译/ 阿里淘系商家团队 - 革新
本文是技术文章《From Perceptron to Deep Neural Nets》的翻译和补充。发布者:Adi Chris
作为一名机器学习工程师,我从事深度学习已经有一段时间了。现在,在完成Coursera的所有Andrew NG最新的深度学习课程之后,我决定将对这一领域的一些了解放到博客文章中。我发现写下来是解决主题的有效方法。此外,我希望这篇文章对想开始深度学习的人可能有用。
好了,让我们谈谈深度学习。哦,等等,在我直接谈论深度学习或深度神经网络(DNN)是什么之前,我想通过介绍一个简单的问题来开始本文,我希望它可以使我们对为什么需要有一个更好的直觉(深度)神经网络。 顺便说一句,我还将与这篇文章一起在Github上发布代码,使您可以训练一个深度神经网络模型来解决下面的XOR问题。
异或问题
“异或”问题是给定两个二进制输入的问题,我们必须预测“异或”逻辑门的输出。提醒一下,如果两个输入不相等,则XOR函数应返回1,否则返回0。下表1列出了XOR功能的所有可能的输入和输出:
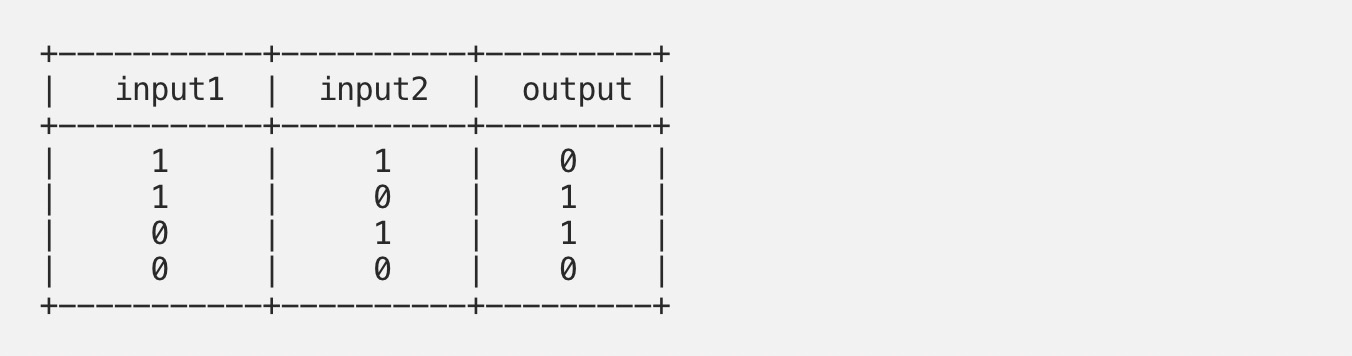
现在,让我们绘制数据集,看看数据的性质如何。
def plot_data(data, labels):
"""
argument:
data: np.array containing the input value
labels: 1d numpy array containing the expected label
"""
positives = data[labels == 1, :]
negatives = data[labels == 0, :]
plt.scatter(positives[:, 0], positives[:, 1],
color='red', marker='+', s=200)
plt.scatter(negatives[:, 0], negatives[:, 1],
color='blue', marker='_', s=200)
positives = np.array([[1, 0], [0, 1]])
negatives = np.array([[0, 0], [1, 1]])
data = np.concatenate([positives, negatives])
labels = np.array([1, 1,

也许看到上面的图之后,我们可能想重新考虑这个xor问题是否确实是一个简单的问题。 如您所见,我们的数据不是线性可分离的,因此,一些著名的线性模型(如逻辑回归)可能无法对我们的数据进行分类。 为了让您更清楚地理解,下面我绘制了使用非常简单的线性模型构建的一些决策边界:
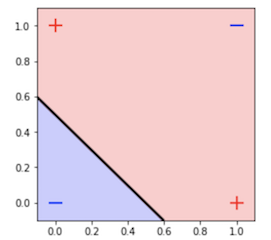
看到上面的图,很明显,我们需要一个对非线性可分离数据运行良好的分类器。 具有内核技巧的SVM可能是一个不错的选择。 但是,在本文中,我们将改为构建神经网络,并查看该神经网络如何帮助我们解决XOR问题。
什么是神经网络?
