持它的简单。
- dummyDelay:延迟回调函数的执行时间为超时毫秒。这是一个假的延迟,只是为了模拟网络滞后,就像气候是通过API调用获得的。
所以,你问气候_(askForClimate_),我说我会回答(console.log at_askForClimate_),时间过去了_(dummyDelay_),发生了一些事情_(randomError_),最后你可能会或可能不会收到气候的答案。
上面的代码可以工作,但显然我们可以做得更好。事实上,如果把这段代码放在例如Angular 12服务下,你会得到更多的错误,这是因为Angular 12的编译比平时更严格。因此,让我们对我们的代码进行更严格的蜂类型。
function randomError(): boolean { return ( Math.random() * 1000 ) >= 499;}function dummyDelay(callback: (args?: unknown) => void, timeout?: number): void {
我把这个问题弄到了一个极端的程度。有很多情况下,变量类型是从父函数中正确推断出来的。
类型严格的好处是,你的同伴在使用你编码的函数时不会犯类型错误。
* Argument of type '(data: number) => void' is not assignable to parameter of type '(value: string) => void | PromiseLike<void>'. Types of parameters 'data' and 'value' are incompatible. Type 'string' is not assignable to type 'number'.ts(2345) *
作为一个好的做法,至少要尝试为所有的变量添加类型,这包括通用类型的变量(例如:Promise< T>)_。_在最坏的情况下,使用any 类型(它不是很好,但也不是那么坏)。如果将来你有可能知道变量的类型,你可以使用管道连接的类型,例如:
const pinCode: string | number; // pinCode can be a string or a number
,或者如果你不知道变量的类型,不想使用任何类型,使用未知类型。如果你这样做,请确保对变量进行相应的转换,例如。
const pinCode: unknown;const deltaN: number = 123;const validation: number = (parseInt(pinCode as number, 10)) + deltaN;
返回诺言的诺言
这个问题没有出现在Angular 12的前端代码上,而是在后端。我们使用的是NX monorepo,所以大部分的编码验证和限制都会影响前台和后台的代码。
在我们的后端,我们使用Sequelize,而Sequelize的大部分函数已经返回了Promises。问题是,我在后端代码中发现了几个具有这种结构的函数。
// seqUser is a Sequelize model classexport function retrieveUsers() { return new Promise((resolve, reject) => { seqUser.findAll().then( users => resolve(users), error => { console.error('ERROR retrieving user list: ', error); reject(); } ); });}
看到这里的问题了吗?seqUser.findAll ,已经返回了一个Promise<Array<seqUser>> ,所以实际上没有必要将一个Promise包裹在另一个Promise里面。
但请注意,我说的是_"没有真正的需要"_。那么,_是否有真正的需要呢?_很高兴你这么问。这一点很值得商榷,我认为唯一有理由将一个_Promise_包裹在一个_Promise_里面的情况是,对检索到的数据需要进行一些额外的处理。所以你可以检索数据并修改一些值。
为什么要在这里做,而不是在真正使用Promise的函数中做?这就是所谓的 "关注点分离"(Separation of Concerns,SoC),我稍后会说到这个。
库导入
正如我所说的,公司的项目都是在Nx monorepo上进行的。这个 repo 有几个前端、后端和库项目,其中许多项目之间共享组件、类和服务。在定义一个可扩展的monorepo结构方面有一个明确的意图,所以组件的替换可以在不影响底层代码的情况下进行,但有时IDE(在这种情况下是VS Code)并不能帮助避免在导入库组件时的一些特殊错误。
举个例子;让我们假设你有几个项目被安排成Nx monorepo。你目前正在做一个库项目,它需要另一个库项目的一些功能。
- lib/front-ui: 一个Angular库,包含多个组件、服务、指令和管道,可能在多个项目中使用(这就是为什么它是一个库,以避免代码重复)。
- lib/shared-utils: 一个不依赖任何其他库的纯函数的实用库。这样,我们可以在前端和后端项目中使用这个库。
库是用Nx CLI创建的,有以下命令。
$ ng g @nrwl/angular:library FrontUi --buildable$ ng g @nrwl/node:library SharedUtils --buildable
一旦执行,angular.json 文件将有2个新的块,旨在建立这些库,而tsconfig.base.json 文件将有新的路径定义。_buildable_参数是为了防止你想单独构建你的库,并利用Nx云编译缓存的优势。
注意事项:Nx cli值得为自己写一篇完整的文章。
首先要做的是调整tsconfig的路径,从。
"@mine/shared-utils": ["libs/shared-utils/src/index.ts"],"@mine/front-ui": ["libs/front-ui/src/index.ts"]
到