神经网络或人工神经网络是一个非常好的函数近似器,它宽松地基于人们认为大脑工作的方式。 下面的图显示了人类生物神经元和人工神经网络之间的类比。
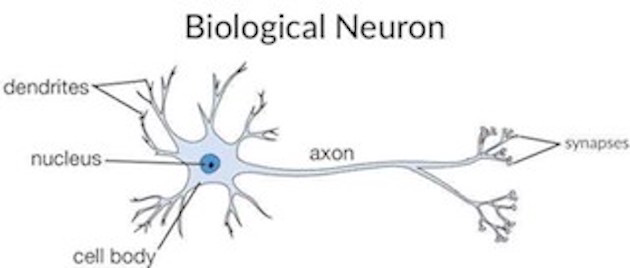
在不深入讨论生物神经元的情况下,我将对生物神经元如何处理信息进行高层次的直观介绍。 我们的神经元通过树突接收信号。然后,这些信息或信号会传递到Soma或细胞体。在单元体内,所有信息将被汇总以生成输出。当总和结果达到阈值时,神经元将触发,信息将通过轴突传递下来,然后通过其突触传递到其他连接的神经元。神经元之间传输的信号量取决于连接的强度。
整个上述流程是由人工神经网络采用的。您可以将树突视为基于人工神经网络中突触互连的加权输入。然后,将加权后的输入汇总到人工神经网络的“单元体”中。如果生成的输出大于阈值单位,则神经元将“触发”,并且该神经元的输出将被传递到其他神经元。 因此,您可以看到ANN是使用基本生物神经元的工作建模的。
那么,这个神经网络如何工作?
为了了解该神经网络的工作原理,让我们首先来看一个非常简单的人工神经网络,称为Perceptron。 对我而言,Perceptron是机器学习中存在的最优雅的算法之一。 这个简单的算法创建于1950年代,可以说是机器学习算法如此重要的发展的起点,例如逻辑回归,支持向量机甚至是深度神经网络。 那么感知器如何工作? 我们将使用下图所示的图片作为讨论的起点。
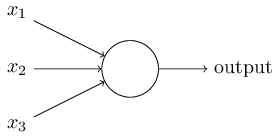
上图显示了具有三个输入x1,x2和x3的感知器算法,以及一个可以生成输出值的神经元单元。 为了生成输出,Rosenblatt通过引入权重的概念引入了一条简单的规则。 权重基本上是实数,表示各个输入对输出的重要性[1]。 上面描述的神经元将生成两个可能的值0或1,并由每个输入的加权和∑ wjxj小于还是大于某个阈值来确定。 因此,感知器算法的主要思想是学习权重w的值,然后将权重w与输入特征相乘以决定神经元是否触发。 我们可以使用如下所示的数学表达式来编写它:
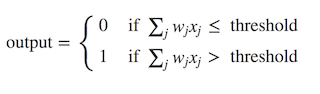
现在,我们可以通过做两件事来修改上面的公式:首先,我们可以将加权和公式转换为两个向量w(权重)和x(输入)的点积,其中w⋅x≡∑wjxj。 然后,我们可以将阈值移到不等式的另一端,并用一个新的变量来代替它,称为偏差b,其中b≡-threshold。 现在,通过这些修改,我们的感知器规则可以重写为:
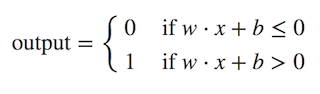
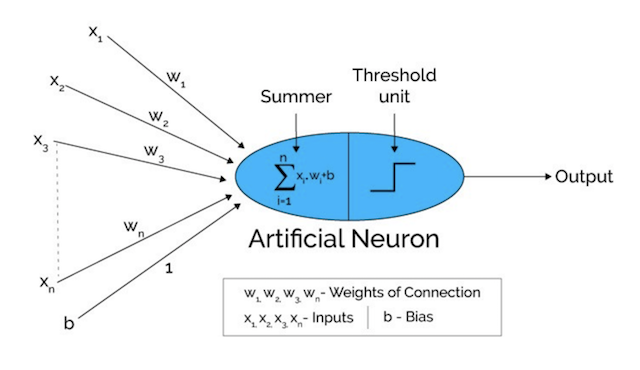
现在,当我们将所有内容放回到感知器架构上时,我们将为单个感知器提供完整的架构,如下所示:
典型的单层感知器将Heaviside阶跃函数用作激活函数,以将结果值转换为0或1,从而将输入值分类为0或1。如下图所示,Heaviside阶跃函数将为负输出零。 论证和一个积极的论证。
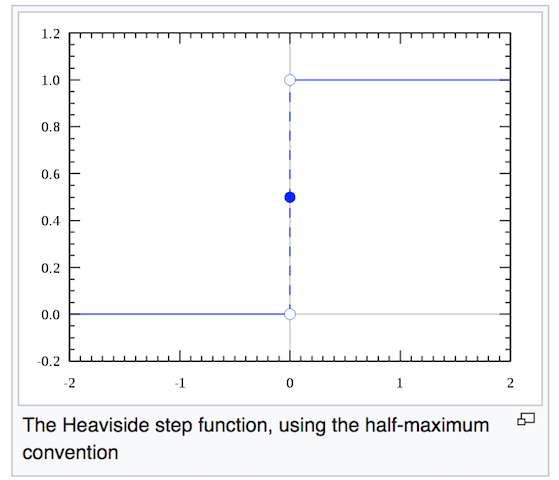
如果输入数据是线性可分离的,则Heaviside阶跃函数在分类任务中特别有用。但是,回想一下,我们的目标是找到一个在非线性可分离数据中运行良好的分类器。因此,无论是单层感知器还是Heaviside阶跃函数在这里都毫无意义。稍后,如您在下一节中所看到的,我们将需要一个由多个感知器以及一个非线性激活函数组成的多层。
具体来说,有两个主要原因导致我们无法使用Heaviside步进函数:
- 目前,训练多层神经网络的最有效方法之一是将梯度下降与反向传播结合使用(我们将在短期内讨论这两种方法)。反向传播算法的要求是可微分的激活函数。但是,Heaviside阶跃函数在x = 0时不可微,在其他位置导数为0。这意味着梯度下降将无法在权重更新方面取得进展。
- 回想一下,神经网络的主要目标是学习权重和偏差的值,以便模型可以产生尽可能接近实际值的预测。 为此,就像许多优化问题一样,我们希望权重或偏差发生小的变化,从而仅导致网络输出的相应变化很小。 拥有只能生成0或1(或“是”和“否”)的函数,将无法帮助我们实现此目标。
激活函数
激活功能是神经网络中最重要的组件之一。 尤其是,非线性激活函数是必不可少的,至少出于以下三个原因:
- 它可以帮助神经元学习和理解真正复杂的事物。
- 它们为我们的网络引入了非线性特性。
- 我们希望重量的微小变化仅引起网络输出的相应微小变化。
我们已经看到,Heaviside阶跃函数是激活函数的一个示例,不过,在本特定部分中,我们将探讨深度学习社区中通常使用的几种非线性激活函数。 顺便说一句,可以在Avinash Sharma和Karpathy撰写的这两篇精彩文章中对激活函数进行更深入的解释,包括每个非线性激活函数的优缺点。
Sigmoid Function
S形函数,也称为逻辑函数,是给定输入的函数,它将生成范围为(0,1)的输出。 sigmoid能写为:

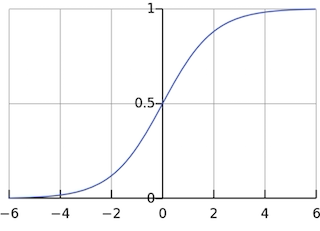
上图绘制了S型函数的形状。 如您所见,它就像是Heaviside步进函数的平滑版本。 但是,由于许多因素,因此首选S型函数:
- 它本质上是非线性的。
- 现在,我们不再有输出0和1的功能,而是可以给输出值0.67的函数。 是的,您可能会猜到,它可以用来表示概率值。
- 仍然与第(2)点相关,现在我们的激活范围被限制在一个范围内,这意味着它不会炸毁这些激活。
但是,S型激活函数有一些缺点: 消失的梯度。 从上图可以看到,当函数的输入值z很小(朝-inf方向移动)时,S型函数的输出将接近于零。 相反,当z很大时(朝+ inf方向移动),S型函数的输出将接近1。那么,这意味着什么呢? 在该区域,梯度将非常小,甚至消失。 消失的梯度是一个很大的问题,尤其是在深度学习中,因为我们将多层这种非线性叠加在一起,因为即使第一层的参数发生很大的变化也不会改变输出。 换句话说,网络拒绝学习,并且训练模型所需的时间通常会越来越慢,尤其是在使用梯度下降算法的情况下。 sigmoid激活函数的另一个缺点是计算指数在实践中可能很昂贵。 尽管可以说,与矩阵乘法和/或卷积相比,激活函数只是深层网络中计算的很小一部分,所以,这可能不会成为一个大问题。 但是,我认为值得一提。