"@mine/shared-utils": ["libs/shared-utils/src/index.ts"],"@mine/shared-utils/*": ["libs/shared-utils/src/lib/*"],"@mine/front-ui": ["libs/front-ui/src/index.ts"],"@mine/front-ui/*": ["libs/front-ui/src/lib/*"]
这样你就有希望直接导入所有正确导出的库组件(比如Angular Material)。
顺便说一下,在我的nx.json ,我有"npmScope": "mine" 。
让我们假设你在做一个新的前台服务,叫做NewDataService 。$ ng g service services/NewData --project front-ui
而在你的代码中,你需要从utils库中导入实用函数printableJson 。大多数时候(也许不是大多数,但很多时候),如果你让_IDE_做脏活累活,找出你的导入位置,你会_(可能/最可能)_以这样的方式结束。
import { printableJson } from ' libs/shared-utils/src/lib/services/new-data.service';
或更糟糕
import { printableJson } from ' ../../../../../shraed-utils/src/lib/services/new-data.service';
还记得你的 tsconfig.base 文件吗?让我们来使用它。
import { printableJson } from ' @mine/shared-utils';
甚至更好(如果一切都被正确导出)。
import { printableJson } from ' @mine/shared-utils/printableJson';
这样可读性就强多了。
内部导入
假设你正在处理同一个服务_(front-ui 的 NewDataService_),但需要在同一个库中添加对另一个服务的调用,例如:RetrieveMetadataService (已经在front-ui中定义)。你正在小心翼翼地以_"好的方式 "_导入东西,而你最终得到的是一个令人震惊的例子。import RetrieveMetadataService from '@mine/front-ui';
记住你还在_front-ui_ 里面。这在开发环境中可能是可行的,但在为生产构建时,你会得到一个循环依赖的错误。为什么?你不能在自身内部导入同一个库。不漂亮,不好=>会导致生产编译失败。
如何避免 "坏 "的导入
只要确保你没有在自身内部调用同一个库,并确保你的导入中没有任何_src_文件夹的引用。如果你在你的导入中发现了_src/_的文字,你就做错了。
非树状结构的导入
我在代码中发现的另一种讨厌的导入是诸如
从'@mine/my-library'导入*作为myLibrary。
这类导入对你的应用程序是相当有害的,因为它们将整个库作为别名导入,而不仅仅是你在代码中可能使用的几个函数。这些导入不是树状的,而且对最终的应用程序包的大小有很大的影响。
一个大的包的大小会变成一个糟糕的用户体验,因为应用程序的大小会增长得太大,而下载大文件总是不好的(从Web应用程序的角度来看)。
如何解决这个问题?
这个问题很简单,在你的代码中找到所有的* as ,并尽力去解决它们。
学习使用cli
正如你之前看到的,我使用了几个例子,在这些例子中我放置了命令的执行。
- 用于在monorepo中创建Nx库
- 在_front-ui_库中创建一个服务
这是因为我几乎记不住一个服务的内部语法,或者绝对不知道如何安排一个库的文件夹结构和编辑正确的文件。好消息是,有人已经在这个任务中挣扎过,并且做了一个非常完整的命令行工具,所以我们可以忘记这一切,坚持开发的重要部分,那就是解决代码中的一个需求。
Angular CLI是一个命令行工具,它允许我们为一个Angular应用程序生成所有需要的代码结构。之后,你必须对所有的业务逻辑进行编码,但你几乎可以忘记从你知道的组件中复制和粘贴的做法。相信我,复制和粘贴代码可以工作几次,但你会忘记编辑或调整一些东西,一切都会惨遭失败。
Angular CLI和Nx CLI的每一个代码生成器都使用一种叫做原理图的东西。示意图是一段代码,它使用一个JSON定义作为参数,一些Typescript文件作为内部逻辑,还有一些模板用来生成代码。你并不需要知道你所安装的每个CLI上的所有示意图选项,只需要学习足够的知识,以避免复制和粘贴这么多。比如说。
-
创建一个组件。
ng g component components/NewComponent -
创建一个路由组件(AKA页面):
ng g component pages/NewPage
,然后ng g module pages/NewPage --routing -
创建一个服务。
ng g service services/NewService
以此类推,指令、管道、守卫......。
如果你只是想看看运行生成器后会生成哪些文件,请在最后添加_--干运行_参数。如果你的服务、组件或页面不是要 "生活"在一个单独的文件夹中,使用--flat true或_--flat false_参数。
相信我,你不会后悔学习使用CLI。

作为一个建议,在运行任何CLI命令时,尝试使用_-dry-run参数_。这是一个阻止自己把事情搞砸的好方法。欲了解更多信息,请参考。
可扩展的代码和关注点的分离
在工作中,我通常在谈论可扩展性。这与使应用程序变得更大,或能够处理巨大的工作负载有关,只是与此有关。一个可扩展的应用程序可以被理解为一个可以毫无问题地响应许多请求的应用程序,并且可以被扩展,这意味着它可以被复制以提高可靠性和性能。它还意味着你可以使你的应用程序在代码中增长,增加新的功能,而不损害已经存在的代码。我的这个定义也许非常错误)。
理论上,所有好的代码都应该是可扩展的(理论上......在纸上一切看起来都很美)。
那么 "好的代码 "是什么样子的呢?