Tanh Function
Tanh或双曲正切是深层神经网络中常用的另一种激活函数。 该函数的性质与Sigmoid函数非常相似,在Sigmoid函数中,它将输入压缩为一个很好的有界范围值。 具体来说,给定一个值,tanh将生成一个介于-1和1之间的输出值。
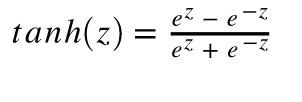
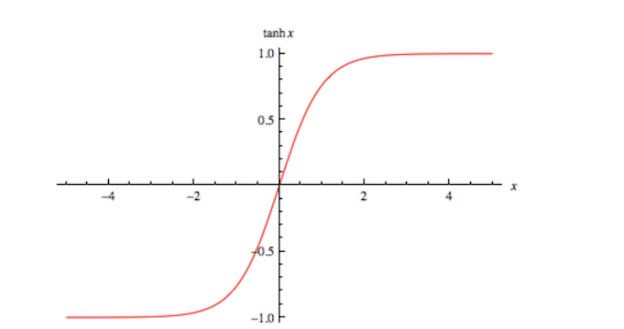
如前所述,tanh激活函数具有类似于S型函数的特性。 它是非线性的,并且绑定到某个范围,在这种情况下为(-1,1)。 同样,不足为奇的是,tanh具有与S型一样的缺点。 它遭受梯度消失的困扰,从数学公式中可以看出,我们需要计算指数,这通常在计算上效率低下。
ReLu (Rectified Linear Unit)
这就是ReLu,它是一种激活功能,预期不会比Sigmoid和tanh更好,但是实际上,它确实可以做到! 实际上,该讲座默认说使用ReLU非线性。 ReLu具有很好的数学特性,在计算上非常高效。 给定输入值,如果输入小于0,则ReLu将生成0,否则输出将与输入相同。 从数学上讲,这是ReLu函数的形式。
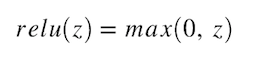
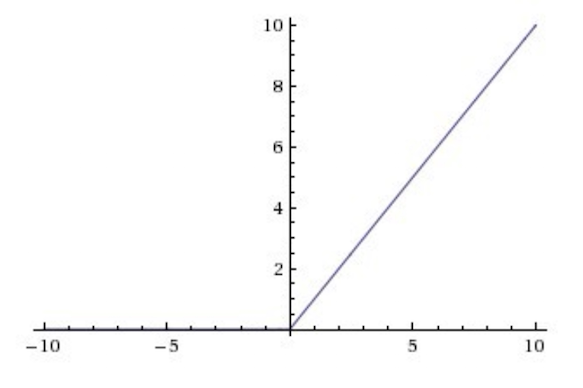
现在,您可能会问:“这不是线性函数吗? 为什么我们将ReLu称为非线性函数?” 首先,让我们首先了解什么是线性函数。 维基百科说:
In linear algebra, a linear function is a map f between two vector spaces that preserves vector addition and scalar multiplication: f(x + y) = f(x) + f(y) f(ax) = af(x)
给定上面的定义,我们可以看到max(0,x)是分段线性函数。 这是分段的,因为只有当我们将其域限制为(-inf,0]或[0,+ inf)时,它才是线性的。 但是,它在整个域上不是线性的。 例如:
f(−1) + f(1) ≠f (0)
因此,现在我们知道ReLu是一个非线性激活函数,它具有良好的数学特性,并且与S型或Tanh相比,计算效率更高。此外,众所周知,ReLu可以“消除”梯度消失的问题。但是,ReLu有一个很大的缺点,那就是“垂死的ReLu”。垂死的ReLu是一种现象,其中网络中的神经元由于无法向前发射而永久死亡。
更准确地说,当神经元在向前通过时生成的激活值为零时,会发生此问题,从而导致其权重将变为零梯度。结果,当我们进行反向传播时,该神经元的权重将永远不会更新,并且特定神经元也将永远不会被激活。我强烈建议您观看本讲座视频,其中对这个特定问题以及如何避免即将死去的ReLu问题进行了更深入的说明。请去检查一下!
哦,关于ReLu的另一件事我值得一提。您可能会注意到,与S型和tanh不同,ReLu不会限制输出值。由于这通常可能不会成为一个大问题,因此在诸如递归神经网络(RNN)之类的深度学习模型的另一个变体中,它可能会变得麻烦。具体而言,由ReLu生成的无穷大值可能会使RNN中的计算在没有合理权重的情况下可能爆炸到无穷大。结果,学习可能会非常不稳定,因为在反向传播过程中,权重在错误方向上的轻微移动会破坏正向传递过程中的激活。
神经网络如何预测和学习?
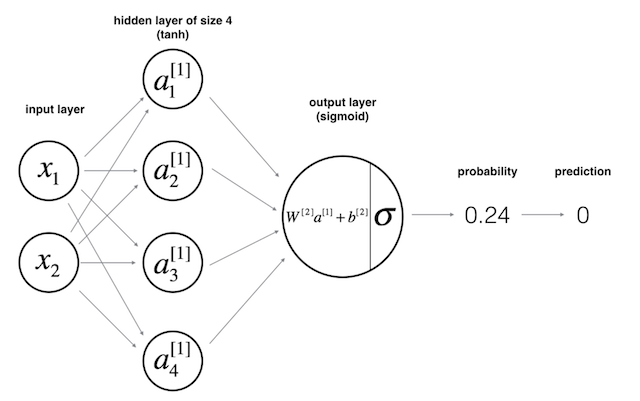
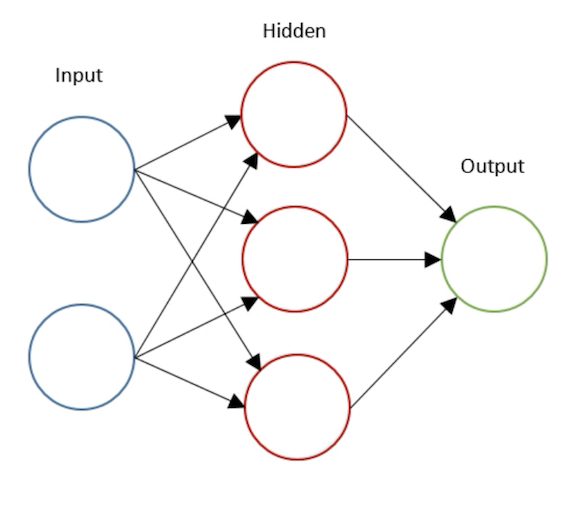
上图中描述的体系结构称为多层感知器(MLP)。顾名思义,在MLP中,我们将多个感知器简单地堆叠为几层。上面描述的是一个具有3层的网络:输入层,隐藏层和输出层。但是,在深度学习或神经网络社区中,人们并不将此网络称为三层神经网络。通常,我们只计算隐藏层的数量或隐藏层的数量以及输出层,因此是两层神经网络。隐藏层仅表示输入层或输出层。现在,正如您可能猜到的那样,深度学习一词仅表示,我们有“更多”隐藏层:)。 那么神经网络如何产生预测呢?