进入SoC,或称关注点分离(sepparation of concerns)。但在这之前,让我告诉你一些不好的代码,类似于我在迁移过程中的一些悲惨发现。我主要是在一些后端项目中发现了这些代码犯罪行为。
让我们假设我们有一个REST API,和一些检索完整用户列表的路由。使用公司使用的相同技术栈(Express、Sequelize和其他东西),代码应该是这样的。
import express from 'express';import { userController } from 'user.controller';
请注意,我跳过了所有的认证中间件,或任何其他的路由、函数或其他(再次,为我们的例子简单化)。
user.controller文件可能是这样的。
import { Request, response } from 'express';import { user } from '@mine/db-models';
乍一看,一切都很好。但是。
- 如果我告诉你,你需要改变很多额外的逻辑呢?
- 如果我告诉你,这些额外的验证需要连接到其他地方呢?
- 如果我告诉你,我们不再使用Sequelize了呢?
所有的_"如果 "_列表都需要编辑代码,做一些调整,让事情在新的要求下运行。问题不在于必须修改一些代码(事实上,我们应该为此得到报酬),问题是如果retrieveUserList 函数有几百行,这个控制器将很快变得绝对不可维护。让我们这样说吧,一个100多行的控制器函数很可能_没有任何_文档或评论或任何可以帮助任何开发人员处理这个意大利面条沙拉的东西。
所以让我们再想想我们到底应该怎么做。
- 获取请求
- 应用额外的逻辑
- 进行验证
- 检索用户列表(从数据库)。
- 返回用户列表(响应
正如你所看到的,所有这些操作都可以被清楚地识别出来,尽管它们之间确实有一些关系,但它们可以由自己来实现。这种方法有几个优点。
- 你可以重复使用这些逻辑。(黑体字表示_很重要_)
- 你不需要为了改变一些代码而修改一个非常难以管理的文件。
- 每个文件都有一个单一的责任(理想情况下
所以,一个编码良好的控制器会知道它必须解决一些问题,但是......它不应该知道如何解决这些问题。

这背后的主要想法是,你所有的代码应该像乐高积木一样工作。如果你需要替换一块砖头(比方说一个做 "什么"的服务),你只需要它的形状和大小相匹配。
所以,重写我们的例子。
路线文件保持不变,没有任何问题。但是控制器文件。
import { Request, response } from 'express';import { user } from '@mine/db-models';import { UserDataService } from './user.service';import { UserValidationService, RequestHeaders } from './user-validation.service';import { CompanyUserQueryService } from './company-user-query.service';import { ErrorResponse } from '@mine/backend-utils';
我有一点创意,为额外的逻辑和验证部分添加了一些函数调用。试着想象一下,如果所有的逻辑都在控制器上实现,代码会有多糟糕(如果你的想象力不像我一样被咖啡因驱动,那就提示一下,代码太多行了)......