神经网络在使所有输入通过所有层直到输出层之后,会生成预测。此过程称为前馈。从上图中可以看到,我们用输入x来“馈送”网络,计算激活函数并将其逐层传递,直到到达输出层。在监督设置任务(例如分类任务)中,我们通常在输出层中使用S型激活函数,因为我们可以将其输出转换为概率。在上图中,我们可以看到输出层生成的值为0.24,并且由于该值小于0.5,因此可以说预测y_hat为零。 然后,像典型的分类任务中一样,我们将有一个成本函数,该函数可衡量模型逼近真实标签的程度。实际上,在神经网络中进行训练只是意味着尽可能地降低成本。我们可以定义成本函数如下:
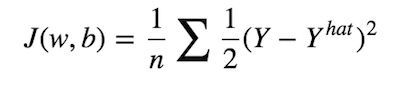
因此,目标是找到w和b的某种组合,以使我们的成本J尽可能小。 为此,我们将依靠两种重要的算法:梯度下降和反向传播。
梯度下降算法
对于那些一直在进行机器学习的人来说,他们可能已经了解梯度下降算法。 训练神经网络与使用梯度下降训练任何其他机器学习模型没有太大区别。 唯一显着的差异是我们网络中的非线性影响,这会使我们的成本函数变得不凸。 为了提供更好的直觉,让我们假设我们的成本函数是一个凸函数(一个大碗),如下图所示:

在上图中,水平轴表示我们的参数,权重和偏差的空间,而成本函数J(w,b)则是水平轴上方的某个表面。上图中的红色圆圈是我们的成本减去权重和偏差后的原始值。为了最大程度地降低成本,我们现在知道必须走到最陡峭的道路。但是问题是,我们如何知道要朝哪个方向走?我们应该增加还是减少参数的值?我们可以进行随机搜索,但是这将花费很长时间,并且显然在计算上也很昂贵。 在调整可学习的参数,权重和偏见时,有更好的方法来找到应该走的方向。微积分告诉我们,梯度矢量的方向在给定点上自然会指向最陡的方向。因此,我们将使用成本函数的梯度,而不考虑权重和偏差。 现在,让我们通过只看权重的成本来简化事情,如下面的图所示。

将我们的成本函数w.r.t的值表示为权重的值。 您可以将上面的黑色圆圈视为我们的原始费用。 回想一下,函数或变量的梯度可以为正,零或负。 负斜率表示直线向下倾斜,反之亦然。 现在,由于我们的目标是使成本最小化,因此我们需要将权重沿成本函数的梯度的相反方向移动。 此更新过程可以编写如下:
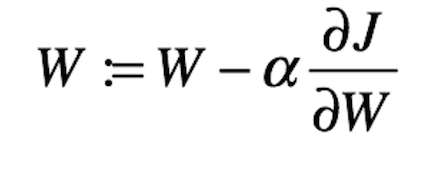
其中α是步长或学习率,我们将其乘以成本的偏导数乘以可学习的参数。 那么,α的作用是什么? 好吧,梯度告诉我们函数具有最陡峭速率的方向,但是,它没有告诉我们应沿该方向走多远。 这是我们需要的α,它是一个基本控制步长的超参数,例如,我们应该朝某个方向移动多少。 为学习率选择合适的值非常重要,因为它将极大地影响两件事:学习算法的速度以及我们是否可以找到局部最优(收敛)。 在实践中,您可能希望使用自适应学习率算法,例如动量,RMSProp,Adam等。 来自AYLIEN的一个人写了一篇非常不错的文章,内容涉及各种优化和自适应学习率算法。
Backpropagation
在上一节中,我们讨论了梯度下降算法,这是一种优化算法,我们将其用作深度神经网络中的学习算法。 回想一下,使用梯度下降意味着我们需要找到成本函数w.r.t和我们可学习的参数w和b的梯度。 换句话说,我们需要计算成本函数w.r.t w和b的偏导数。 但是,如果我们观察到成本函数J(如下图12所示),则J与w和b之间都没有直接关系。
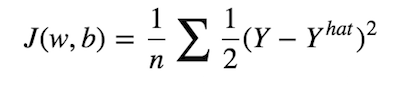
仅当我们从输出层(生成y_hat的层)追溯到输入层时,我们才会看到J与w和b都有间接关系,如下图13所示:
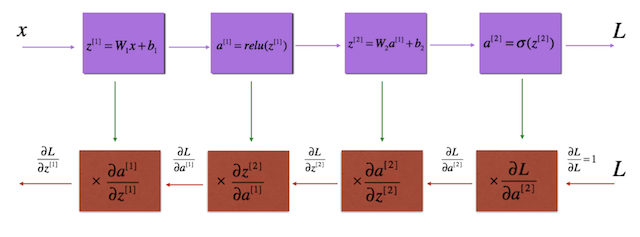
现在,您可以看到,为了找到w和b的成本的梯度,我们需要找到具有所有变量(例如a(激活函数)和z(线性计算的成本的偏导数:wx + b)。 这是我们需要反向传播的地方。 反向传播基本上是对微分的链式微积分法则的重复应用,我想这可能是在神经网络中找到所有学习参数的成本梯度的最有效方法。 在本文中,我将带您计算成本函数J w.r.t W2的梯度,该梯度是神经网络第二层的权重。 为简单起见,我们将使用图8所示的架构,其中我们有一个包含三个隐藏神经元的隐藏层。
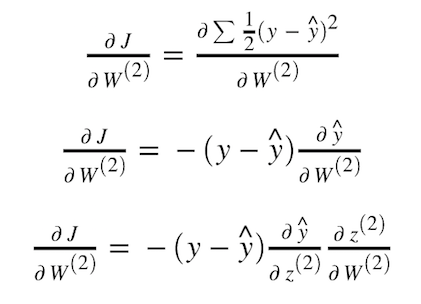
为了找到y_hat w.r.t z2的变化率,我们需要相对于z来区分S型激活函数。
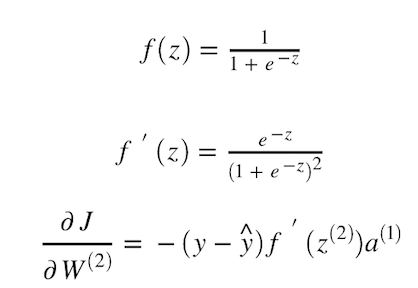
现在,一旦有了偏导数J w.r.t W2的值,就可以使用上一节中图11所示的公式更新W2的值。 基本上,我们将对所有权重和偏差重复执行相同的计算,直到获得尽可能小的成本值。
神经网络解决异或问题
好棒的! 我想我们已经涵盖了构建神经网络模型甚至深度学习模型所需的几乎所有知识,这将有助于我们解决XOR问题。 在撰写本文时,我建立了一个简单的神经网络模型,其中只有一个具有不同数量的隐藏神经元的隐藏层。 我使用的网络示例如下图所示。 另外,我介绍了我的模型使用不同数量的神经元生成的一些决策边界。 如您稍后看到的,我们可以说拥有更多的神经元将使我们的模型变得更加复杂,从而创建了更加复杂的决策边界。
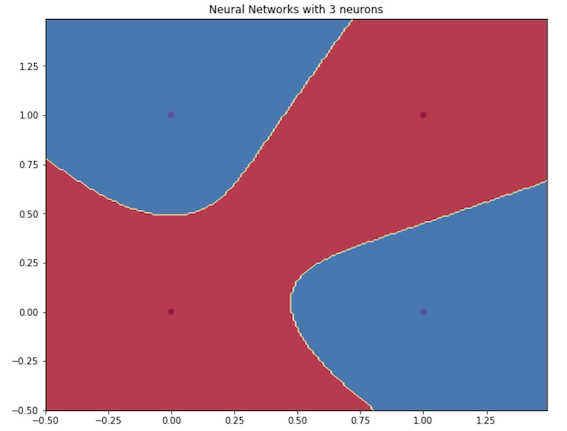
但是,什么是最佳选择?有更多的神经元或更深,这意味着有更多的层次? 从理论上讲,非常深的网络的主要好处是它可以表示非常复杂的功能。具体来说,通过使用更深的体系结构,我们可以学习许多不同抽象级别的特征,例如将边缘(在较低层)标识为非常复杂的特征(在较深层)。
但是,使用更深的网络在实践中并不总是有帮助的。训练更深的网络时,我们将遇到的最大问题是逐渐消失的梯度问题:非常深的网络经常会出现梯度信号迅速变为零的情况,从而使梯度下降的速度令人难以忍受。
更具体地说,在梯度下降过程中,当我们从最后一层反向传播回第一层时,我们在每一步上都乘以权重矩阵,因此,梯度可以快速指数下降到零,或者在极少数情况下,可以快速指数增长和“爆炸”取非常大的值。
因此,为结束这篇冗长的文章,以下是一些要点,可以简要总结一下:
-
直觉的神经网络将非线性引入模型,可用于求解复杂的非线性可分离数据。
-
Perceptron是一种优雅的算法,为机器学习(包括深度学习)中许多最先进的算法提供了动力。
-
直观地,深度学习意味着使用具有更多隐藏层的神经网络。当然,它有很多变体,例如卷积神经网络,递归神经网络等等。
-
激活函数是神经网络中非常重要的组成部分,是的,您应该了解它。
-
目前,反向传播的梯度下降是我们用来训练(深度)神经网络的最佳组合。
-
拥有更多的隐藏层并不一定会改善我们模型的性能。实际上,它遭受了一个众所周知的问题,即消失梯度问题。
淘系前端-F-x-Team 开通微博 啦!(微博登录后可见)除文章外还有更多的团队内容等你解锁🔓