所以,我们重写了我们的例子,好吧,不是真的,我们只是把它分离在几个服务上,重构了代码,让每个服务处理自己的责任_(单一责任原则_)。代码变得更短,因为它不包括控制器中的所有内部业务逻辑。
为了更好地理解这种代码重构,试着把这些点当作编码规则来思考。
- 一个_API_端点必须解决一个需求
- 一个需求可能是一个简单或复杂的任务
- _API_端点的控制器必须知道它要做什么,但它不需要知道如何做。
- 控制器必须导入/要求/使用尽可能多的服务来解决它所要解决的问题。
- 一个服务知道如何解决事情(这里有一个很好的实现)。
我对这些特殊要求的编码方式遵循一定的编码模式(伪代码),我把数字放在应该执行的步骤或代码块的序列上。
function requirement (parameters): return something { // 1. capture and parse any parameters (can use functions // in the same controller) // 2. validate parameters (can use functions in the same // controller) // ... now a same item that can change depending on // the requirement // 3. apply extra internal logic // 3. apply validations logic // 3. retrieve information from some source // 4. return something}
如果这些步骤中的任何一个可以用其他东西代替,那么这就是一个很好的指针,它应该被实现为一个服务。否则,控制器中的一个内部函数就足够了。不要忘了,即使你知道你的应用程序的一些内部功能不会随着时间的推移而改变,如果你认为它可能会改变,那么最好将它分离到不同的服务中。在一个理想的情况下,所有的服务都是可以替换的,就像乐高积木一样,应该是可以替换的。
当使用Typescript时,我实现的大多数服务都试图实现一个接口,它定义了所有的服务变量、函数签名,意味着它们的参数(和它们的类型),以及每个函数的响应类型。例如,function retrieveUserList() ,连接到_PostgreSQL_或_MongoDB_或文件存储并不重要,如果内部实现需要不同的库来实现与数据存储库的连接也不重要。真正重要的是,在每个服务实现中,retrieveUserList 接收_零_参数并返回一个Promise<Array<User>> 。
这在一开始似乎有点难以处理,但当你的经理决定从PostgreSQL迁移到MongoDB,而你发现你必须重写整个控制器时,你终于明白,在许多小文件上工作,解决自己的责任,比在一个巨大的文件上工作,在里面实现所有的东西要好得多。
...最后
测试和文档
根据我的经验,测试和文档并不是开发者最喜欢的东西。但它们确实有很大的帮助。
许多正式的QA专家和测试人员会讨厌这一点,但测试并不一定要成为一个带有断言的规格。它只需要覆盖边缘情况,并显示它做了它应该做的事情,当然还要做得好。尽管你已经读了我的前一段话,但最好还是使用测试框架来做你的测试。现在(IMHO)Jest是统治现场的测试框架,所以看看它并试一下吧。
还有文档。我来自Java背景,JavaDocs是我相当喜欢的一个东西。只需添加/** ,然后按下Enter 键,一个文档骨架就被添加到你的类方法中。VS Code,作为我目前的基本IDE,有类似JavaDoc的东西,也有不止几个JsDoc插件。
我在不止一个地方读到过_"好的代码自己会说话,不需要文档"。_只有当所有的开发者都用同样的剪刀剪开时,我才会相信这句话。没有人和其他人是一样的,所以你的学习和理解速度可能和其他队友有很大不同。而代码就是一个完美的例子。作为一个例子。
gb(xs: any, f: any) { return xs.reduce((r: any, v: any, i: any, a: any, k: any = f(v)) => ((r[k] || (r[k] = [])).push(v), r), {});}
几乎完全不能理解。而且要好得多(同样的代码,稍作调整)。
/** * GroupBy function * From: You Dont Need Lodash Underscore * Ref. https://github.com/you-dont-need/You-Dont-Need-Lodash-Underscore#_groupby * @param xs original array of JSON objects meant to be grouped * @param f grouping field name * @returns new JSON object with the grouped data */ groupBy(xs: any, f: any) { return xs.reduce((r: any, v: any, i: any, a: any, k: any = f(v)) => ((r[k] || (r[k] = [])).push(v), r), {}); }
这里仍然有一些黑魔法,但至少它解释了这个函数的作用。作为一个很好的练习,你可以改进这个函数的类型 :)
不要忘记,你(通常)不是为自己编码,而是为你的队友,甚至是你未来的自己。就我而言,当我在几个星期后回到我自己的代码时,我非常感激我所写的任何有用的评论,而当我面对我自己的无文档的神秘代码时,我真的恨我自己。所以道理是。写下有用的注释。
例如,还记得function requirement 伪代码上的编号项目吗?我通常会留下这些,因为,了解我的编码风格,有很大的机会面对一块巫师拼写的代码行,它能完成大部分的魔法。
就这样吧,如果你能坚持到这一步而没有睡着的话,谢谢你的阅读。并一如既往地欢迎评论、提问和鼓掌(如果你喜欢的话:))。
保持安全。
